Linked Context: When a Skill Can Point at the Whole Web

TL;DR
The first version of skills-over-MCP served a fixed first-party catalog. Skill Studio extends it two ways: anyone can author skills that ride the same progressive-disclosure endpoint scoped to their own API key, and a skill file can be a link instead of a copy - a URL whose bytes are only fetched at the moment an agent decides it needs them. Progressive disclosure stops at the skill boundary no longer. It runs out to the open web.
A previous post made an argument: SKILL.md and the Model Context Protocol solve two halves of the same problem, and the useful move is to run skills over MCP so an agent pays context cost only in proportion to what a task needs. The implementation was three tools - list_skills, get_skill, get_skill_file - rebuilding progressive disclosure on the wire. That version worked, but it served a fixed catalog we wrote. This post is about what happens when you take the two constraints off that design: that the skills have to be ours, and that a skill's contents have to be copied in ahead of time.
Both constraints are gone now. The feature is called Skill Studio, and the interesting part is not the authoring UI. It is what the authoring UI is allowed to reference.
The constraint worth removing
Go back to what a skill actually is. A skill is a SKILL.md with a name and a description, plus optional bundled files - reference docs, checklists, scripts - that the agent pulls in only when the work demands them. In the first version, every one of those bundled files was content we had written and stored. The manifest an agent saw over get_skill listed real files with real bytes behind them, sitting in our data store, waiting to be fetched.
That is fine for a curated library. It falls apart the moment you want a skill to reference something you do not own and that changes without you. A framework's migration guide. An API's current pricing page. Your own team's runbook that lives in a wiki. The moment a skill's value depends on a document maintained somewhere else, copying that document into the skill is the wrong move. The copy is stale the day after you make it, and now you own a synchronization problem you did not ask for.
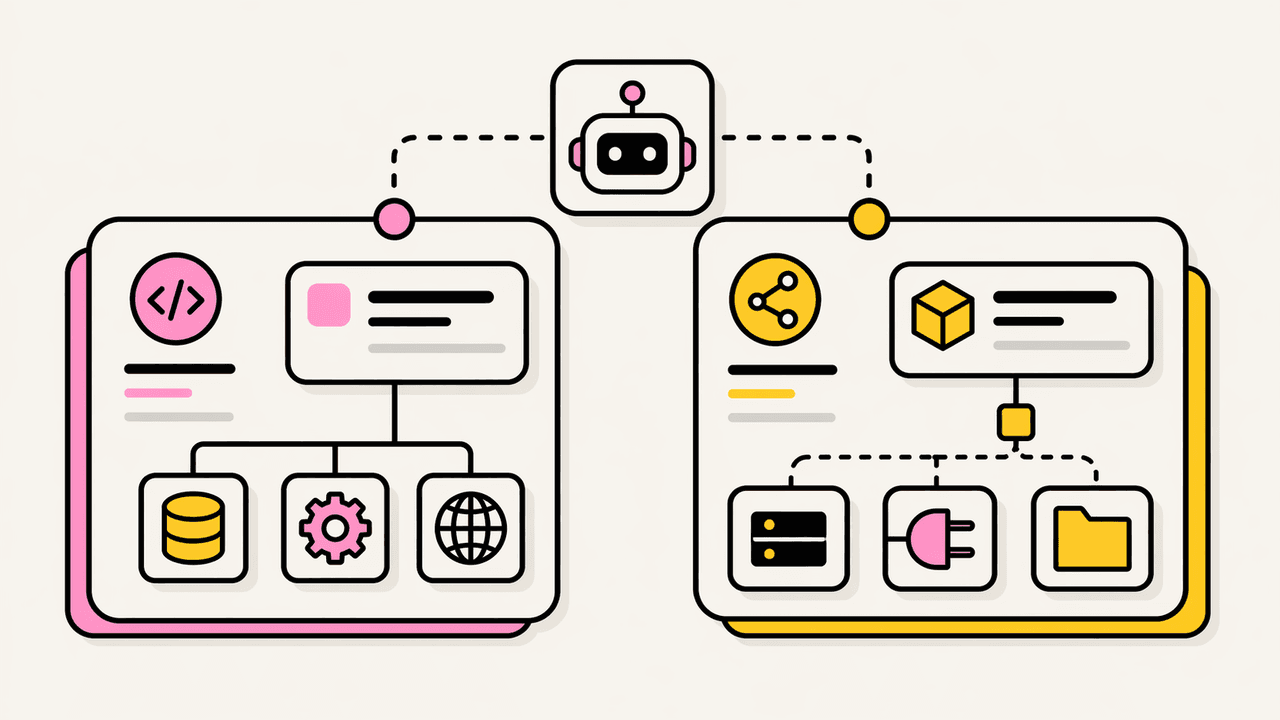
The fix is to let a skill file be a reference instead of a copy. In the Studio, a file inside a skill is one of two kinds. An inline file is content authored in place and stored with the skill, exactly like before. A linked file is a URL. The skill stores the path and the URL and nothing else. No bytes are copied at author time. The document on the other end stays where it is, owned by whoever owns it, changing whenever it changes.
Progressive disclosure, extended past the skill
Here is the part that makes this more than a convenience. A linked file is not fetched when the skill is saved, and it is not fetched when an agent lists skills, and it is not even fetched when an agent opens the skill to read its manifest. It is fetched at exactly one moment: when the agent calls get_skill_file on that specific path because the SKILL.md body told it that this is the depth it now needs.
That is the same escalation the original three tools implemented, carried one level further out. The first version disclosed in three stages: the cheap index, then one skill's body and file manifest, then one file's contents. Linked context adds a fourth boundary. The contents of that one file might themselves live on the open web, and the token cost of that remote document is only paid at the instant of the fetch. An agent can hold a skill in context whose reference material is a ten-thousand-word external spec, and pay nothing for that spec until the one task in a hundred that actually reaches for it.
Progressive disclosure was always about paying in proportion to need. The skill boundary used to be where that discipline stopped: past it, everything was copied in and resident. Linked context moves the boundary out to the network. The manifest an agent reads carries the path, a one-line purpose, and the fact that the source is remote - but never the contents. It is a promise of context, redeemable on demand, rather than context you are already carrying.
The resolution itself is deliberately boring, because a feature that can fetch arbitrary URLs on behalf of an agent has to be. Links are validated as ordinary public http(s) URLs, with internal and loopback hosts refused so a skill cannot be pointed at infrastructure it should not see. Fetches run with a timeout and a size cap, so one slow or enormous document degrades to a truncated read rather than a hung tool call. A failed fetch does not throw - it returns a readable message as the file's contents, so the agent learns the source was unreachable instead of watching the call crash. The point of linked context is to widen what a skill can reach without widening what can go wrong when it reaches.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
The Economics of Agent Fleets: Fable 5 Orchestrators, Sonnet 5 Workers
Jul 1, 2026 • 8 min read
Agents 101: How to Build and Deploy Anything with AI Agents
Jul 1, 2026 • 7 min read
Where Should Your AI Agent Run Code: E2B vs Daytona vs Modal vs Cloudflare vs Vercel Sandbox
Jul 1, 2026 • 7 min read
Text-to-Speech APIs for Developers in 2026: What to Actually Use
Jul 1, 2026 • 8 min read
The same endpoint, scoped to your key
The second constraint we removed was ownership. In the first version, the catalog was first-party. Skill Studio lets any member author skills, and those skills are served over the identical MCP endpoint, through the identical three tools, with the identical disclosure tiers. There is no second API, no separate "user skills" transport, no different shape to learn.
The way this stays safe is scoping by key. MCP has no session on its transport - there is no cookie, no logged-in browser. Every call authenticates with an API key, and the key resolves to exactly one owner. So when an agent calls list_skills, the response is the first-party library plus that caller's own skills, and nobody else's. get_skill and get_skill_file resolve against the same visible set. Your skills ride the public endpoint, but they are visible only to the key that owns them. The universal library and your private skills come down the same pipe, disambiguated entirely by who is asking.
This matters more than it sounds. It means a member's own skills get the exact economics and mechanics of the flagship ones. The manifest a user skill produces mirrors the first-party manifest field for field, so an agent cannot tell the difference between a skill we wrote and a skill you wrote - both disclose the same way, cost context the same way, and download the same way. The library stops being a thing we publish to you and becomes a surface you extend. You are not consuming a catalog. You are adding to the one your own agents read.
Authoring is consumption
The third idea is the smallest and the one that changes how it feels to use. The Studio has a live preview, and the preview does not render a prettied-up marketing view of your skill. It renders the file tree exactly as an agent sees it over MCP: SKILL.md first, then each file with its path and its one-line purpose, inline files showing their content, linked files showing their URL and the fact that their bytes arrive on demand.
The reason this is worth building deliberately is that the usual failure mode of authoring tools is a gap between what the author sees and what the consumer gets. You write in a rich editor, the machine receives something flattened and different, and you find out about the mismatch when the agent behaves oddly. Collapsing that gap means the thing you are editing and the thing an agent will read are the same artifact. When you mark a file as a link, you immediately see it presented as a promise of remote context rather than resident text - which is exactly how the agent will encounter it. When you write a SKILL.md body, you are writing the activation-stage document an agent will pull, not a description of it.
Authoring becomes consumption. The preview is not a preview of a rendering; it is a preview of the disclosure. That is the right shape for a tool whose output is read by a model, because the model reads the raw artifact, and so should you while you make it.
Why this is the direction
None of these three moves is a new primitive. Linked context is MCP's resource model - a manifest of things that can be fetched, rather than a wall of content - applied to skill files. Per-key scoping is just honest multi-tenancy on an endpoint that already authenticates every call. The live preview is the old lesson that authoring and consumption should not diverge. What is new is putting them together and noticing that they compose into something with a clear trajectory.
The trajectory is this. A skill started as a file on one machine's disk. The first version made it a thing served from a network, so it could be versioned and shared and access-controlled like an API. Linked context makes a skill a composition of references - some resident, some remote, all disclosed only when needed - so a skill can assemble context from anywhere without paying for it up front. Per-key scoping makes that composition personal, so the library an agent reads is partly ours and partly yours with no seam between them. The direction of travel is from context as a payload you ship to context as a graph you point into and pull from lazily, and skills-over-MCP turns out to be a clean substrate for exactly that.
That is the bet Developers Digest is making at the frontier of agent tooling: the interesting unit is not the prompt or the tool call but the disclosure discipline around a body of knowledge that is too large to hold and too dynamic to copy. Skill Studio is the first place you can build on that unit directly.
FAQ
What is a linked context file?
It is a file inside a skill whose contents live at a URL rather than being stored with the skill. The skill's manifest carries the path and the URL; the bytes are fetched on demand only when an agent calls get_skill_file for that path. It lets a skill reference an external document - a spec, a changelog, a runbook - without copying it in and without owning a synchronization problem.
How is that different from just pasting the document into the skill?
A pasted document is a copy: stale the moment the source changes, and resident in the skill whether or not any task needs it. A linked file stays current because it points at the live source, and it costs no context until the moment an agent decides to fetch it. You trade a guaranteed stale copy for a fresh fetch paid for only on use.
Do user skills use a different MCP endpoint than the first-party library?
No. Member-authored skills are served over the same MCP endpoint through the same three tools - list_skills, get_skill, get_skill_file - with the same progressive-disclosure tiers. They are scoped by API key, so a caller sees the shared library plus their own skills and nobody else's.
How are my skills kept private if they are on a public endpoint?
The MCP transport has no session; every call authenticates with an API key that resolves to one owner. The skill-listing and skill-fetching tools resolve against the set visible to that key, which is the first-party library plus the key owner's own skills. Another member's key never sees yours.
Can a linked file point at an internal or private URL?
No. Links are validated as public http(s) URLs, and internal or loopback hosts are refused, so a skill cannot be aimed at infrastructure it should not reach. Fetches also run under a timeout and a size cap, and a failed fetch returns a readable error as the file contents rather than crashing the tool call.
What does the Studio live preview show?
It renders the skill exactly as an agent receives it over MCP: SKILL.md first, then each file with its path and one-line purpose, inline files showing content and linked files showing their URL and on-demand nature. The artifact you edit is the artifact the agent reads, so there is no gap between authoring and consumption.
Where can I read the background on skills over MCP?
Start with the earlier post, Skills Delivered Over MCP, then the primary sources: Anthropic's Agent Skills writeup and documentation, and the Model Context Protocol resources specification.
Read next
Skills Delivered Over MCP: Why Progressive Disclosure Is the Missing Piece of Both Standards
SKILL.md solved knowledge packaging with progressive disclosure. MCP solved capability transport but ships flat, context-hungry tool lists. The next shape combines them - an MCP server whose tools are a skill directory, so an agent pays context only for what the task needs. Here is the argument and a working implementation.
9 min readOne Endpoint, Every Capability: A Reference Architecture for Progressive Disclosure
Skills, files, memory, and generation do not need four integrations. They need one MCP endpoint with tiered disclosure, one API key that scopes everything to its owner, and one credit balance. The same tools answer to an MCP client, an in-product chat, and a CLI. Here is the whole architecture, and why it is the shape that makes a fleet of agents coherent.
10 min readPoint Your Agent at Developers Digest
developersdigest.tech now speaks MCP. Any MCP-capable harness can call the site's tools directly - generate media, pull vetted skills and agents on demand, persist memory across sessions, search the content, and count tokens. Here is what shipped and how to connect.
7 min readTechnical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.