PgDog Just Got Funded: What the Postgres Sharding Proxy Means for Your Stack
TL;DR
PgDog raised $5.5M to bring transparent Postgres sharding and connection pooling to any stack. Here is what it actually does, how it compares to PgBouncer and Citus, and the honest answer to whether you need it.
Postgres is quietly becoming the default database for everything - transactional apps, AI pipelines, vector search, analytics sidecars. The more it wins, the harder the scaling wall gets. And for most teams, the first thing that actually breaks under real traffic is not the queries: it is the connections and the single-node ceiling.
That is the problem PgDog is targeting. On June 10, 2026, the project's HN post - "PgDog is funded and coming to a database near you" - hit 326 points and 167 comments, signaling real developer interest in a funded, production-deployed Postgres proxy that handles connection pooling, replica load balancing, and horizontal sharding from a single network layer. The round was $5.5M from Basis Set Ventures, Y Combinator, and Pioneer Fund.
Last updated: June 10, 2026
What PgDog actually is#
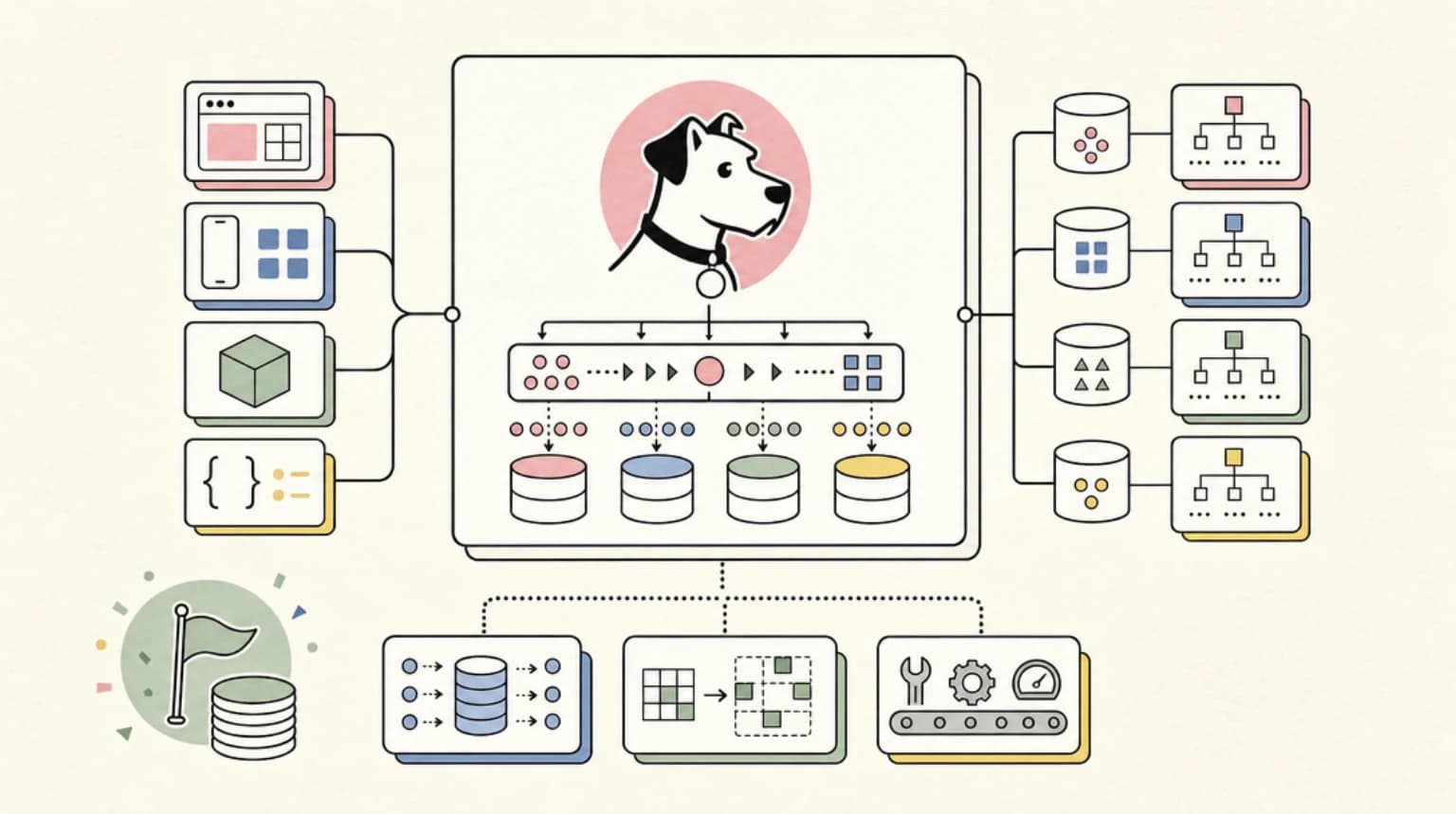
PgDog is a network proxy for Postgres, written in Rust. You point your DATABASE_URL at it instead of directly at your database, and it handles the hard stuff between your application and one or more Postgres instances.
The project comes from Lev Kokotov, who ran Postgres at Instacart during the April 2020 grocery rush - a 5x traffic spike that required sharding Postgres across RDS, Aurora, and EC2 under production conditions. PgDog is essentially that operational knowledge packaged as an open-source product.
Three capabilities ship today:
Transaction pooling. Like PgBouncer, PgDog multiplexes thousands of application connections onto a small pool of actual Postgres server connections. Unlike PgBouncer, it can parse and correctly handle SET statements and session parameters in transaction mode - a long-standing rough edge that forces teams to avoid PgBouncer for ORMs that rely on SET heavily.
Replica load balancing. PgDog parses SQL using the native Postgres query parser (via pg_query.rs) and automatically routes SELECT statements to replicas and writes to the primary. It monitors replication lag and health-checks each host, pulling unhealthy replicas out of rotation. It can also detect primary promotion for Aurora/Patroni-based failovers automatically.
Transparent sharding. This is the headline feature. You configure multiple Postgres databases as shards, define a sharding key per table, and PgDog routes queries to the right shard based on that key. Direct-to-shard queries (where the key is in the WHERE clause) go to one database. Cross-shard queries fan out and the results are assembled in memory before being returned to the client - standard aggregates, ORDER BY, GROUP BY, and multi-tuple INSERTs are supported today.
The proxy also supports schema-based sharding, two-phase commit for cross-shard write atomicity, online re-sharding via Postgres logical replication, COPY with automatic row splitting across shards, and a pgdog.unique_id() function for globally unique BIGINT primary keys without a sequence.
Where it comes from#
PgDog is a successor to PgCat, an earlier Rust-based Postgres proxy that Lev also wrote. The GitHub repository has accumulated over 1.4M Docker pulls. The funding announcement states the proxy is "serving more than 2M queries per second, in production, across dozens of deployments" and has been used to shard over 20 TB of data.
HN commenters who have deployed it directly corroborated this. One wrote: "I've moved from pgbouncer to pgdog a few months ago without issue. Huge fan." Another noted: "I've loved using pgdog for the last 6 months. It's been incredibly stable. It's nifty how they've solved the LISTEN/NOTIFY on a transaction pooler problem."
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
The TypeScript AI Agent Stack in Mid-2026: Mastra vs Vercel AI SDK vs OpenAI Agents SDK vs LangGraph.js
Jun 10, 2026 • 10 min read
Vercel AI SDK 6 vs LangGraph 1.0: Which Agent Framework Should TypeScript Teams Use?
Jun 10, 2026 • 8 min read
Claude Mythos 5 Explained: What It Is, Who Can Access It, and Why It's Gated
Jun 10, 2026 • 7 min read
Agent Config Files Are Executable Supply Chain
Jun 8, 2026 • 8 min read
How it compares to the alternatives#
| PgDog | PgBouncer | Citus | Managed (Neon/Supabase/RDS Proxy) | |
|---|---|---|---|---|
| Connection pooling | Yes (transaction + session) | Yes (best-in-class) | Via PgBouncer | Yes (provider-managed) |
| Replica load balancing | Yes, automatic | No | No | Partial (provider varies) |
| Horizontal sharding | Yes, transparent | No | Yes, via extension | No (Neon: storage-layer only) |
| App code changes | None | None | Schema changes required | None |
| Cross-shard queries | Partial support | N/A | Full SQL support | N/A |
| Deployment | Self-hosted (K8s, ECS, Docker) | Self-hosted | Self-hosted or managed | Fully managed |
| License | AGPL v3 | ISC | AGPL v3 (core) | Proprietary |
| Written in | Rust | C | C | N/A |
| Handles SET in txn mode | Yes | No | N/A | Varies |
PgBouncer remains the proven default for pure connection pooling. It is battle-tested, simple to operate, and most teams deploying it do not need anything else. PgDog's advantage over PgBouncer is the SET statement handling, query routing, and sharding - not raw pooling throughput.
Citus is an extension, meaning it runs inside Postgres itself and has deeper SQL compatibility for distributed queries. Cross-shard operations in Citus are generally more capable than PgDog's current in-memory assembly approach. The tradeoff is that Citus requires a schema migration and data re-partitioning at the Postgres level, while PgDog's sharding is entirely at the proxy layer - no pg_extension install, no changes to existing tables beyond routing config.
Managed services like Neon and Supabase handle scaling through storage-layer branching and read replicas rather than sharding. They are the right answer if you want zero operational overhead. PgDog is self-hosted infrastructure that requires a team willing to operate it.
RDS Proxy is worth mentioning for AWS shops: it handles connection pooling for RDS and Aurora but does not do sharding or replica routing. It is a managed PgBouncer equivalent with IAM authentication - PgDog actually supports RDS IAM tokens as a backend auth method, so the two can coexist.
What the funding means for adoption#
Funding in an infrastructure tool changes the calculus in a specific way. On the upside, it means a full-time team with runway, weekly releases, enterprise support SLAs, and continued investment in the harder features (re-sharding without downtime, better cross-shard SQL coverage). The AGPL license is permissive for self-hosting - internal use and private modifications do not require source disclosure. Only organizations offering PgDog as a public service need to share modifications.
The risk side is real and worth naming. An AGPL-licensed infra tool backed by VC may change its licensing when it needs revenue. The enterprise edition already exists (AWS-focused). The pattern of open-core infrastructure startups eventually tightening the license of popular features is common enough to watch for. If PgDog becomes critical path for your database, track license changes in the repository the way you would for any infrastructure dependency.
One HN commenter put the skeptical view directly: "It might be anti-marketing, still it would be helpful if the use cases can be articulated in a way where it would make sense to use this vs any other type of database. Honesty goes a long way with the more technical folks for anything related to infrastructure."
Another flagged real operational friction: "I tried out PgDog a while ago, but couldn't find a good way of handling the config except for having this users/pgdog toml file, which makes it a bit awkward to handle in kubernetes where we often do multi-tenancy in postgres - or rather having many databases on the same instance(s)."
Cross-shard SQL support gaps also came up. CTEs and subqueries are not distributed - the same query runs on all shards, which can produce incorrect results for non-trivial aggregates. For teams with complex reporting queries this matters.
When should you actually care#
Most applications running Postgres do not need sharding. The real decision tree looks like this:
You probably do not need PgDog yet if: your Postgres instance has headroom on CPU and memory, you are not close to the connection ceiling, and your dataset fits comfortably on one machine. Vertical scaling and proper indexing cover an enormous range of workloads. A single well-tuned Postgres instance on a large VM handles more than most SaaS products will ever throw at it.
PgBouncer (or pgBouncer-compatible managed pooling) is probably sufficient if: your only problem is connection count. Rails with Puma, Django with Gunicorn, and Node.js with async ORMs can all generate hundreds of connections that Postgres handles poorly. Connection pooling alone fixes this without introducing sharding complexity.
PgDog becomes worth evaluating if: you are at the point where your primary is CPU-bound on reads and you want replica routing without application changes, or you have already decided you need sharding and want to do it at the proxy layer rather than the extension layer. The PgBouncer SET statement issue is also a legitimate operational reason to switch for teams already using transaction mode.
Sharding specifically becomes relevant if: a single Postgres instance cannot handle your write throughput or your dataset size is creating vacuum/autovacuum pressure across very large tables. This is a real problem, but it typically appears at a scale most teams will never reach before other architectural concerns (caching, read replicas, read-only analytics offload) have already addressed the load.
The honest summary: if you are building an AI application today and Postgres is your primary store, you almost certainly do not need sharding. You may need connection pooling. PgDog is good infrastructure to watch as it matures, but the bar for adding a proxy between your application and your database is higher than it looks in a funding announcement.
FAQ#
What is PgDog and how does it differ from PgBouncer?#
PgDog is a Postgres proxy written in Rust that combines connection pooling, replica load balancing, and horizontal sharding. PgBouncer handles only connection pooling. PgDog also correctly handles SET statements in transaction pooling mode, which PgBouncer does not, making it compatible with more ORM configurations.
Does PgDog require changes to my application code or database schema?#
No application code changes are required - you change your DATABASE_URL to point at PgDog instead of Postgres directly. Sharding does require configuring sharded tables and a sharding key in pgdog.toml, but does not require Postgres extensions or schema migrations.
What license is PgDog under - can I use it commercially?#
PgDog is AGPL v3. You can use it internally, including in commercial products, and make private modifications without sharing source code. The AGPL share-alike requirement only applies to organizations offering PgDog as a public service to third parties.
How does PgDog compare to Citus for Postgres sharding?#
Citus is a Postgres extension that shards at the database engine level and supports a broader range of distributed SQL. PgDog is a proxy-layer solution with no Postgres extension required. Citus has stronger cross-shard query support; PgDog has simpler deployment and zero schema-level changes. For most teams evaluating sharding, Citus offers more SQL completeness today while PgDog offers easier adoption.
Sources#
- PgDog funding announcement: https://pgdog.dev/blog/our-funding-announcement
- PgDog GitHub repository: https://github.com/pgdogdev/pgdog
- PgDog documentation: https://docs.pgdog.dev/
- Hacker News discussion: https://news.ycombinator.com/item?id=48476466
- PgDog Helm chart: https://github.com/pgdogdev/helm
- PgDog ECS Terraform module: https://github.com/pgdogdev/pgdog-ecs-terraform
Read next
pgrust Passes 100% of Postgres Regression Tests: What the Rust Rewrite Actually Means
A Rust reimplementation of PostgreSQL now passes all 46,000+ queries in the Postgres regression suite. Here is what the project actually delivers, what it does not, and why the HN discussion reveals deeper questions about AI-assisted rewrites.
8 min readNeon Postgres in 2026: Review and Setup for AI App Builders
Neon's branching model, serverless driver, and scale-to-zero autoscaling make it one of the most practical Postgres hosts for teams building AI agents and preview-heavy apps. Here is what you need to know before committing.
9 min readThe Startup's Postgres Survival Guide: What HN Is Saying About Hatchet's Battle-Tested Advice
A practical look at the operational Postgres guide that hit the HN front page - what it gets right, what the community pushed back on, and what every startup should internalize about running Postgres in production.
5 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
Infrastructure
Supabase
Open-source Firebase alternative built on Postgres. Auth, real-time subscriptions, storage, edge functions, and pgvector...
View ToolInfrastructure
Drizzle ORM
Type-safe SQL builder and ORM for TypeScript. Zero runtime overhead, honest schema migrations, bring-your-own-DB.
View ToolInfrastructure
Prisma
TypeScript ORM with a schema-first workflow. Prisma Client gives full type safety; Prisma Migrate handles migrations. Wo...
View ToolInfrastructure
Neon
Serverless Postgres with branching. Free tier, instant database branches per PR, autoscaling compute, and scale-to-zero....
View ToolApps from Developers Digest
SaaS ProductsIn Progress
RSS Radar
Watch any list of changelogs/blogs, get a single daily digest of what shipped - filtered by your stack and with AI-written one-liners.
View AppSaaS ProductsIn Progress
Neon Data Lite
Schema browser, migration planner, RLS auditor, and SQL notebook for Postgres. Built for Neon, Supabase, or bare Postgres.
View AppDeveloper Tools
DD Traces
See exactly what your agent did, locally. No cloud, no signup.
View AppRelated Guides
Guide
MCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
AI AgentsGuide
Getting Started with DevDigest CLI
Install the dd CLI and scaffold your first AI-powered app in under a minute.
Getting StartedGuide
Run AI Models Locally with Ollama and LM Studio
Install Ollama and LM Studio, pull your first model, and run AI locally for coding, chat, and automation - with zero cloud dependency.
Getting StartedRelated Videos

Build a SaaS Web App with Cursor, v0, Next.js + Postgres
In this video, I walk you through the process of building a micro SaaS application from scratch. We will utilize tools like cursor, V0, and Postgres.new alongside a tech stack that includes...
Video·

Langchain, Next.js, Brave API, OpenAI GPT 3.5/4 and Vercel Postgres
#FullStackApp #AutonomousApp #Langchain #NextJS #BraveAPI #OpenAIGPT #VercelPostgres #WebDevelopment #CodingTutorial #AIIntegration #AutonomousSystems In this comprehensive tutorial, we delve...
Video·
Related Posts

5 min read
News
The Startup's Postgres Survival Guide: What HN Is Saying About Hatchet's Battle-Tested Advice
A practical look at the operational Postgres guide that hit the HN front page - what it gets right, what the community p...
8 min read
News
pgrust Passes 100% of Postgres Regression Tests: What the Rust Rewrite Actually Means
A Rust reimplementation of PostgreSQL now passes all 46,000+ queries in the Postgres regression suite. Here is what the...
9 min read
postgres
Neon Postgres in 2026: Review and Setup for AI App Builders
Neon's branching model, serverless driver, and scale-to-zero autoscaling make it one of the most practical Postgres host...

9 min read
AI Agents
Introducing agentfs: A Filesystem for AI Agents
agentfs is filesystem-shaped storage for AI agents. Postgres-backed on Neon, no cold starts, no exec by design. Pay-only...

7 min read
News
Roc's Rust-to-Zig Rewrite: 487 Days, 300K Lines, and What the Numbers Actually Show
Richard Feldman's team rewrote the Roc compiler from Rust to Zig in 487 days. The memory safety numbers challenge assump...

7 min read
Git
Entire Distributed Git Network: A Developer Guide to the Ex-GitHub CEO's Agent-Era Platform
How to set up Entire's regional Git mirrors for AI coding agents. Covers installation, mirroring, integrations with Clau...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever