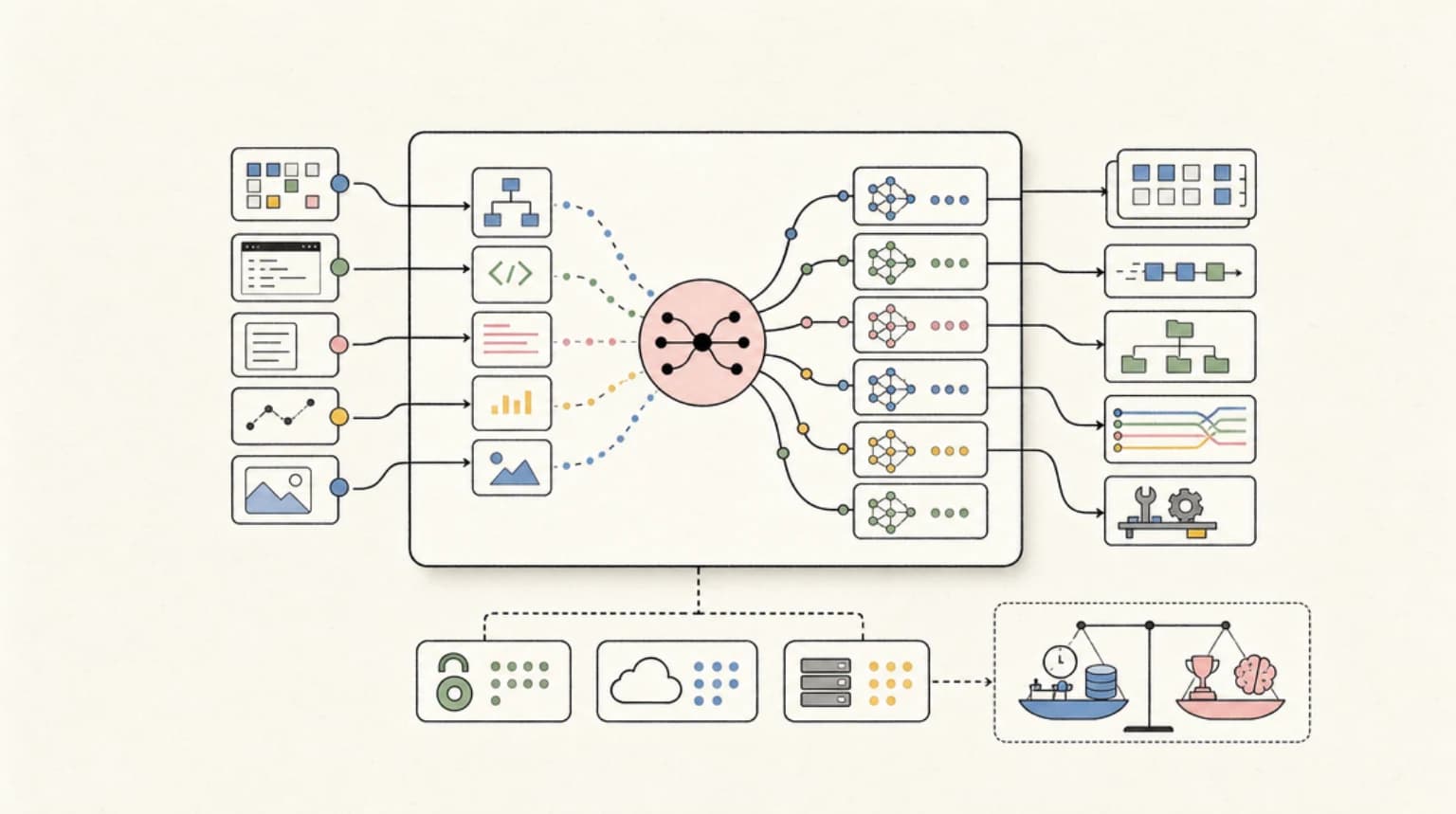
The Router Era: Why Not Owning a Frontier Model Became an Advantage
11 min read
Exploring Google's Advanced Gemma 2 AI Models and Exciting Updates In this video, I delve into Google's newly released Gemma 2 AI models, including the 9 billion and 27 billion parameter versions. I highlight the impressive performance of the 27 billion parameter model, which outperforms other leading models like LLAMA 3 70B and Cloud 3 Sonnet in the Chatbot Arena ELO. I also discuss their availability on Hugging Face, Olama, and Google Cloud, including their compatibility and deployment options. Additionally, I cover the new 2.6 billion parameter model and various user-friendly ways to try these models through AI Studio. Finally, key updates and features of the Gemini 1.5 Pro model, including a 2 million token context window and free code execution, are explored in detail. Stay tuned for more advancements in AI technology! 00:00 Introduction to Google's Gemma 2 00:05 Performance of the 27 Billion Parameter Model 01:43 Accessing and Running Gemma 2 02:13 Technical Specifications and Benchmarks 03:19 Recent Developments and Announcements 05:23 Gemini 1.5 Pro Model and Code Execution 06:52 Conclusion and Final Thoughts
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
Weekly deep dives on AI agents, coding tools, and building with LLMs - delivered to your inbox.
Free forever. No spam.
Subscribe Free
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.




