New8 min read
Fable 5 Effort Levels vs Switching Models: When to Dial and When to Change
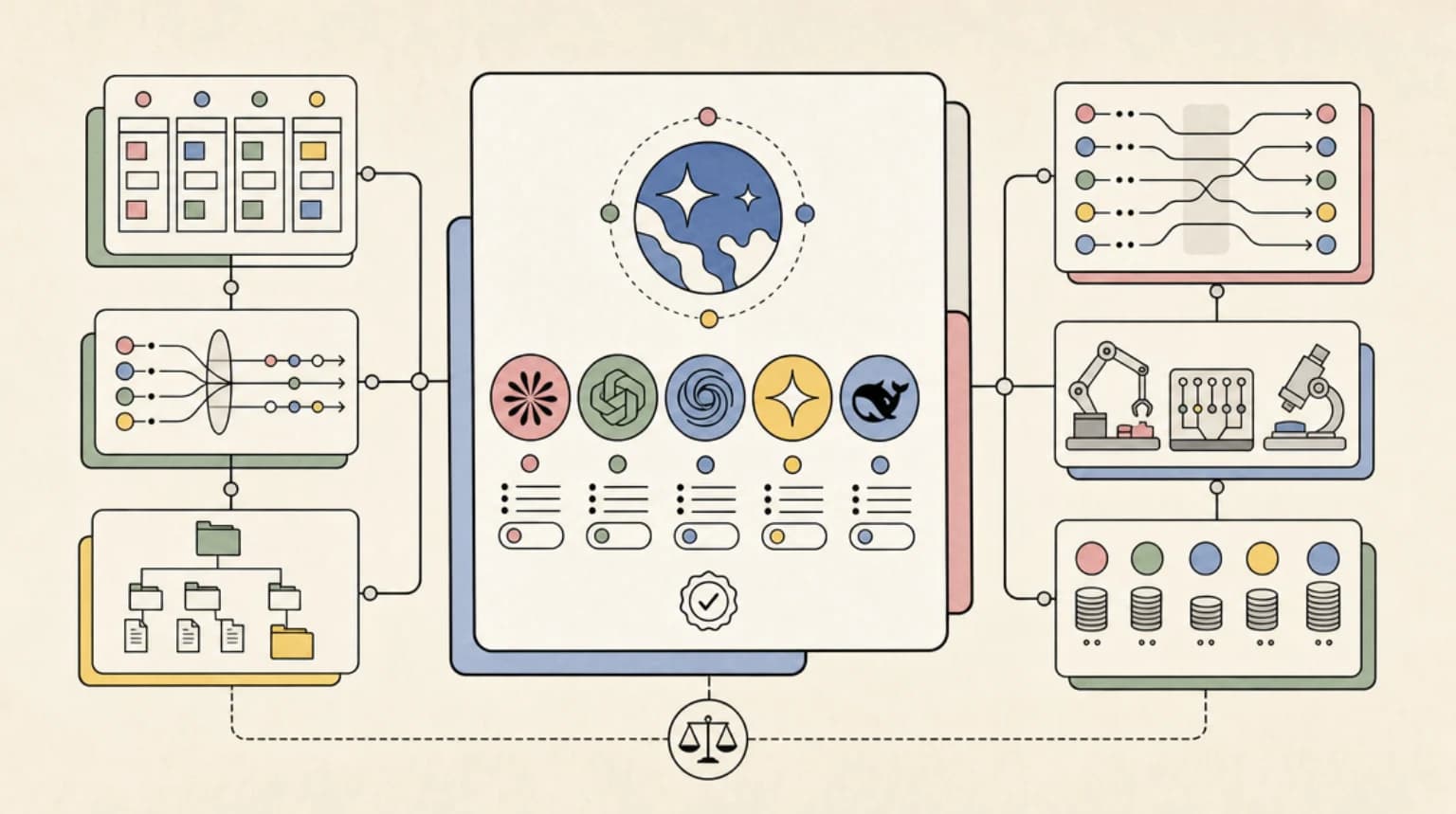
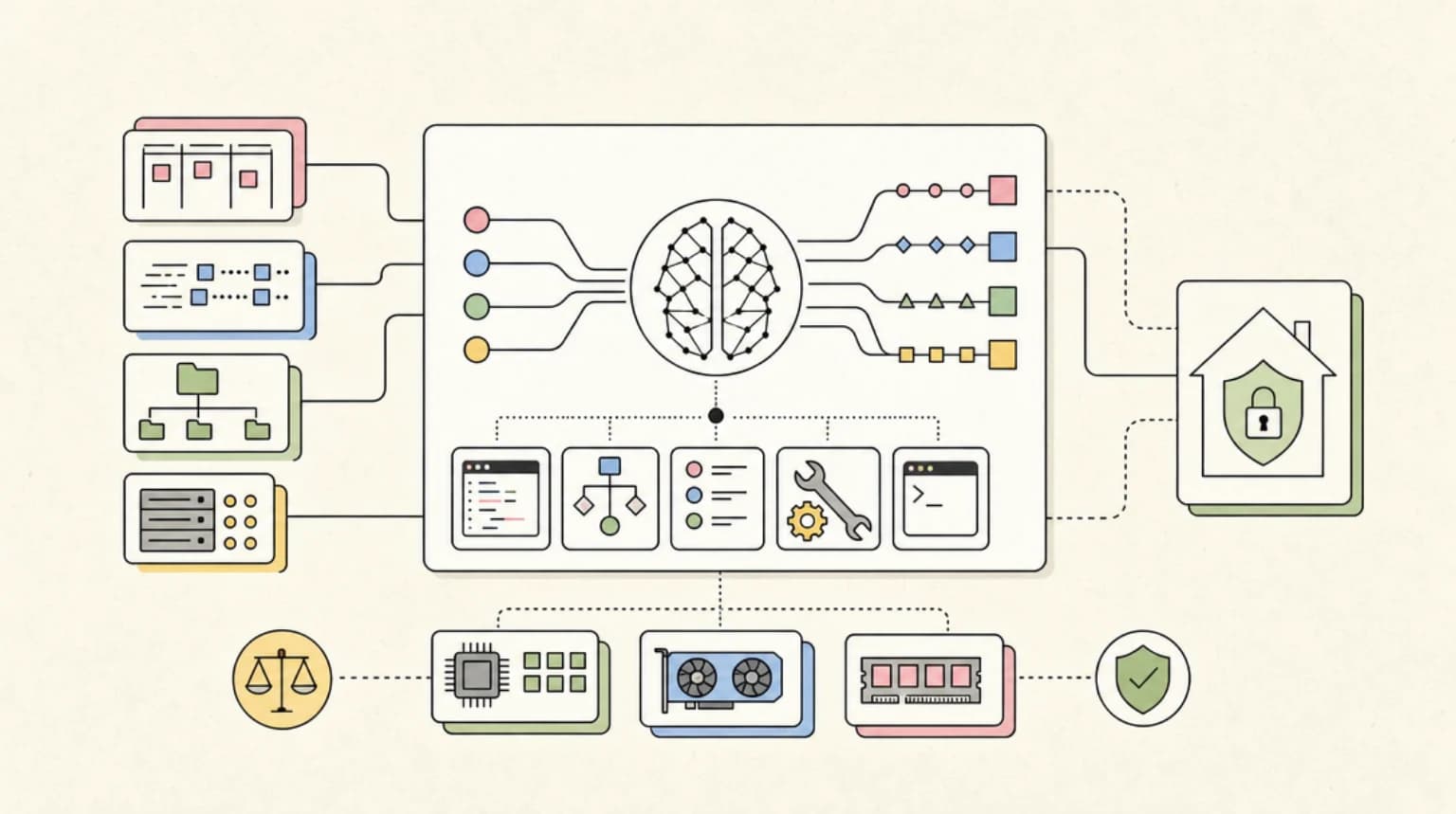
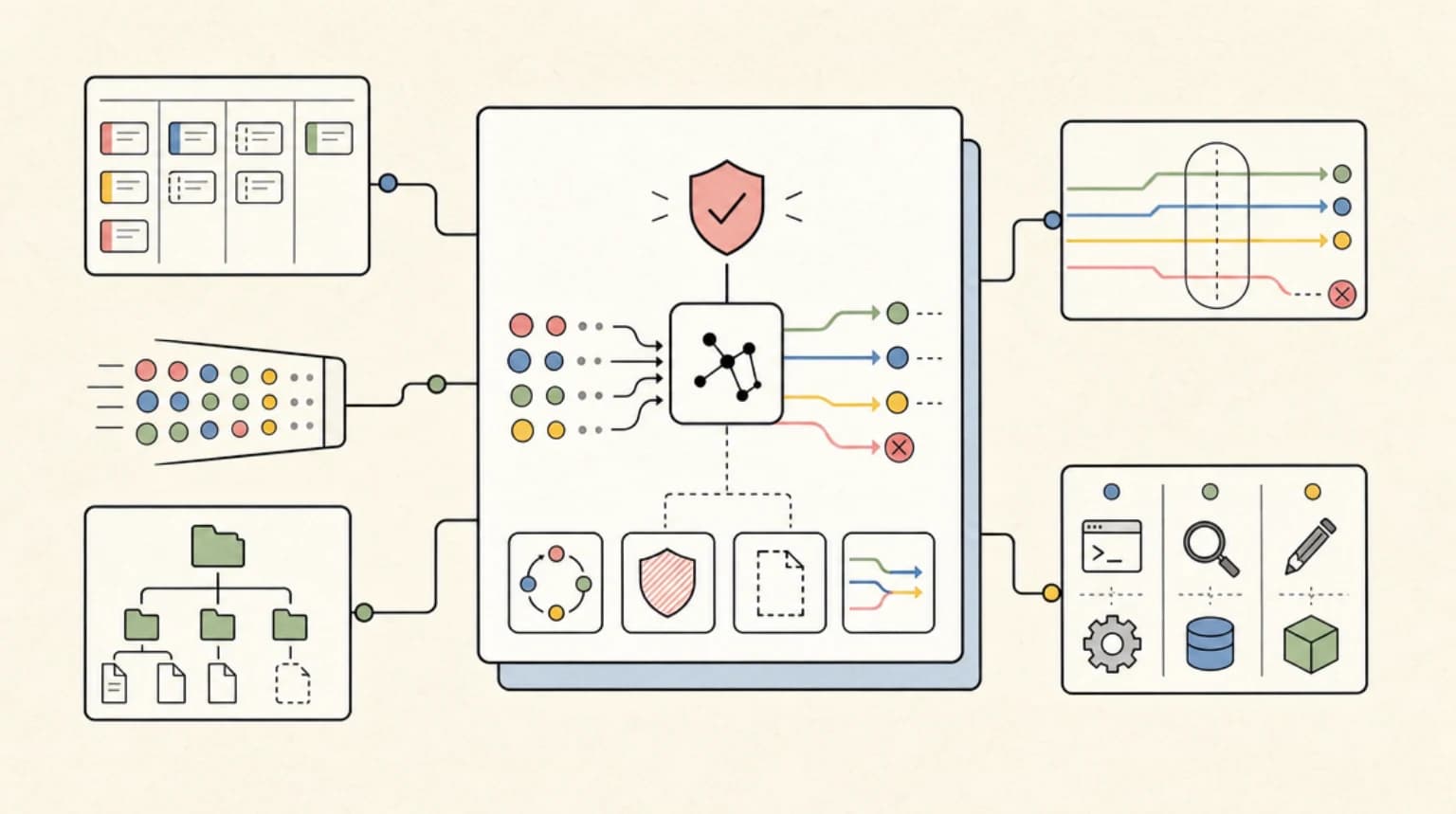
Effort levels and model choice both cost more for more capability, but they are not interchangeable. Here is when to move the effort dial and when to switch models instead.
Read more