GLM-5.2
Everything on Z.ai's open-weights GLM-5.2 coding model: how to access it free and cheap, what it costs to run, how it stacks up against DeepSeek, Qwen, and the frontier labs, and why an MIT-licensed model is beating closed ones on real benchmarks.
5 articles44 min total read time
5 of 5 posts published
01

GLM-5.2 Developer Guide: Z.ai's 1M-Context Coding Model
Z.ai shipped GLM-5.2 in mid-June with a usable 1M-token context window, two thinking-effort levels, and MIT open weights now released. Here is the setup guide for Claude Code, pricing breakdown, and what to test before the benchmarks arrive.
8 min read|Read →
02
Where to Run GLM-5.2 Free and Cheap: Every Provider Compared (2026)
GLM-5.2 ships under an MIT license, so it is hosted everywhere - and a few places run it for free right now. Here is every way to access Z.ai's open-weights coding model, from free tiers in Devin and Hugging Face to the cheapest per-token routes on OpenRouter, Fireworks, and DeepInfra, plus local Ollama.
9 min read|Read →
03
GLM-5.2 Cost Math: When Open-Weights Coding Models Actually Save You Money
Z.ai's GLM-5.2 lands as a 753B open-weights coding model that beats GPT-5.5 on SWE-bench Pro for roughly one-sixth the per-token cost. Here is the real cost math, a worked cost-per-task example, and a when-to-use-which decision guide.
9 min read|Read →
04
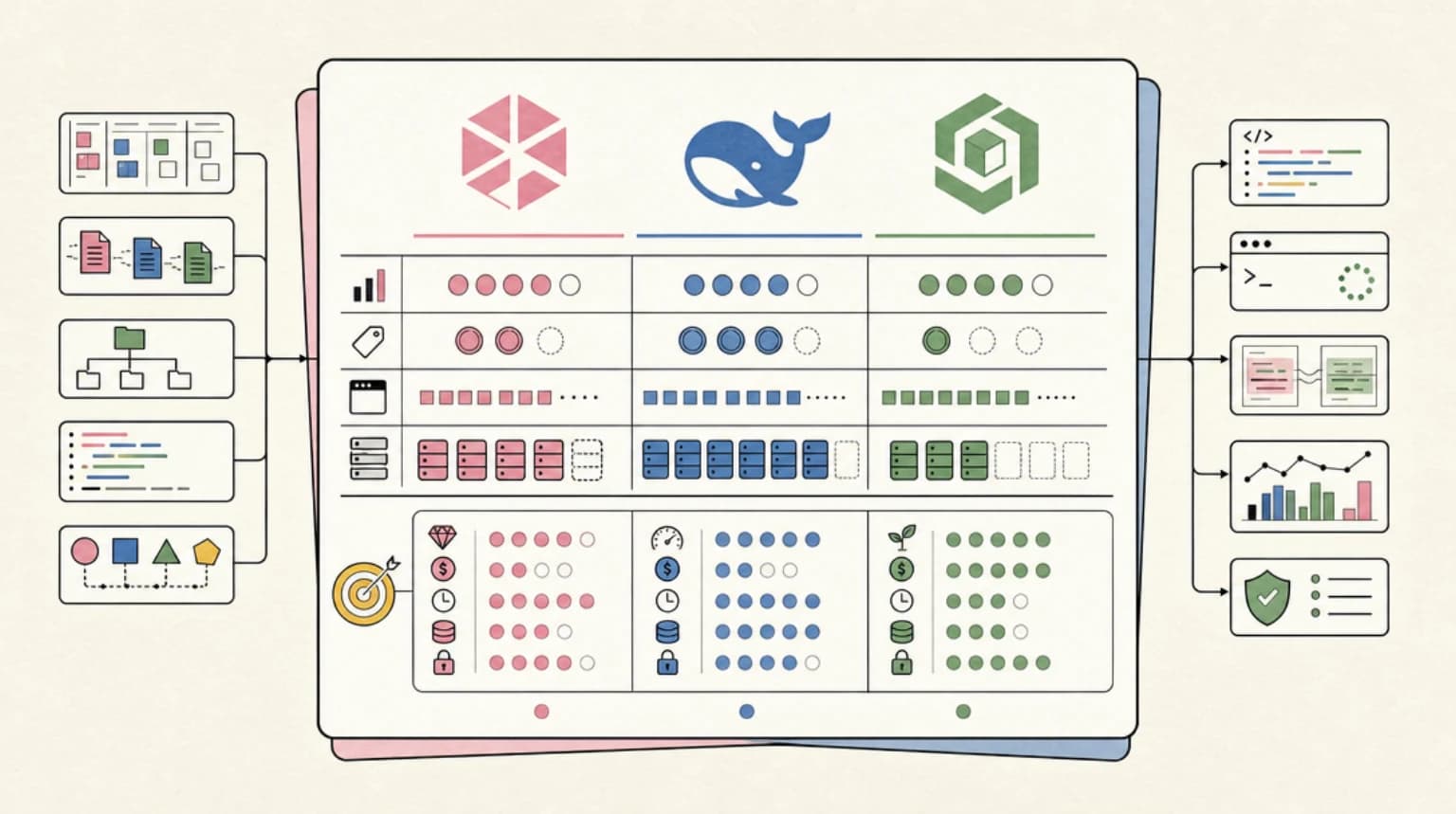
GLM-5.2 vs DeepSeek V4 vs Qwen3: The Open-Weights Coding Model Showdown (2026)
A data-rich, source-cited comparison of the three open-weights coding models that matter in 2026: GLM-5.2, DeepSeek V4, and Qwen3. Benchmark table, per-token pricing, context windows, self-host footprint, and a clear pick-X-if decision matrix.
12 min read|Read →
05
GPT-5.5 Has a 3x Higher Hallucination Rate Than MIT-Licensed GLM-5.2
New benchmark data shows GPT-5.5 hallucinates 86% of the time when it does not know the answer - versus 28% for the open-weights GLM-5.2. The numbers challenge the assumption that bigger models equal more reliable output.
6 min read|Read →

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever