Multi-Stream LLMs Hint at the Next Agent Architecture
TL;DR
The Multi-Stream LLMs paper argues that agents are bottlenecked by single chat streams. The practical takeaway is not to rebuild everything today, but to design agent runtimes around separated channels.
The Multi-Stream LLMs paper is worth reading because it pokes at a design assumption most agent products still inherit from chat.
Even advanced coding agents usually run through one sequence of messages. The user speaks, the model thinks, the model calls a tool, the tool responds, the model writes, and the loop continues. Everything is serialized into one stream.
The paper argues that this is a bottleneck. A model cannot read while writing. It cannot act while thinking. It cannot update an answer while new tool output arrives. It cannot keep system instructions, private reasoning, tool observations, and user-facing output as truly separate channels.
That is a research claim, not a product you can drop into your stack this afternoon. But the design pressure is real.
If long-running agents need harnesses, then the next harness probably needs multiple channels.
The Chat Loop Is Doing Too Much
Today's agent runtimes make a single transcript carry too many jobs:
- user intent,
- system policy,
- tool results,
- planning notes,
- hidden or visible reasoning,
- file diffs,
- status updates,
- final output.
That works surprisingly well for short tasks. It gets awkward for real development work.
A coding agent may need to keep reading logs while drafting a fix. A browser agent may need to watch the page while it writes a test. A reviewer agent may need to separate policy checks from implementation notes. A security agent may need to keep exploit analysis away from user-visible summary text.
We approximate this today with conventions: tool messages, scratchpads, status logs, subagents, task queues, and structured outputs. The paper's useful provocation is that these should be model-level streams, not just formatting tricks.
What Multi-Stream Means
The authors propose instruction-tuning language models for multiple parallel streams of computation. In their framing, every forward pass can read from multiple input streams and generate tokens into multiple output streams, with causal dependency across earlier timesteps.
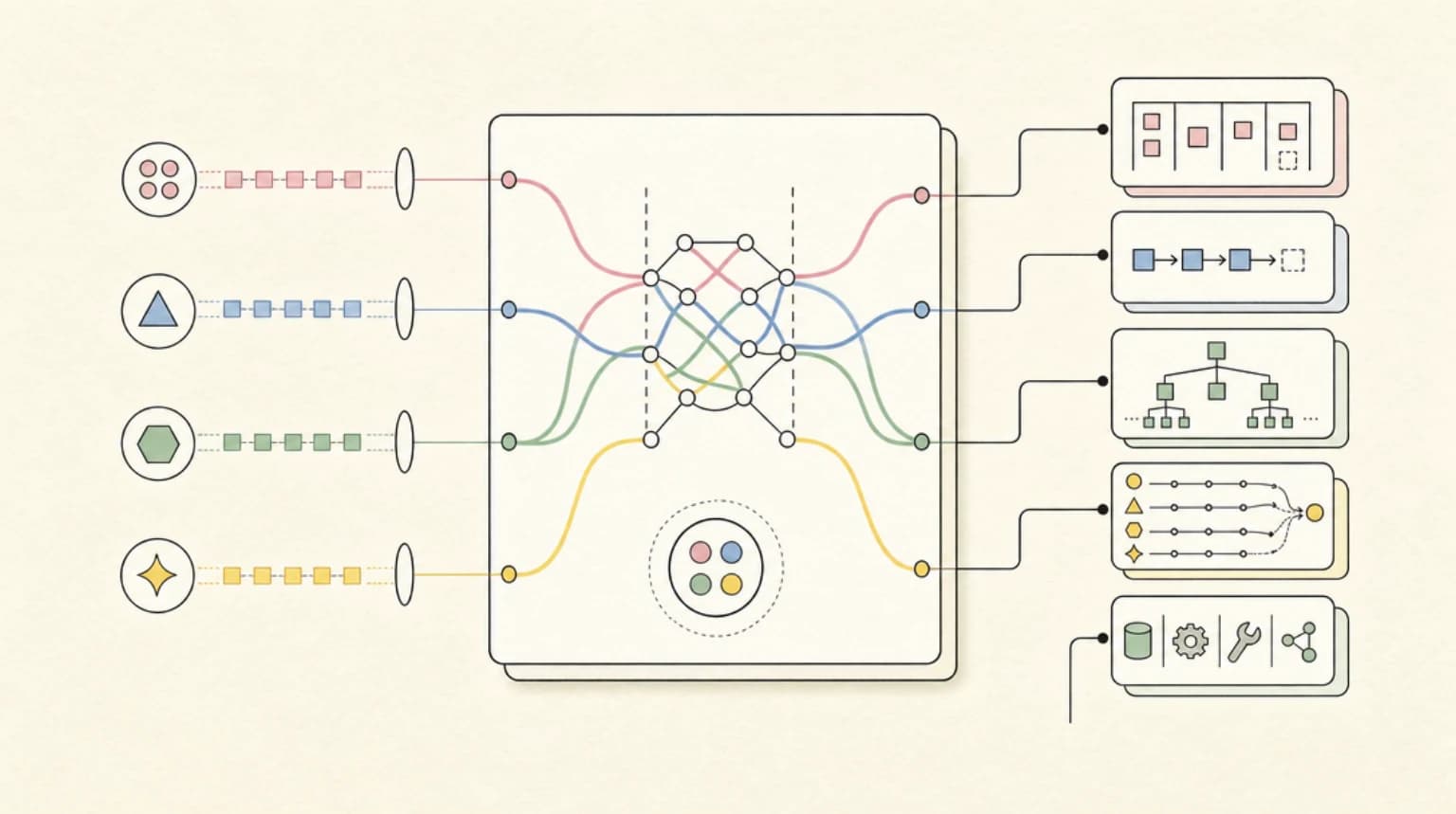
The practical promise is threefold:
- Better efficiency through parallelization.
- Better separation of concerns for security.
- Better monitorability because different streams can be inspected independently.
That maps cleanly onto agent infrastructure.
For example, a coding agent runtime could separate:
user: the task and clarifications,policy: allowed files, network rules, approval gates,tools: command output and browser observations,plan: private task decomposition,diff: code edits,status: short human-readable progress,final: the answer.
You can simulate some of this with today's APIs, but the model still consumes and emits through a mostly sequential loop. Multi-stream training would make the separation native.
The Opposing Take
The skeptical view is that this is overkill.
Most production agent failures are not caused by single-stream architecture. They are caused by weak prompts, bad context selection, missing tests, permissive credentials, unclear task scope, and humans trusting summaries without receipts.
That is true.
You do not need a new model architecture to improve your agent workflow today. You need smaller tasks, better tool logs, stricter review, and clearer context boundaries. The agent context reduction pattern still matters more than speculative model plumbing for most teams.
But research like this matters because it points to where current workarounds are trying to go.
Subagents are a workaround for parallel streams. Tool messages are a workaround for observation streams. Hidden reasoning fields are a workaround for thinking streams. Structured output is a workaround for final-channel discipline. The market is already asking for separation; the model interface just has not caught up.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Claude Code's Official Plugin Marketplace Is Here - and It's Already at 23k Stars
May 22, 2026 • 5 min read
Sandboxed Agents Are Becoming the Team Control Plane
May 22, 2026 • 8 min read
Forge Shows the Local Agent Reliability Gap Is a Harness Problem
May 20, 2026 • 7 min read
Anthropic Buying Stainless Is About Agent Plumbing
May 19, 2026 • 8 min read
Design for Channels Now
You do not have to wait for multi-stream models to build better agents.
Design your runtime as if channels are real:
- Keep policy separate from task text.
- Store tool output separately from final summaries.
- Keep status updates short and observable.
- Make diffs and test results first-class artifacts.
- Avoid mixing untrusted web content into the same prompt region as instructions.
- Log every channel with timestamps and task IDs.
This makes today's agents safer and tomorrow's agents easier to adopt.
It also clarifies product design. A good agent UI should not be one giant transcript. It should show the human the right stream at the right moment: plan when approving, diff when reviewing, logs when debugging, final output when closing the task.
That is why terminal agents need a portable runtime surface. The agent is not just text. It is a bundle of streams, files, tools, and decisions.
What to Watch
The near-term signal is not whether every provider ships a multi-stream model. Watch for interfaces that make streams more explicit:

- separate reasoning or planning channels,
- live status streams,
- structured tool observation stores,
- richer task traces,
- parallel subagent APIs,
- review UIs that separate diff, log, and summary.
OpenAI's recent Codex release notes mention richer context, goal mode, browser improvements, and remote locked use. Those are product-level moves toward longer-running, context-aware work. Multi-stream research is the model-level version of the same pressure.
The Take
The future of agents probably looks less like one chat window and more like an operating surface with channels.
The mistake would be waiting for a new architecture before improving your workflow. The better move is to make channel boundaries explicit now: policy, tools, plan, diff, status, and final answer.
If multi-stream models arrive, your runtime will be ready. If they do not, your agents will still be easier to debug.
Official Sources
| Resource | Link |
|---|---|
| Multi-Stream LLMs Paper | arxiv.org/abs/2605.12460 |
| OpenAI Codex Release Notes | help.openai.com/en/articles/6825453-chatgpt-release-notes |
| Anthropic Tool Use Docs | docs.anthropic.com/en/docs/build-with-claude/tool-use |
| LangGraph Agent Patterns | langchain-ai.github.io/langgraph |
FAQ
What is the multi-stream LLM architecture?
Multi-stream LLM architecture is a research concept where language models can read from and write to multiple parallel streams of computation simultaneously. Instead of a single sequential chat transcript, the model processes separate channels for instructions, tool observations, planning, status updates, and final output. This allows better parallelization, clearer separation of concerns, and improved monitoring for agent systems.
Why does the single-stream chat loop limit AI agents?
Current AI agents serialize everything into one message sequence - user intent, system policy, tool results, planning notes, reasoning, file diffs, and final output all share the same transcript. This creates bottlenecks: the model cannot read new tool output while writing a response, cannot separate security-sensitive policy from task text, and cannot maintain truly parallel observation and action channels. For long-running tasks, this makes debugging harder and security isolation weaker.
How can I build better agents without waiting for multi-stream models?
Design your agent runtime as if channels are already real. Keep policy separate from task text. Store tool output separately from final summaries. Make status updates short and observable. Treat diffs and test results as first-class artifacts. Avoid mixing untrusted web content into the same prompt region as instructions. Log every channel with timestamps and task IDs. This makes today's agents safer and easier to migrate when multi-stream interfaces arrive.
What is the relationship between multi-stream LLMs and subagents?
Subagents are an existing workaround for parallel streams in current agent architectures. When a primary agent spawns subagents for different tasks, each subagent maintains its own context and outputs, creating a form of channel separation. Multi-stream research suggests making this separation native to the model itself, potentially eliminating the coordination overhead of managing multiple agent instances while achieving better parallelization.
What channels should an agent runtime separate?
A well-designed agent runtime should separate at least six channels: user input and clarifications, policy and allowed actions, tool observations and command output, private planning and task decomposition, code diffs and file changes, human-readable status updates, and final output. This separation improves security by isolating untrusted content, makes debugging easier by providing clear logs per channel, and prepares your architecture for future multi-stream model capabilities.
How does multi-stream architecture improve agent security?
Separating streams creates natural isolation between untrusted content and sensitive instructions. Tool output from web pages or file reads can stay in an observation channel separate from the policy channel controlling what actions are allowed. This reduces prompt injection surface area because the model processes different trust levels in different streams. It also makes security auditing easier since each channel can be logged and reviewed independently.
What should I watch for in agent tooling evolution?
Watch for interfaces that make streams more explicit: separate reasoning or planning channels in model APIs, live status streams in agent UIs, structured tool observation stores, richer task traces with channel separation, parallel subagent APIs, and review interfaces that separate diff, log, and summary views. These product-level moves are leading indicators of where model-level multi-stream capabilities will eventually arrive.
Is multi-stream architecture production-ready today?
No. Multi-stream LLM architecture is a research concept, not a shipped product you can deploy this afternoon. The paper proposes instruction-tuning models for parallel streams, but current production APIs from Anthropic, OpenAI, and others still use sequential message formats. The practical value is in designing your agent runtime around channel separation now, using conventions like tool messages, structured outputs, and status logs to approximate what multi-stream models would provide natively.
Read next
Terminal Agents Are the New Developer Runtime
Terminal agents like Claude Code, Codex CLI, OpenCode, Copilot CLI, and DeepSeek-TUI are converging on the same runtime layer: permissions, sandboxing, rollback, diagnostics, subagents, receipts, and cost controls.
9 min readLong-Running Agents Need Harnesses, Not Hope
A long-running coding agent is only useful if the environment around it can queue tasks, capture logs, checkpoint state, verify behavior, limit cost, and recover from failure.
9 min readThe 98% Context Reduction Pattern
Efficient agents do not stuff every tool result into the model context. They keep intermediate state in code, files, and execution environments, then return compact summaries and receipts.
8 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
Infrastructure
B
Browser Harness
Self-healing browser automation harness that lets LLMs complete any browser task. 5,000+ stars in under a week.
View ToolAI Frameworks
Composio
Gives AI agents access to 250+ external tools (GitHub, Slack, Gmail, databases) with managed OAuth. Handles the auth and...
View ToolAI Frameworks
OpenAI Agents SDK
Lightweight Python framework for multi-agent systems. Agent handoffs, tool use, guardrails, tracing. Successor to the ex...
View ToolAI Frameworks
A
Agency Swarm
Multi-agent orchestration framework built on the OpenAI Agents SDK. Define agent roles, typed tools, and directional com...
View ToolApps from Developers Digest
Related Guides
Guide
Built-in Subagents - Claude Code
Researcher, auditor, reviewer, and other ready-made subagent types.
Claude CodeGuide
Subagent Context Isolation - Claude Code
Prevent bloating the main conversation with research or exploration.
Claude CodeGuide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsRelated Videos

Agents 101: How to Build and Deploy Anything with AI Agents
Build Anything with Vercel, the Agentic Infrastructure Stack Check out Vercel: https://vercel.plug.dev/cwBLgfW The video shows a behind-the-scenes walkthrough of how the creator rapidly builds and d
Video·

TRAE: Custom AI Agents That Actually Understand Your Codebase
Check out Trae here! https://tinyurl.com/2f8rw4vm In this video, we dive into @Trae_ai a newly launched AI IDE packed with innovative features. I provide a comprehensive demonstration...
Video·

FireSearch: An Open-Source Deep Research Template Built with Next.js, Firecrawl and LangGraph
Repo: ⭐ https://github.com/mendableai/firesearch Introducing FireSearch: The Open Source Deep Research Template Built with Next.js, Firecrawl and LangGraph In this video, the creator introduce...
Video·
Related Posts

9 min read
AI Coding
Terminal Agents Are the New Developer Runtime
Terminal agents like Claude Code, Codex CLI, OpenCode, Copilot CLI, and DeepSeek-TUI are converging on the same runtime...

9 min read
AI Agents
Long-Running Agents Need Harnesses, Not Hope
A long-running coding agent is only useful if the environment around it can queue tasks, capture logs, checkpoint state,...

8 min read
Context Engineering
The 98% Context Reduction Pattern
Efficient agents do not stuff every tool result into the model context. They keep intermediate state in code, files, and...

10 min read
AI Agents
7 AI Agent Orchestration Patterns Every Developer Should Know
From single-agent baselines to multi-level hierarchies, these are the seven patterns for wiring AI agents together in pr...

12 min read
Claude API
Tool Use in the Claude API: Production Patterns for Reliable Agents
Master tool use in the Claude API. Schema design, retry logic, multi-step loops, and the failure modes that only show up...
7 min read
AI Agents
Harness Engineering and the Path to Self-Improving AI
Lilian Weng argues self-improving AI won't start with models rewriting their weights — it starts with the harness. Here'...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever