//
AI's Affordability Crisis Is Really an Agent Cost Accounting Problem
TL;DR
A viral Hacker News thread about AI affordability points at the right problem, but developer teams need a more useful cost model: retries, cache misses, review time, routing, and failed loops.
The Hacker News thread around AI's Affordability Crisis is popular because it says the quiet part out loud: a lot of AI economics still do not feel settled.
Cloud GPU supply is expensive. Frontier training is expensive. Inference is cheaper than it was, but not cheap enough to make every agent loop feel disposable. Token prices keep moving, vendors keep reshaping plans, and teams are trying to decide whether to buy subscriptions, call APIs directly, route across providers, or self-host open weights.
That is the public argument.
For developer teams, the more useful question is smaller:
What are you actually paying for when an AI agent does work?
Last updated: June 23, 2026
The answer is not just "tokens." Tokens are the easiest line item to see, but the real bill includes retries, tool calls, failed runs, cache misses, latency, GPU availability, human review, incident cleanup, and the opportunity cost of waiting for a stuck agent to finish.
This is why the affordability debate matters. It is not a generic complaint that AI is expensive. It is a reminder that agent systems need cost accounting at the workflow level.
Sticker Price Is the Wrong Unit
Most pricing pages teach teams to think in dollars per million tokens or dollars per seat. That is necessary, but it is not enough.
For normal chat, per-token pricing is a decent approximation. For agentic work, it hides the part that matters.
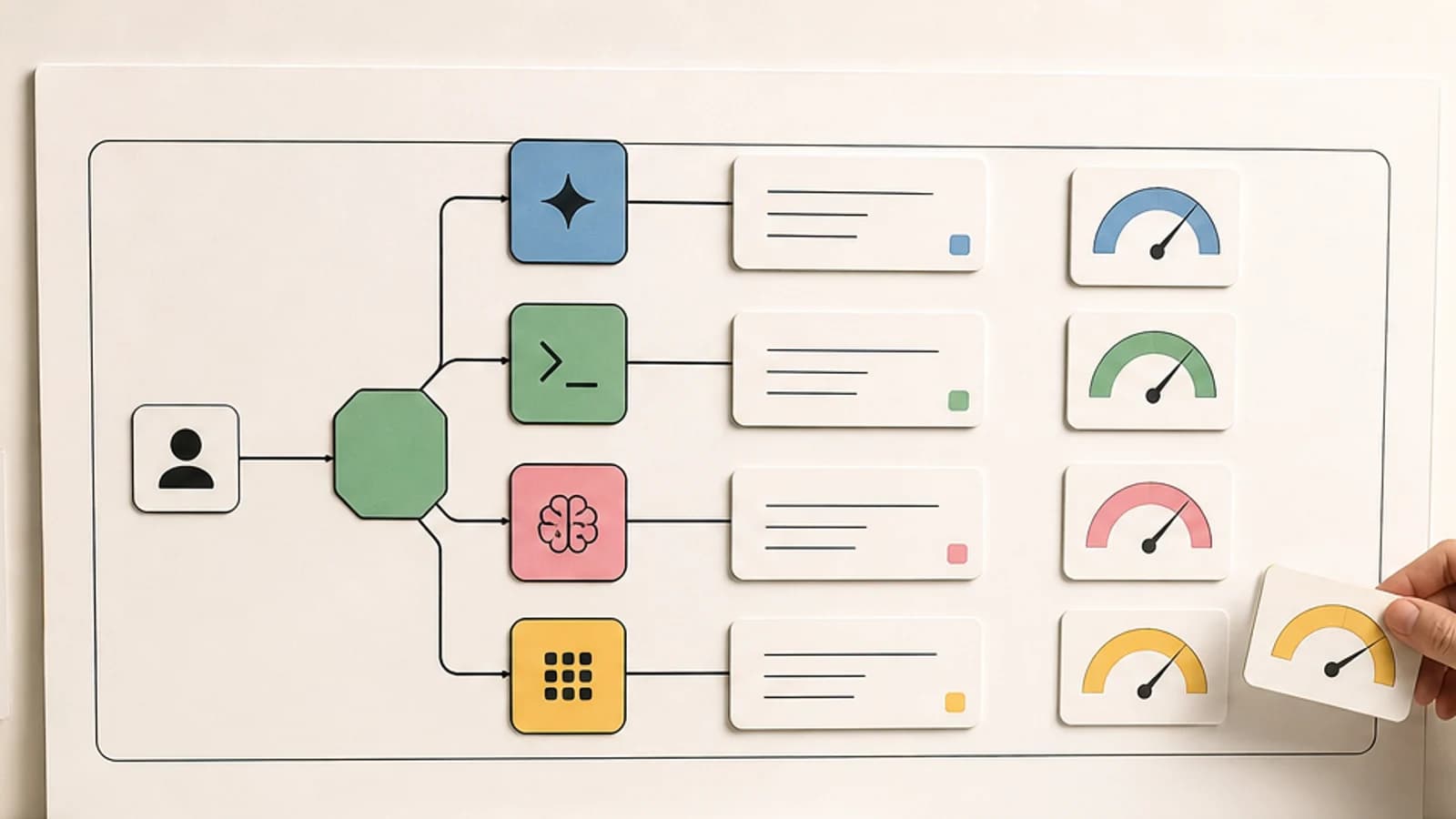
An agent run has at least five cost surfaces:
| Cost Surface | What It Measures |
|---|---|
| Model cost | input, output, cached input, batch discounts |
| Runtime cost | session hours, containers, browsers, sandboxes, GPUs |
| Retry cost | loops, failed tool calls, reruns, escalations |
| Review cost | human time spent reading, validating, and fixing output |
| Reliability cost | incidents, wrong changes, broken builds, stale context |
The cheap model is not cheap if it needs three attempts. The expensive model is not expensive if it finishes once and saves a senior engineer an hour. The hosted plan is not predictable if a background agent can run all night. The self-hosted model is not free if it needs GPU ops, utilization tuning, and debugging.
That is the missing unit: cost per accepted outcome.
The Developer Cost Model
Before cutting model spend, measure the workflow.
For every serious agent path, log these fields:
| Metric | Why It Matters |
|---|---|
| task type | bug fix, code review, research, migration, test repair |
| model route | which model started, which model escalated, which provider served it |
| input tokens | context size, cacheable prefix, retrieved chunks |
| output tokens | answer size, patch size, tool chatter |
| cache hit rate | whether stable context is actually being reused |
| attempts | how many agent runs were needed before acceptance |
| wall time | latency plus tool time plus queue time |
| human review minutes | the cost most dashboards ignore |
| outcome | accepted, edited, rejected, abandoned, reverted |
This turns "AI is expensive" into a measurable system question.
If output tokens dominate, tune prompts and stop verbose tool chatter. If retries dominate, improve harnesses and tests. If review time dominates, improve receipts and diffs. If cache misses dominate, stabilize prefixes. If every task escalates to the frontier model, your router is not routing.
We covered the implementation side in model routing recipes to cut AI spend, but the principle is broader: you cannot optimize what you only measure at the invoice level.
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
Armin Ronacher on The Coming Loop and Why Agent-Driven Code Still Needs Human Comprehension
Jun 23, 2026 • 9 min read
Cerebras Stock Is a Public Test of AI Inference Demand
Jun 23, 2026 • 7 min read
Claude Outages Are a Workflow Design Problem
Jun 23, 2026 • 7 min read
Anthropic Claude Tag Turns Slack Into a Shared Agent Workspace
Jun 23, 2026 • 8 min read
The Four Mistakes That Make Agents Feel Unaffordable
1. Treating Every Task as Frontier Work
Not every task deserves the best model.
A docs summary, changelog draft, import rename, or test snapshot update should not start on the same route as a hard architecture migration. If your system cannot classify task difficulty, it will use premium capacity as the default.
The practical pattern:
- Start routine tasks on a cheaper workhorse route.
- Escalate only when there is a measurable failure signal.
- Keep the original attempt in the trace.
- Compare cost per accepted task, not cost per call.
That last point matters. A cheaper first pass that reliably filters easy work can reduce total cost even if the hard cases still escalate.
2. Ignoring Cache Hit Rate
Agent runs resend the same context constantly: system instructions, repo conventions, tool docs, project summaries, and stable file context. If that prefix changes every time, you lose the main discount structure vendors are building around long-context workflows.
A healthy agent setup should know:
- what part of the prompt is stable
- whether the stable prefix is identical across turns
- how often cached input is actually hit
- whether tools are adding noisy context ahead of the cache boundary
This is why DeepSeek's cache-first agent pattern is more than a cheap-token story. Cache design is a harness feature. Bad prompt assembly can erase the discount before the model sees the task.
3. Counting Tokens But Not Review Time
A model bill is easy to export. Review time is not.
But for developer teams, review time is often the larger cost. If an agent creates a 2,000-line diff that technically works but takes 90 minutes to trust, the low token price did not save much.
Track review time as a first-class field:
- time to understand the diff
- time to run or repair tests
- number of reviewer comments
- number of follow-up agent turns
- whether the work was merged, rewritten, or reverted
This is the same lesson from the $400 overnight agent bill: uncontrolled work is not only expensive because tokens burn. It is expensive because someone has to untangle the result.
4. Moving to Self-Hosting Too Early
Self-hosting open weights can be the right move at sustained volume. It can also turn a pricing problem into an operations problem.
The break-even math depends on:
- utilization
- batchability
- latency targets
- hardware depreciation
- serving stack maturity
- on-call tolerance
- quality difference versus hosted APIs
If your workload is bursty, hosted APIs may stay cheaper because someone else eats the idle capacity. If your workload is steady, predictable, and privacy-sensitive, self-hosting starts to make sense.
The open-weights self-hosting break-even guide is the right companion here. The trap is deciding from ideology instead of utilization.
What to Do This Week
If you are worried about AI affordability, do not start by banning expensive models.
Start with a one-week audit:
| Day | Action |
|---|---|
| Day 1 | Add task IDs to every agent run |
| Day 2 | Log model route, tokens, cache reads, and runtime |
| Day 3 | Add accepted, edited, rejected, and reverted outcomes |
| Day 4 | Sample 20 tasks and record human review minutes |
| Day 5 | Sort by cost per accepted task |
The result will usually show one of three problems.
First, you have a routing problem: too much easy work starts on the premium path.
Second, you have a harness problem: retries and failed tool calls dominate cost.
Third, you have a review problem: the agent produces work that is expensive to trust.
Each problem has a different fix. Pricing pages do not tell you which one you have.
My Take
AI affordability is real, but for developers it is not just a macro argument about GPUs and vendor margins.
It is an operating discipline.
Teams that only stare at per-token rates will make blunt decisions: downgrade the model, cancel seats, self-host too early, or route everything through the cheapest endpoint. Some of those moves will help. Some will quietly move cost into retries, review, latency, and maintenance.
The better move is to price the whole workflow.
Cost per accepted patch. Cost per resolved ticket. Cost per reviewed migration. Cost per support handoff. Cost per successful document extraction. That is the level where the affordability crisis becomes actionable.
The winners will not be the teams that use the cheapest model everywhere. They will be the teams that know when cheap is enough, when expensive is worth it, and when the right answer is to stop the loop before it spends another hour pretending to make progress.
FAQ
What is the AI affordability crisis?
The current affordability debate is about whether AI systems can become cheap enough for broad, sustained use given training costs, inference costs, GPU supply, energy use, and vendor pricing. For developer teams, the practical version is whether agents create enough accepted work to justify their total workflow cost.
Why are token prices not enough for agent cost planning?
Agent work includes retries, tool calls, runtime, cache misses, human review, and failure recovery. A low token price can still produce an expensive workflow if the model needs repeated attempts or creates output that takes too long to trust.
What metric should engineering teams use instead?
Use cost per accepted outcome. For coding agents, that may mean cost per merged patch, cost per resolved issue, or cost per accepted review. Include model spend, runtime, retries, and human review time.
Should teams switch to cheaper models?
Sometimes. Start by routing easier tasks to cheaper models and escalating on measurable failure signals. Do not move everything blindly. A cheap model that needs multiple retries can cost more than a stronger model that finishes once.
When does self-hosting make sense?
Self-hosting makes sense when volume is sustained, utilization is high, data constraints matter, and your team can operate the serving stack. For bursty workloads, hosted APIs often remain cheaper because they avoid idle GPU capacity and operational overhead.
Sources
Fetched June 23, 2026.
Read next
Model Routing Recipes: Practical Config Patterns to Cut AI Spend
A code-heavy field guide to model routing. Real, runnable-style configs for tiering tasks by complexity, routing simple work to open-weights, reserving frontier models for hard reasoning, building failover chains, and keeping prompt caches warm with OpenRouter, LiteLLM, and Factory Router.
11 min readSelf-Hosting Open-Weights Models: The Real Break-Even Math
Open weights are free to download, but inference is not free to run. Here is the honest break-even math on when self-hosting GLM-5.2, DeepSeek V4, or Llama beats paying per-token API prices - GPU rental and ownership costs, real throughput, utilization, the crossover in tokens per month, and the hidden ops bill nobody budgets for.
11 min readReasonix Shows the Next Coding Agent Fight Is Cache Discipline
Reasonix hit Hacker News with a DeepSeek-native pitch: keep long coding sessions cheap by designing the agent loop around prefix caching. The interesting question is when cache efficiency helps quality, and when it fights the harness.
7 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI CodingAgent
OpenAI Codex
OpenAI's coding agent for terminal, cloud, IDE, GitHub, Slack, and Linear workflows. Reads repos, edits files, runs comm...
View ToolAI Frameworks
Composio
Gives AI agents access to 250+ external tools (GitHub, Slack, Gmail, databases) with managed OAuth. Handles the auth and...
View ToolAI Frameworks
OpenAI Agents SDK
Lightweight Python framework for multi-agent systems. Agent handoffs, tool use, guardrails, tracing. Successor to the ex...
View ToolAI ModelsDaily Driver
Claude
Anthropic's AI. Opus 4.6 for hard problems, Sonnet 4.6 for speed, Haiku 4.5 for cost. 200K context window. Best coding m...
View ToolApps from Developers Digest
Developer ToolsPlus $20/mo
Cost Tape Cloud
Know what each agent run cost before the bill arrives. Budgets and alerts included.
View AppSaaS Products
Overnight Agents
Spec out AI agents, run them overnight, wake up to a verified GitHub repo.
View AppDeveloper Tools
Agent Hub
Every coding agent in one window. Stop alt-tabbing between Claude, Codex, and Cursor.
View AppRelated Guides
Guide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsGuide
MCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
AI AgentsGuide
Claude Code Complete Course
A complete, citation-backed Claude Code course with setup, prompting systems, MCP, CI, security, cost controls, and capstone workflows.
ai-developmentRelated Videos

Related Posts

11 min read
pricing
Model Routing Recipes: Practical Config Patterns to Cut AI Spend
A code-heavy field guide to model routing. Real, runnable-style configs for tiering tasks by complexity, routing simple...

11 min read
pricing
Self-Hosting Open-Weights Models: The Real Break-Even Math
Open weights are free to download, but inference is not free to run. Here is the honest break-even math on when self-hos...

7 min read
AI Coding
Reasonix Shows the Next Coding Agent Fight Is Cache Discipline
Reasonix hit Hacker News with a DeepSeek-native pitch: keep long coding sessions cheap by designing the agent loop aroun...

13 min read
AI Agents
The $400 Overnight Bill: Why Managed Agents Need FinOps Now
Five managed-agent providers, five pricing models, zero unified cost attribution. If you're running agents overnight, yo...

9 min read
pricing
AI Coding Tools Pricing: The June 2026 Reality Check
Every major AI coding tool just went through a pricing shift. Here are the exact numbers for Cursor, GitHub Copilot, Cla...
8 min read
GitHub Copilot
GitHub Copilot CLI, BYOK, and AI Credits: The New Cost-Control Stack
GitHub's June Copilot updates point beyond autocomplete: CLI access, bring-your-own-key model routing, AI credit metrics...

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever