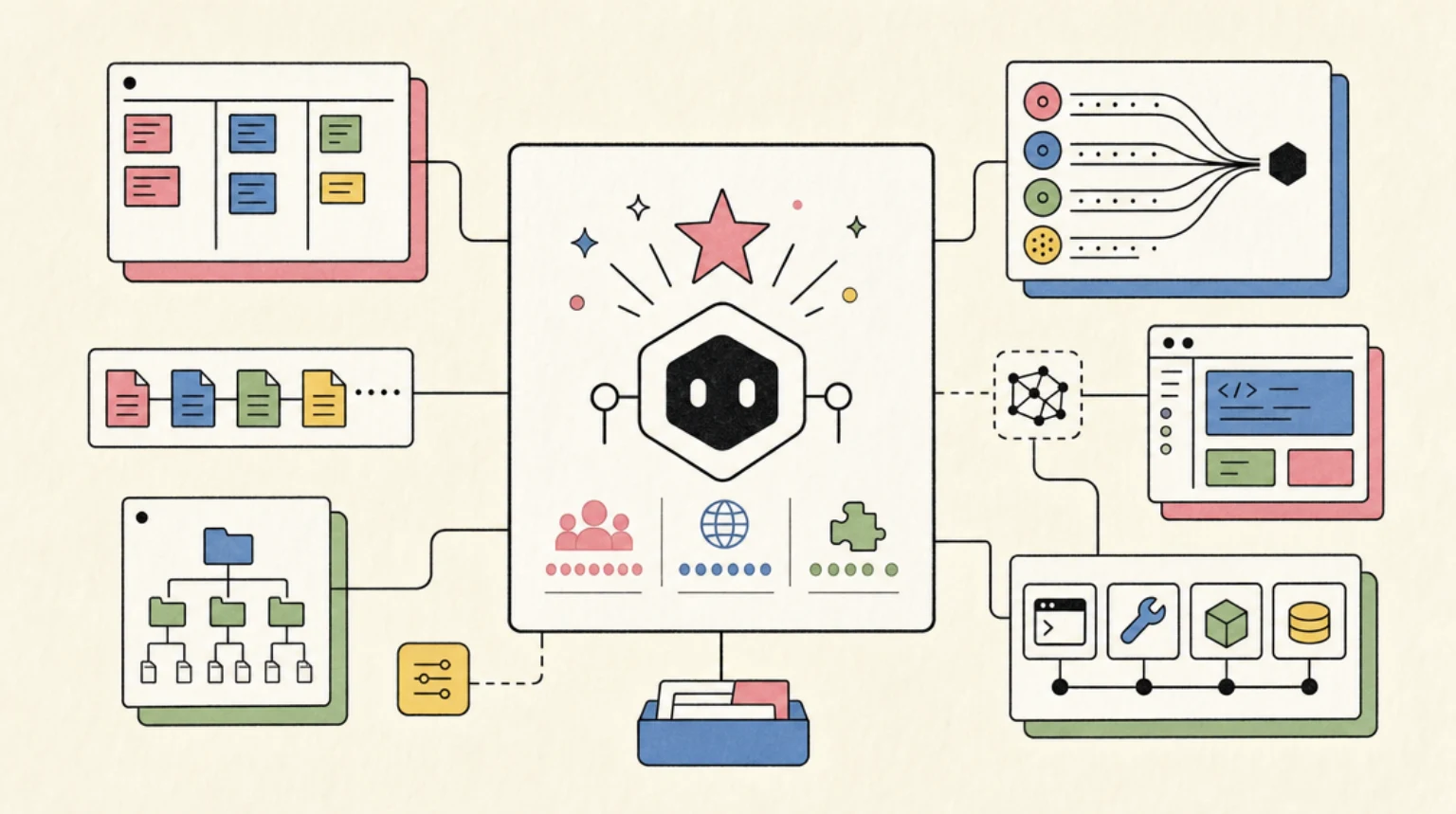
OpenCode Developer Guide: The Open Source AI Coding Agent with 160K Stars
11 min read
Weekly deep dives on AI agents, coding tools, and building with LLMs - delivered to your inbox.
Free forever. No spam.
Subscribe Free
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
Github ⭐ https://github.com/mendableai/fire-enrich Introducing Fire Enrich: Open Source Email Enrichment Tool Explained In this video, I'm thrilled to announce Fire Enrich, an open-source project that simplifies email enrichment. Fire Enrich allows users to drag and drop CSV files and automatically detects email columns. The tool filters common providers like Google, Proton Mail, and Yahoo and focuses on enhancing company-related information. Users can select fields like company name, industry, employee count, and funding information, among others. The back-end employs various agent strategies to gather data efficiently. Fire Enrich is highly extensible, allowing the addition of custom agents and proprietary APIs. The enriched data can be exported as CSV or JSON, and all data sources are transparently shown. The project is available on GitHub, complete with a detailed readme and a mermaid diagram of the agent architecture. This video demonstrates the tool's functionality, tech stack, and customization options. Be sure to star the repo, comment, share, and subscribe! 00:00 Introduction to Fire Enrich 00:02 Setting Up Your CSV for Enrichment 00:31 Filtering and Enrichment Options 00:51 Agent Strategies and Extensibility 01:29 Running an Enrichment Example 02:33 Viewing and Exporting Results 03:28 Additional Features and GitHub Resources 03:46 Tech Stack and Agent Orchestration 04:13 Conclusion and Call to Action
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.



