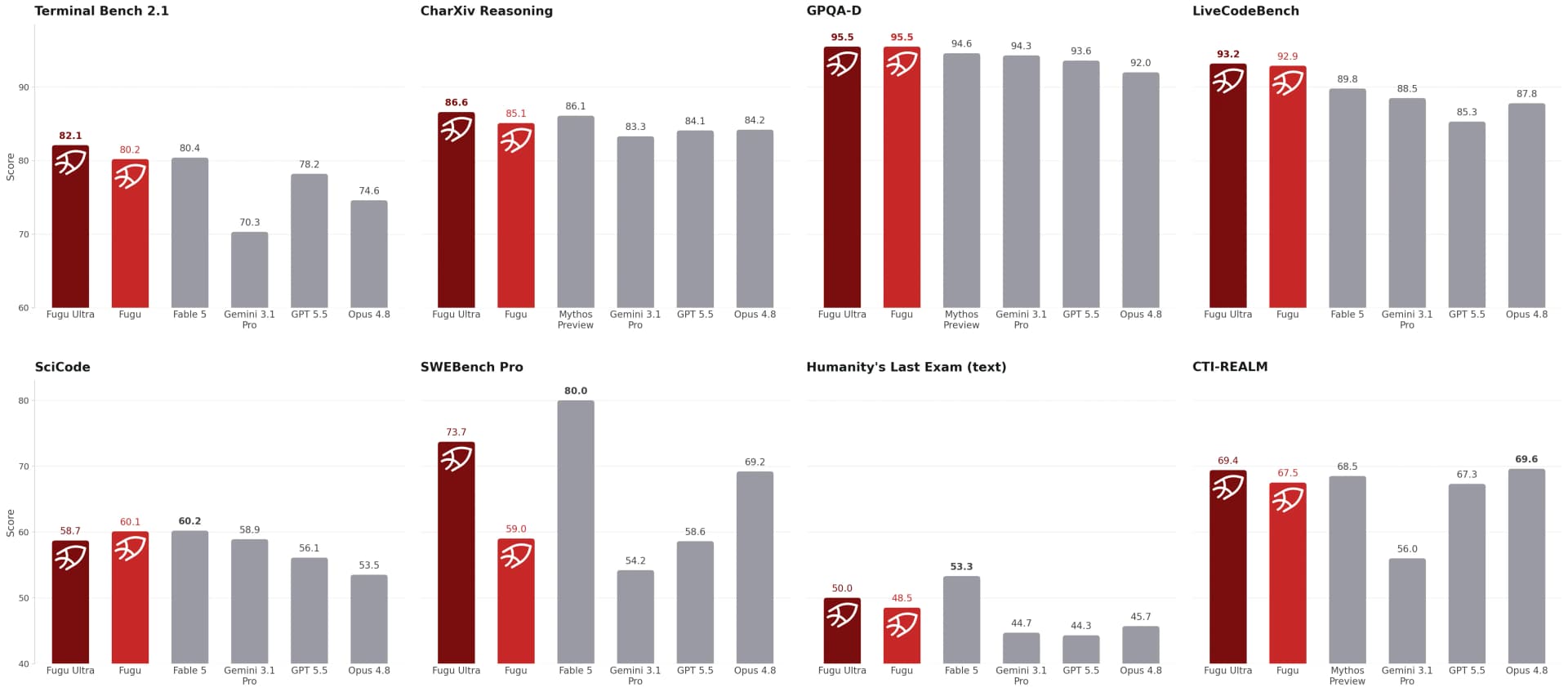
Fugu Ultra's Frontier Performance Claim, Explained Without the Hype
11 min read
Unleashing the Power of Nvidia's 253 Billion Parameter Model: Llama Nemotron Ultra Try out NVIDIA models hosted on NVIDIA platform for free here: https://nvda.ws/3ROOOGW In this video, we explore Nvidia's groundbreaking AI model, the Llama 3.1 Nemotron Ultra, a 253 billion parameter model making waves in scientific reasoning, coding, math, and agentic AI. We dive into its impressive benchmarks, compare it to competitors, and demonstrate its capabilities through various tests. The video also guides you on how to try out Nemotron via Nvidia's platform and showcases examples of the model's ability to follow complex instructions, render visual artifacts, and demonstrate intricate reasoning. Nvidia's open-source approach and post-training techniques are highlighted, alongside practical applications in coding and scientific problem-solving. 00:00 Introduction to Nvidia's AI Revolution 00:27 Overview of Nemotron Model 01:27 Getting Started with Nemotron 02:14 Demonstrating Nemotron Ultra's Capabilities 04:04 Advanced Instruction Following 05:13 Reasoning and Thinking Abilities 07:26 Chain of Thought Puzzle 09:13 Physics and Coding Demonstrations 10:51 Conclusion and Final Thoughts
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
Weekly deep dives on AI agents, coding tools, and building with LLMs - delivered to your inbox.
Free forever. No spam.
Subscribe Free
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.




