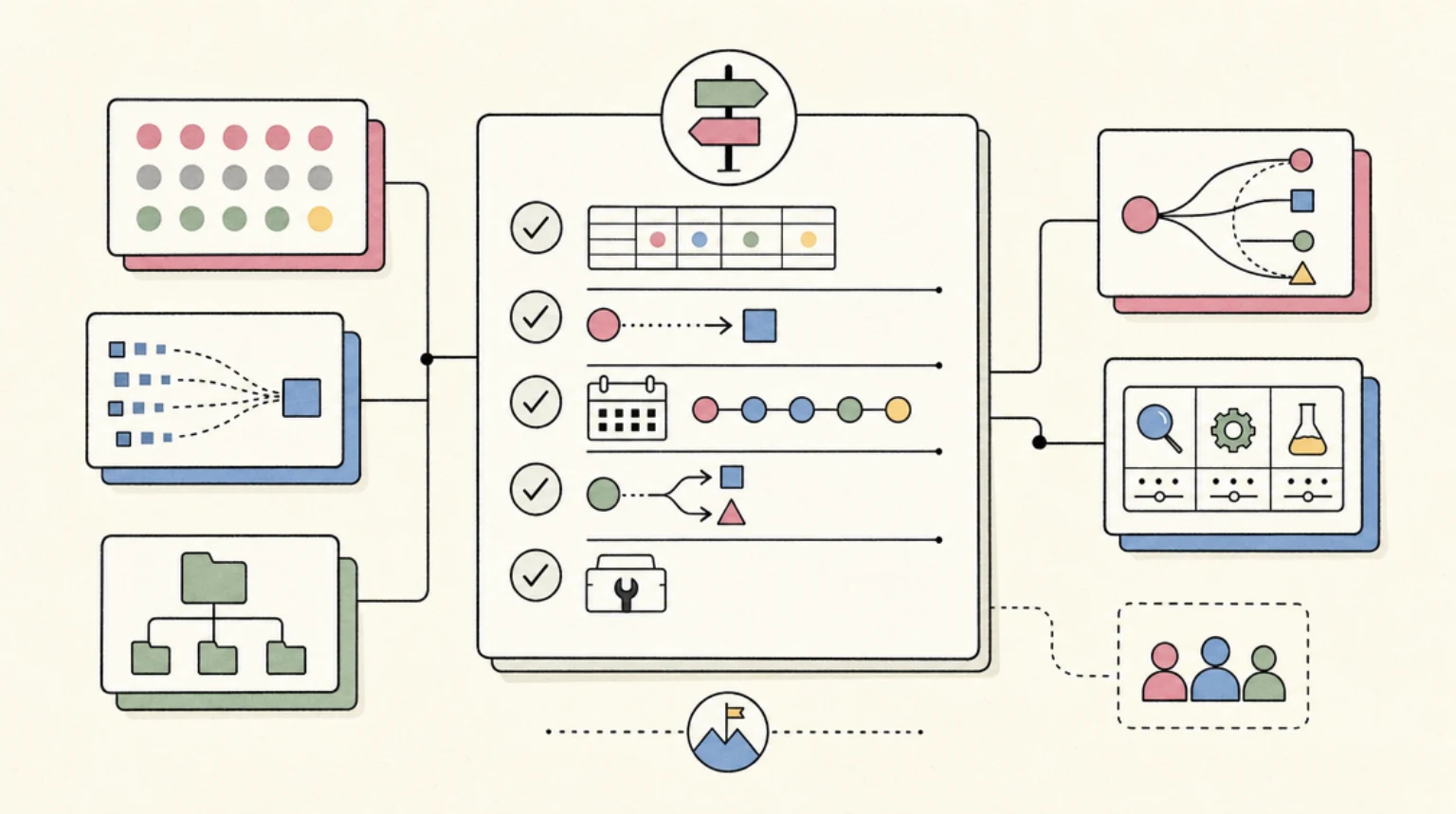
Migrating Off Retired GPT Models in 2026: A Working Checklist
10 min read
OpenAI Enhances Speech Models: New Text-to-Speech & Speech-to-Text Innovations In today's video, we delve into OpenAI's latest release of three new audio models. Discover the enhanced speech-to-text models superior to Whisper, and a groundbreaking text-to-speech model allowing precise control over timing and emotion. Learn how to try these models for free on OpenAI's interface, designed with a distinctive, practical look by Teenage Engineering. Explore various voice types, personality settings, and pronunciation controls. We also compare new models, GPT-4 Transcribe and GPT-4 Mini Transcribe, against other state-of-the-art models. The video provides cost details and a simple guide to getting started with these models using Python, JavaScript, or cURL scripts in the OpenAI API. Additionally, insights into logging, tracing, and example setups in OpenAI Agents SDK are shared. Don't miss out on the future of AI voice applications! Links: https://www.openai.fm/ https://www.youtube.com/watch?v=lXb0L16ISAc https://platform.openai.com/playground/tts https://platform.openai.com/docs/guides/audio https://platform.openai.com/docs/guides/speech-to-text https://platform.openai.com/docs/guides/text-to-speech https://platform.openai.com/docs/api-reference/introduction https://github.com/openai/openai-agents-python/tree/main/examples 00:00 Introduction to OpenAI's New Audio Models 00:16 Exploring the Interface and Features 01:01 Demonstration of Text-to-Speech Capabilities 02:21 New Speech-to-Text Models and Their Performance 03:18 Getting Started with OpenAI's API 04:21 Using OpenAI Agents SDK 05:15 Conclusion and Final Thoughts
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
Weekly deep dives on AI agents, coding tools, and building with LLMs - delivered to your inbox.
Free forever. No spam.
Subscribe Free
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.




