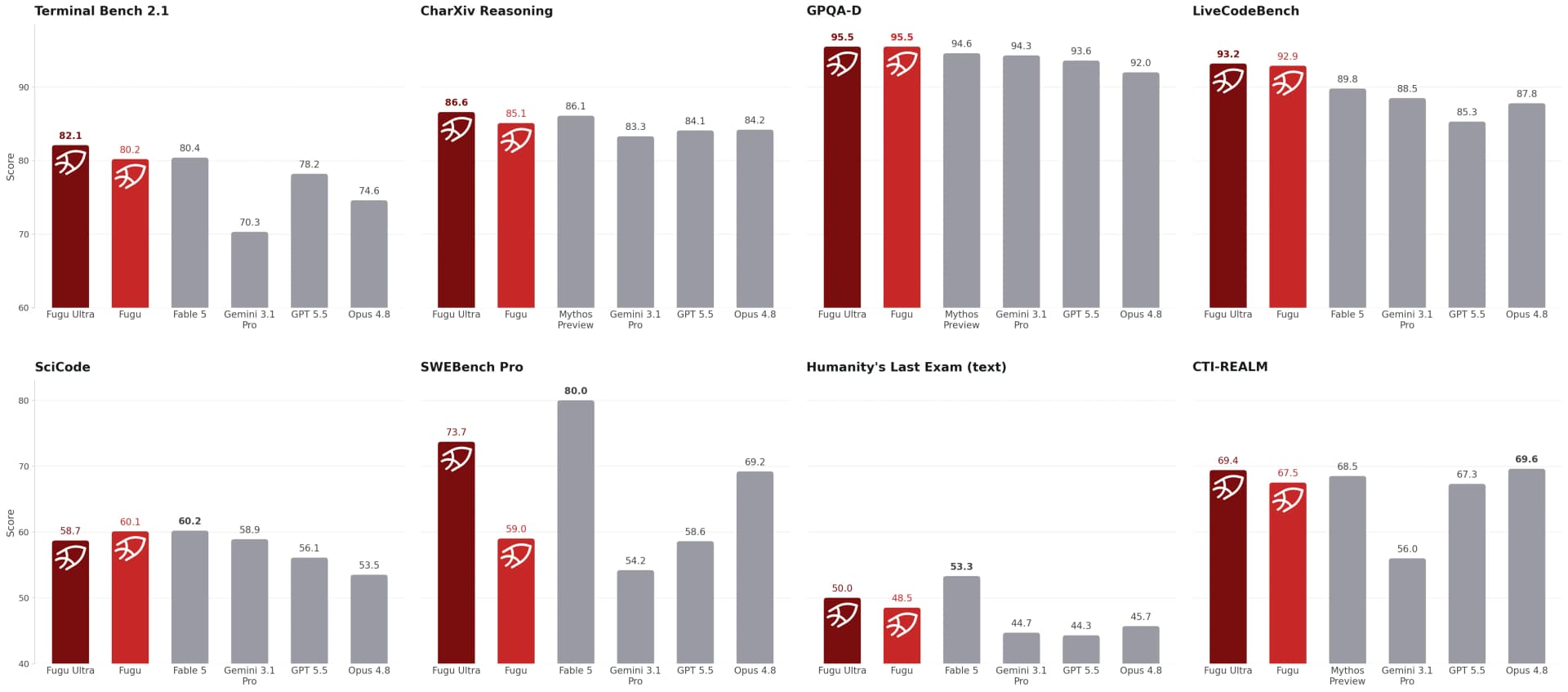
Fugu Ultra's Frontier Performance Claim, Explained Without the Hype
11 min read
In this video, I'll show you how to set up internet-enabled responses from LLMs using Serper, Firecrawl with dynamic model routing. We'll utilize a model router called Not Diamond to dynamically route queries to different models, including Anthropic, OpenAI, and Gemini. You'll learn to scrape web pages, handle embeddings with Langchain and OpenAI, and configure various APIs. I'll walk you through the entire setup process, including installing dependencies and creating the necessary routes and functions in TypeScript. By the end, you'll be able to create a flexible, context-aware LLM response system. Repo: https://github.com/developersdigest/internet-enabled-llms Links: https://www.firecrawl.dev/ https://serper.dev/ https://www.notdiamond.ai/ https://ai.google.dev/gemini-api https://www.anthropic.com/api https://openai.com/index/openai-api/ 00:00 Introduction to Internet-Enabled Responses 00:04 Setting Up the Tools 00:15 Model Routing with Not Diamond 00:26 Example Query: Chat GPT Canvas 00:51 Skipping Embeddings for Full Context 01:49 API Keys and Configuration 02:30 Installing Dependencies 03:17 Setting Up the API Route 04:07 Search Functionality with Serper 05:07 Scraping with Firecrawl 06:46 Embedding Setup and Optimization 07:53 Generating LLM Responses 08:25 Final Steps and Error Handling 10:00 Conclusion and Thanks
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
Weekly deep dives on AI agents, coding tools, and building with LLMs - delivered to your inbox.
Free forever. No spam.
Subscribe Free
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.




