Agent Studio: Authoring the Roles, Not Just the Knowledge

TL;DR
Skills gave an agent what to know. The missing half is what role to play. Agent Studio lets you author subagents next to your skills in one place, serve both over the same MCP endpoint with the same progressive disclosure, browse them over REST and the dd CLI, and publish them to the community under a moderation loop. Here is the design and why the two belong in one studio.
Three posts built one idea in stages. The first argued that SKILL.md and the Model Context Protocol solve two halves of the same problem, and that serving skills over MCP lets an agent pay context cost only in proportion to what a task needs. The second let a skill file be a link rather than a copy, fetched only at the moment an agent reaches for it. The third pulled skills, files, memory, and generation onto a single endpoint with tiered disclosure, one key that scopes everything to its owner, and one credit balance.
This post adds the piece that makes the studio complete. Skills answer what an agent should know. They do not answer what role it should play. That second question has its own artifact - a subagent definition - and it now has a home right next to your skills.
One studio, two units
Open the Studio and there is a single segmented toggle: Skills and Agents. Not two pages, not two products. One surface with two tabs, because the two artifacts are edited the same way, served the same way, and used together.
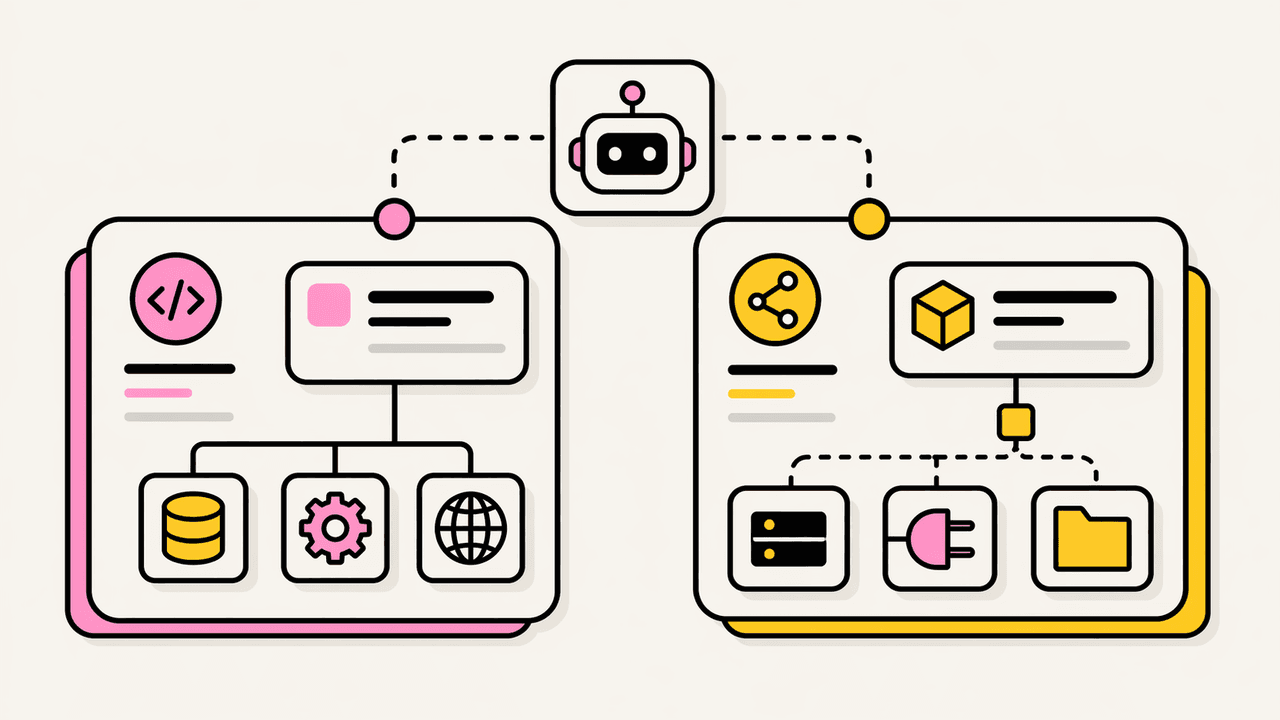
The reason to keep them in one place is that they are complementary halves of the same job. A skill is knowledge: a SKILL.md body plus optional reference material, some of it linked context pulled from the open web on demand. An agent is a role: a focused subagent with a narrow objective, a constrained tool budget, and a system prompt that says what it does and what it returns. You reach for a skill when you want an agent to know how something is done here. You reach for an agent when you want to spawn a worker that does one thing well. A fleet needs both, and authoring them side by side means the person who writes the operating procedure is the person who defines the role that follows it.
An agent is one markdown file
A member agent is deliberately simpler than a skill. Where a skill can carry a manifest of reference files, an agent is a single markdown definition: YAML frontmatter with a name, a description of exactly when to spawn it, a tool list, and a model, followed by the system prompt. That is the same shape a first-party subagent uses, so an agent authored in the Studio is a real, copyable definition rather than a proprietary record.
The starter definition the editor opens with is a filled-in template, not a blank box, so the shape is obvious from the first keystroke:
---
name: my-agent
description: Use when ... . Describe exactly when this subagent should be spawned.
tools: Read, Grep, Glob
model: sonnet
---
You are a focused subagent. State the one job you do, the steps you
follow, and what you return. Be concrete.
The description is doing real work. It is not marketing copy - it is the trigger an orchestrator reads to decide whether to spawn this agent at all. A vague description gets a role that never fires or fires at the wrong time. This is the same discipline that makes a skill's one-line description the thing an agent scans before pulling the body: the cheap text is a routing decision, so it has to be precise.
The same endpoint, again
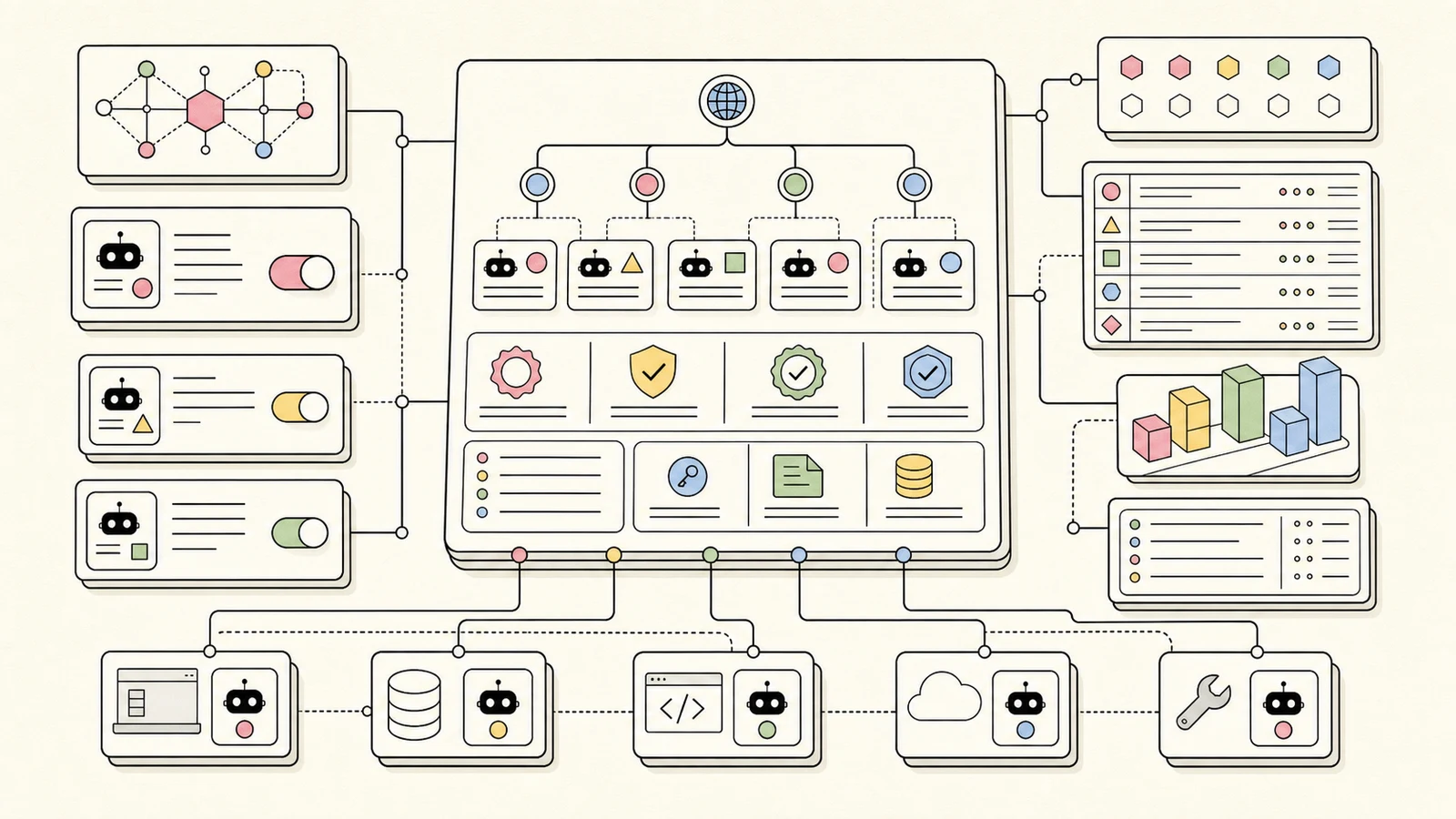
An agent authored in the Studio is served over the exact endpoint the rest of the platform uses. There is no separate agents API. The MCP surface exposes list_agents and get_agent alongside list_skills, get_skill, and everything else, and both resolve against the caller's API key.
Agents collapse the middle tier of progressive disclosure that skills use. A skill has three tiers - a lean index, an overview plus a file manifest, then a file fetched on demand - because a skill has bundled files worth disclosing separately. An agent has no bundled files; the definition is the unit. So list_agents returns the lean index of slugs and names, and get_agent returns the whole definition. Index, then item. The house style of the endpoint is that a two-part surface skips the manifest tier when the item itself is the payload, and agents are exactly that case.
The merge rule matches skills too. When an agent calls list_agents, it sees the first-party agent library, its own Studio agents, and other members' public ones, deduplicated by slug with first-party definitions winning a clash. Your private agents ride the public endpoint but are visible only to your key. Nothing about the transport changed to add agents; the surface was already the right shape.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Nimbalyst: A Visual Workspace That Unifies Codex and Claude Code
Jul 2, 2026 • 6 min read
The Economics of Agent Fleets: Fable 5 Orchestrators, Sonnet 5 Workers
Jul 1, 2026 • 8 min read
Agents 101: How to Build and Deploy Anything with AI Agents
Jul 1, 2026 • 7 min read
Where Should Your AI Agent Run Code: E2B vs Daytona vs Modal vs Cloudflare vs Vercel Sandbox
Jul 1, 2026 • 7 min read
Three front doors
Because agents live on the shared endpoint, they inherit every way of reaching it. The same definitions answer to an MCP client, to plain REST, and to the dd command line, with no per-channel work.
Over REST, GET /api/v1/agents returns the lean index and GET /api/v1/agents/{slug} returns the full definition. Over the CLI, that is dd agents list and dd agents get <slug>, which prints the definition and can drop it straight into a local .claude/agents/ directory so a subagent is ready to spawn. Unlike skills, an agent has no separate download artifact - a skill can be a tree of files worth zipping, but an agent is one markdown file, so get is the whole story. Skills keep their dd skills pull <slug> for the zip that unpacks into .claude/skills/; agents do not need it.
One authored artifact, three front doors, and the choice of door is the caller's. An orchestrating agent discovers a role over MCP mid-task. A developer browses the catalog over REST from a script. Someone setting up a machine runs dd agents get and commits the file. They are all reading the same row.
Publishing to the community, with a moderation loop
A Studio agent starts private. Flip it public and it joins the pool that other members' keys can list and fetch - the same opt-in that skills use, gated on the agent being both public and active. That last word is the safety valve.
Every public agent carries a status, active or hidden. Community members can report an agent, and an owner moderation queue can flip a reported one to hidden. The moment that happens, the agent drops out of everyone else's list_agents immediately, because the cross-member query only returns public, active rows. The author still sees their own agent - hiding is a community-visibility action, not a deletion - so a false report costs nobody their work while a genuine problem stops spreading at once. Moderation is a status flip on a row, not a batch job, so the effect is instant and reversible.
This is what makes community publishing safe to turn on rather than a liability. The default is private, sharing is a deliberate toggle, and the shared pool is filtered on every read so a hidden entry cannot linger in a cache somewhere. The report flow and the owner queue are the human loop around an otherwise mechanical filter.
Why the roles belong next to the knowledge
The thesis of the series has been that the interesting unit of agent tooling is not the prompt or the tool call but the disclosure discipline around a body of knowledge too large to hold and too dynamic to copy. Agents extend that thesis to roles. Coordinating a fleet of agents is not only a matter of giving each one the right knowledge; it is a matter of defining the right workers in the first place - one objective each, the right tool budget, a description precise enough to route on.
Authoring those roles in the same studio as the skills, serving them over the same endpoint, browsing them through the same three doors, and sharing them under the same moderation loop means the two halves stop being separate integrations and become one coherent surface. You write what your agents should know and what your agents should be in the same place, and everything downstream - an MCP client, a REST script, the CLI, another member's fleet - reads both the same way. That is the shape that makes a fleet legible: knowledge and roles, authored together, disclosed on demand, shared safely.
FAQ
What is the difference between a skill and an agent in the Studio?
A skill is knowledge: a SKILL.md body plus optional reference files, including linked context fetched on demand. An agent is a role: a single markdown subagent definition with frontmatter (name, description, tools, model) and a system prompt. Skills tell an agent how something is done; agents define a focused worker to spawn. Both are authored in the same Studio and served over the same endpoint.
How is a member agent served to an AI client?
Over the platform's MCP endpoint through two tools, list_agents (a lean index of slug and name) and get_agent (the full definition). Both resolve against the caller's API key, so you see the first-party agent library, your own agents, and other members' public ones, deduplicated by slug.
Why do agents not have the three-tier disclosure that skills have?
Skills bundle reference files, so they disclose in three tiers: index, then an overview plus a file manifest, then a file on demand. An agent has no bundled files - the definition is the whole unit - so it collapses to two tiers: an index and the item. The endpoint uses the middle manifest tier only when there are separate files worth listing.
Can I use agents without an MCP client?
Yes. The same definitions are available over REST at GET /api/v1/agents and GET /api/v1/agents/{slug}, and over the command line as dd agents list and dd agents get <slug>. The CLI can write the definition into a local .claude/agents/ directory. Skills additionally offer dd skills pull for a downloadable zip; an agent is one file, so it needs no separate download.
What happens when a published agent is reported?
Public agents carry an active or hidden status. A reported agent can be set to hidden through the owner moderation queue, and it then disappears from every other member's list_agents immediately, because the cross-member query returns only public, active rows. The author still sees their own hidden agent; hiding affects community visibility, not ownership, and is reversible.
Are my agents public by default?
No. A Studio agent is private until you explicitly make it public, and even then it is only visible to others while it is both public and active. Your private agents are scoped to your API key and never appear in another member's listing.
Where can I read the rest of this series?
Start with skills over MCP, then linked context in Skill Studio, then the one-endpoint reference architecture. Primary sources: Anthropic's Agent Skills writeup and documentation, the subagents documentation, and the Model Context Protocol spec.
Read next
Skills Delivered Over MCP: Why Progressive Disclosure Is the Missing Piece of Both Standards
SKILL.md solved knowledge packaging with progressive disclosure. MCP solved capability transport but ships flat, context-hungry tool lists. The next shape combines them - an MCP server whose tools are a skill directory, so an agent pays context only for what the task needs. Here is the argument and a working implementation.
9 min readLinked Context: When a Skill Can Point at the Whole Web
The first version of skills-over-MCP served a fixed first-party catalog. Skill Studio extends it two ways: anyone can author skills that ride the same progressive-disclosure endpoint scoped to their own API key, and a skill file can be a link instead of a copy - a URL whose bytes are only fetched at the moment an agent decides it needs them. Progressive disclosure stops at the skill boundary no longer. It runs out to the open web.
10 min readOne Endpoint, Every Capability: A Reference Architecture for Progressive Disclosure
Skills, files, memory, and generation do not need four integrations. They need one MCP endpoint with tiered disclosure, one API key that scopes everything to its owner, and one credit balance. The same tools answer to an MCP client, an in-product chat, and a CLI. Here is the whole architecture, and why it is the shape that makes a fleet of agents coherent.
10 min readTechnical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.