//
Orchestrating a Fleet of Agents with Fable 5
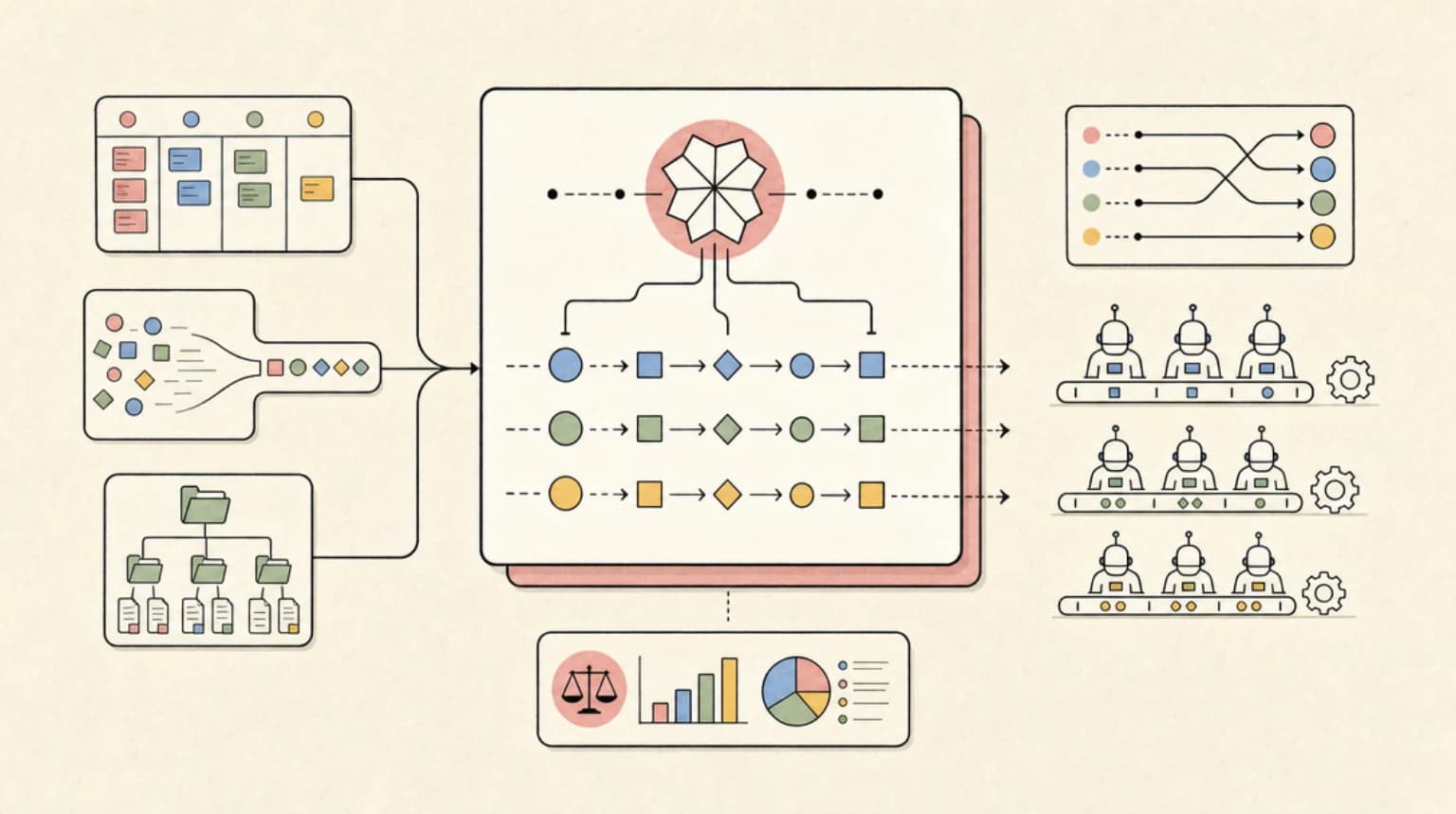
TL;DR
Fable 5 changes multi-agent orchestration because the orchestrator can now hold the whole project in one head. Here is the manager-model pattern: a 1M-context frontier model leading, delegating scoped work to cheaper workers, and verifying results.
Part 1 of the Fable 5 agent fleets series. Start with Fable 5 Is Back: The Anthropic Model the Government Switched Off for the model background, then read Part 2, The Economics of Agent Fleets, for the cost math.
Most multi-agent setups fail in the same place. Not the workers - the manager. You fan out ten agents, they each do a reasonable job on their slice, and then the results do not fit together because nothing held the whole picture. The orchestrator ran out of context, lost the plan, or never had a strong enough model to keep the threads straight.
Fable 5 changes the shape of that problem. With a 1M token context window, always-on adaptive thinking, and a set of API primitives built for long-horizon work, the orchestrator can now hold the entire project in one head. That single fact reshapes how you design a fleet. This post is the applied version: the manager-model pattern, why orchestrator quality dominates fleet output, and where each Fable 5 primitive actually fits.
Why orchestrator quality dominates fleet output
In a fleet, the worker agents are interchangeable and cheap. The orchestrator is not. It decides what to build, how to split it, which worker gets which slice, whether the returned work is correct, and what to do next. Every one of those decisions compounds. A worker that produces a mediocre function costs you one function. An orchestrator that mis-plans the architecture costs you the whole run. For the full catalog of coordination patterns a fleet leans on, see how to coordinate multiple AI agents.
This is why the manager-model pattern puts your strongest model at the top. Anthropic positions Fable 5 as its most capable widely released model, above Opus 4.8, and frames the pitch simply: the longer and more complex the task, the bigger its lead (see the launch post). Orchestration is exactly that kind of task. It is long-horizon, it accumulates state, and a small early error propagates through everything downstream. If you are going to spend on one expensive model in your fleet, spend it on the one making the decisions.
Context as coordination memory
The reason orchestration used to be hard is that coordination state grows fast. The plan, the task list, what each worker returned, which pieces passed verification, what still needs doing - that is a lot of tokens, and it grows with every delegation round. Older orchestrators had to compress or drop that history, and every compression is a chance to lose the thread.
Fable 5's 1M token context turns coordination memory from a scarce resource into an abundant one. You can keep the whole repo, the original spec, the running task ledger, and the transcript of every worker result in the orchestrator's context at once. The manager does not have to reconstruct what happened three steps ago from a summary. It reads it directly.
A few practical consequences:
- The repo fits in the manager's head. For most codebases, you can put the relevant tree and key files directly in context, so the orchestrator plans against the actual code rather than a description of it.
- The task ledger is durable. Instead of a fragile external state machine, the running plan and its status can live in the context itself, updated as work completes.
- Worker outputs stay reviewable. When a worker returns a diff, the orchestrator still has the original requirements in context to check it against.
For work that outlives a single context window, Fable 5 also exposes a file-based memory tool plus context editing and compaction primitives. Anthropic reports that file-based memory tripled long-task gains versus Opus 4.8 on its internal evaluations (vendor-reported, from the launch post). For an orchestrator, that memory is where the coordination ledger lives when the run is long enough that even 1M tokens is not enough - the manager writes plan state to files and reads it back across compaction boundaries.
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
Running Fable 5 Agent Fleets in Production: The Operations Guide
Jul 1, 2026 • 8 min read
Fable 5 Is Back: The Anthropic Model the Government Switched Off
Jul 1, 2026 • 6 min read
Godot Bans AI-Authored Code Contributions - What It Means for Open Source
Jul 1, 2026 • 6 min read
The MCP 2026-07-28 Rewrite: What Breaks and How to Migrate
Jul 1, 2026 • 11 min read
The delegation patterns
Once the orchestrator can hold the whole picture, the useful patterns are straightforward. Three cover most fleets.
Fan-out
The manager decomposes a task into independent slices and dispatches them to workers in parallel. This is the classic case: refactor twelve modules, write tests for eight files, draft ten content pieces. The orchestrator's job is the decomposition (making the slices genuinely independent so they do not conflict) and the reassembly (merging results into a coherent whole). The 1M context matters here because the manager has to hold every returned slice at once to integrate them without contradictions.
Pipeline
Workers run in sequence, each consuming the previous stage's output: research, then draft, then critique, then revise. The orchestrator owns the handoffs and decides whether each stage's output is good enough to advance. Pipelines are where a weak orchestrator quietly fails - it passes bad output downstream because it never really checked. A strong manager with the full spec in context can gate each stage.
Verify loops
The pattern that separates a real fleet from a fancy prompt chain. After a worker returns, the orchestrator verifies the result against the original requirements and either accepts it, sends it back with specific feedback, or re-scopes the task. This is where orchestrator quality pays off most directly, because verification is a judgment task and judgment is what the frontier model is for. A worker can write the code. Deciding whether the code is actually correct, complete, and consistent with everything else is the manager's job.
In practice you compose these. A realistic build fans out an initial batch of independent work, runs each result through a verify loop, then pipelines the verified pieces into an integration stage. The orchestrator is the only component that sees all of it.
Where the effort parameter fits
Fable 5's adaptive thinking is always on - you cannot disable it, you tune its depth with the effort parameter (see the model docs). In an orchestration context, effort is a dial you set per decision type, not once for the whole run.
- High effort for planning and verification. Decomposing a task well, catching a subtle inconsistency between two workers' outputs, deciding whether a returned diff is actually correct - these are the decisions where deeper thinking earns its cost. This is the orchestrator's core loop, and it is worth the tokens.
- Low effort for mechanical steps. Dispatching an already-planned task, formatting a result, updating the ledger with a status - these do not need deep reasoning. Turning
effortdown on the routine steps keeps the orchestrator affordable without dulling its judgment where judgment matters.
The mental model: spend thinking depth where a wrong answer is expensive and cheap out where it is not. Because Fable 5 also supports task budgets (in beta) and programmatic tool calling, the orchestrator can dispatch and coordinate worker calls as part of its own reasoning loop rather than round-tripping every decision back to your application code. That keeps the manager's view of the fleet continuous.
What this does not fix
The manager-model pattern raises the ceiling on fleet quality. It does not remove the parts you still have to engineer. You still have to make fan-out slices genuinely independent, or the merge conflicts. You still have to write verification criteria the orchestrator can actually check against, because a verify loop with vague criteria just launders bad work. And you still have to handle Fable 5's refusal behavior: its safety classifier can return stop_reason: "refusal" as a normal 200 response, and with the post-return classifier producing more false positives on benign coding, an orchestrator that ignores refusals will treat a blocked step as a silent success. Build the fallback to Opus 4.8 into the orchestrator loop from day one. We cover that behavior in more depth in the returns post.
The shift is real, though. When your manager can hold the whole project in one context and reason deeply about every coordination decision, the fleet stops failing at the top. The workers were rarely the problem. The manager was.
Frequently Asked Questions
Why use Fable 5 as the orchestrator instead of the workers?
Because orchestration decisions compound and worker output does not. The manager decides the plan, the delegation, and the verification, and a small early error there propagates through the whole run. Fable 5 is Anthropic's most capable widely released model and its lead grows with task length and complexity, which is exactly the orchestrator's job profile. Workers do bounded, scoped tasks where a cheaper model is usually enough.
How does the 1M context window change multi-agent design?
It turns coordination memory from a scarce resource into an abundant one. The orchestrator can keep the repo, the original spec, the running task ledger, and every worker's returned output in context at once, so it plans and verifies against the real state instead of a lossy summary. For runs that outlive a single window, the file-based memory tool plus context editing and compaction carry the ledger across boundaries.
What is the effort parameter and how should an orchestrator use it?
Fable 5's adaptive thinking is always on and cannot be disabled; effort tunes how deep it thinks. In a fleet, set it per decision type: high effort for planning and verification, where a wrong answer is expensive, and low effort for mechanical steps like dispatching a pre-planned task or updating the ledger. It is a per-decision dial, not a single run-wide setting.
Do I still need to handle refusals in an orchestrator?
Yes. Fable 5's safety classifier can return stop_reason: "refusal" as a normal 200, not an error, and the post-return classifier produces more false positives on benign coding. An orchestrator that only checks for HTTP errors will read a refused step as a silent success and pass broken state downstream. Wire a fallback to Opus 4.8 into the orchestrator loop from the start.
Sources
- Anthropic, Claude Fable 5 and Claude Mythos 5 (launch, vendor-reported benchmarks and memory claims)
- Anthropic, Redeploying Fable 5
- Anthropic Docs, Introducing Claude Fable 5 and Claude Mythos 5
- Developers Digest, Fable 5 Is Back: The Anthropic Model the Government Switched Off
- Developers Digest, The Economics of Agent Fleets: Fable 5 Orchestrators, Sonnet 5 Workers
Read next
Fable 5 vs Opus 4.8: Which Should Orchestrate Your Agents?
The orchestrator is the most important model choice in an agent fleet. A fair head-to-head between Fable 5 and Opus 4.8 for that role, with a decision matrix by run length, budget, compliance, and refusal-handling tolerance.
8 min readRefusals at Fleet Scale: Building Fable 5 Agents That Do Not Silently Fail
Fable 5 refusals come back as a 200 response, not an error. At fleet scale, that quietly corrupts entire runs. Here is how to detect, fall back, and treat refusal rate as a health metric.
9 min readLong-Horizon Agents: What Fable 5's 1M Context and Memory Actually Unlock
1M context, 128K output, a memory tool, compaction, and task budgets change what a single agent run can cover. Here is what is verified, what is plausible, and six projects builders can try now.
9 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI ModelsNew
Claude Fable 5
Anthropic's first generally available Mythos-class model, released June 9, 2026. 1M context, 128K max output, $10/$50 pe...
View ToolAI Frameworks
LangChain / LangGraph
Most popular LLM framework. 100K+ GitHub stars. Chains, RAG, vector stores, tool use. LangGraph adds stateful multi-agen...
View ToolAI Frameworks
Composio
Gives AI agents access to 250+ external tools (GitHub, Slack, Gmail, databases) with managed OAuth. Handles the auth and...
View ToolAI Frameworks
OpenAI Agents SDK
Lightweight Python framework for multi-agent systems. Agent handoffs, tool use, guardrails, tracing. Successor to the ex...
View ToolApps from Developers Digest
SaaS Products
Overnight Agents
Spec out AI agents, run them overnight, wake up to a verified GitHub repo.
View AppDeveloper ToolsIn Progress
Agent Benchmark Lab
Compare AI coding agents on reproducible tasks with scored, shareable runs.
View AppDeveloper ToolsIn Progress
Workflow Autopilot Builder
Define AI-assisted business automations without locking the workflow to one vendor.
View AppRelated Guides
Guide
AGENTS.md - Claude Code
Define custom subagent types within your project's memory layer.
Claude CodeGuide
Subagents - Claude Code
Spawn isolated workers with independent context windows.
Claude CodeGuide
Routines (Web) - Claude Code
Managed scheduling on Anthropic infrastructure with API and GitHub triggers.
Claude CodeRelated Videos

Agents 101: How to Build and Deploy Anything with AI Agents
Build Anything with Vercel, the Agentic Infrastructure Stack Check out Vercel: https://vercel.plug.dev/cwBLgfW The video shows a behind-the-scenes walkthrough of how the creator rapidly builds and d
Video·

Building Effective AI Agents with VectorShift
In this video, I demonstrate how to use VectorShift to build AI applications and workflows. By applying ideas from Anthropic's blog post 'Building Effective Agents,' I show you how to create...
Video·

Build No-Code AI Agents, Automations and Apps with VectorShift
No-Code AI Automation with VectorShift: Integrations, Pipelines, and Chatbots In this video, I introduce VectorShift, a no-code AI automation platform that enables you to create AI solutions...
Video·
Related Posts
8 min read
Fable 5
Running Fable 5 Agent Fleets in Production: The Operations Guide
Standing up a fleet of Fable 5 agents is the easy part. This is the operations layer - data retention rules, refusal-rat...
9 min read
AI Agents
Running Fable 5 Agents on Vercel's eve Framework
Vercel's eve gives you the agent plumbing - durable sessions, sandboxed code execution, approvals, subagents - as a fold...
8 min read
Fable 5
Fable 5 vs Opus 4.8: Which Should Orchestrate Your Agents?
The orchestrator is the most important model choice in an agent fleet. A fair head-to-head between Fable 5 and Opus 4.8...
9 min read
Fable 5
Refusals at Fleet Scale: Building Fable 5 Agents That Do Not Silently Fail
Fable 5 refusals come back as a 200 response, not an error. At fleet scale, that quietly corrupts entire runs. Here is h...
9 min read
Fable 5
Long-Horizon Agents: What Fable 5's 1M Context and Memory Actually Unlock
1M context, 128K output, a memory tool, compaction, and task budgets change what a single agent run can cover. Here is w...
8 min read
Fable 5
The Economics of Agent Fleets: Fable 5 Orchestrators, Sonnet 5 Workers
One expensive orchestrator plus many cheap workers beats an all-frontier fleet for most workloads. Here is the decision-...
Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever