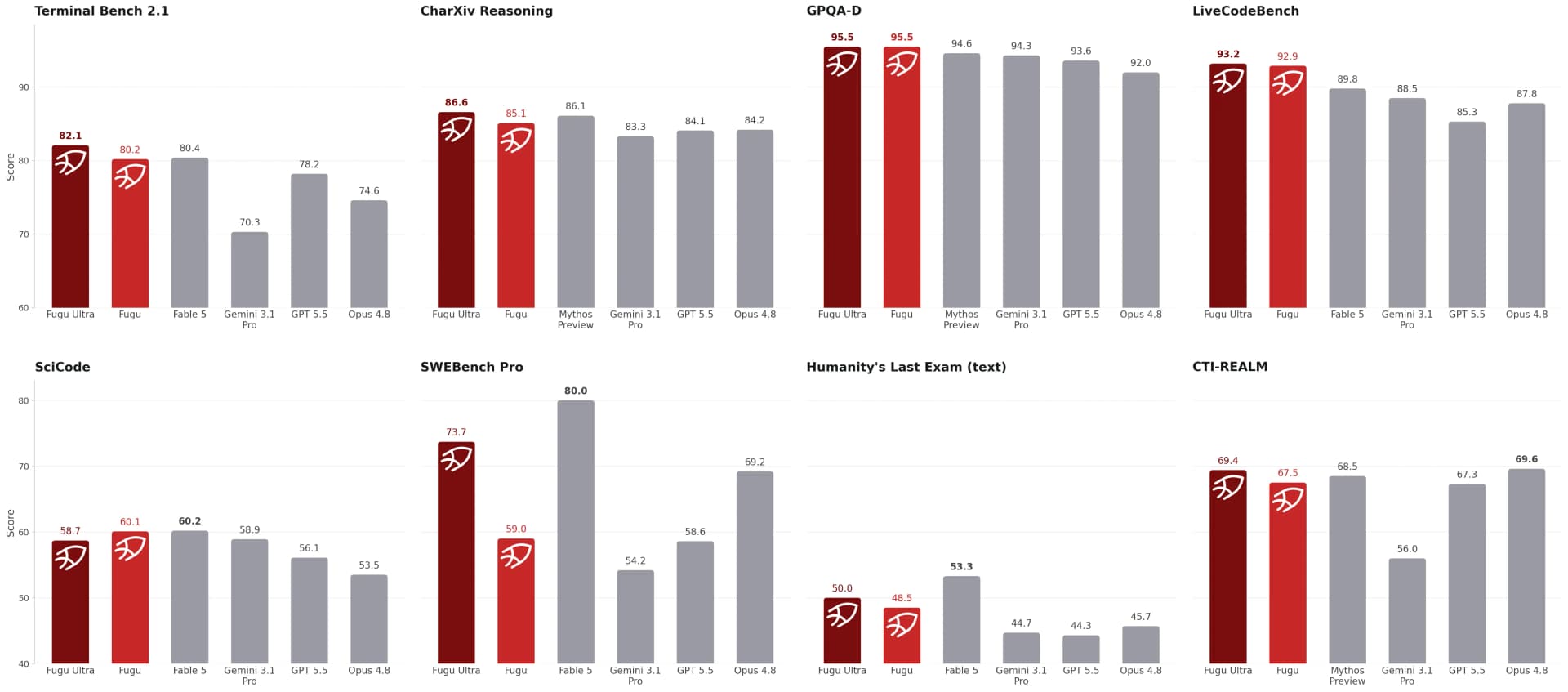
Fugu Ultra's Frontier Performance Claim, Explained Without the Hype
11 min read
Links: https://huggingface.co/spaces/HuggingFaceM4/idefics_playground https://huggingface.co/models?other=multimodal https://huggingface.co/blog/idefics https://huggingface.co/papers/2204.14198 https://huggingface.co/huggyllama/llama-65b https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K Multimodal Embeddings with Langchain in Node.js with Vertex.AI: https://www.youtube.com/watch?v=cxxEsCYt-C0 Patreon: https://patreon.com/developersdigest https://www.developersdigest.tech/
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
Weekly deep dives on AI agents, coding tools, and building with LLMs - delivered to your inbox.
Free forever. No spam.
Subscribe Free
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.

