Sandboxed Agents Are Becoming the Team Control Plane

TL;DR
Runtime's Launch HN thread is a useful signal: teams do not just want isolated coding agents. They want a control plane for approvals, secrets, telemetry, review, and merge policy.
Official Sources
| Source | Description |
|---|---|
| Runtime Launch HN | Hacker News launch thread with community Q&A on sandboxed coding agents |
| Runtime Homepage | Official site for Runtime (YC P26) - sandboxed coding agents for teams |
| Runtime Docs | Runtime documentation index covering guardrails, secrets, and observability |
| Claude Managed Agents | Anthropic docs on managed agents with webhooks and telemetry |
| OpenAI Codex Cloud | Codex cloud security and network access documentation |
| GitHub Copilot Agents | GitHub documentation on Copilot coding agent workflows |
Runtime's Launch HN thread is a good snapshot of where coding agents are moving.
The headline is "sandboxed coding agents for everyone on a team." The more interesting signal is in the questions. People asked whether every sandboxed change becomes a pull request, how marketing and data teams get different guardrails, how secrets work when tools expect keys on disk, whether self-hosting matters, and whether static analysis still belongs in the flow.
That is the real category shift.
Last updated: May 23, 2026. If you are choosing tools or trying to map the category, start with /compare, /pricing, and the AI agent frameworks guide.
The winning product is not just a safer place to run an agent. It is a team control plane around agent work: workspace policy, secrets, logs, permissions, context, review, cost, and merge discipline.
This fits the same arc as long-running agents needing harnesses, Claude Managed Agents starting to look like backend jobs, and Codex cloud security becoming an explicit workflow. The model is getting better, but the operational wrapper is becoming the product.
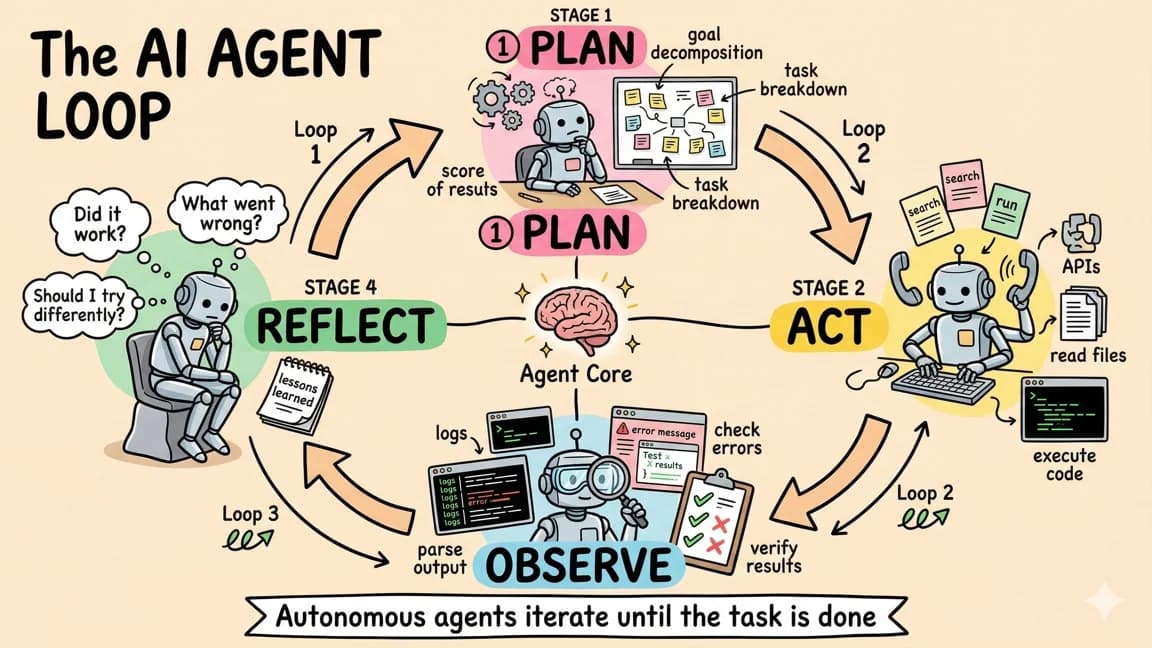
The Sandbox Is the Starting Line
A sandbox solves blast radius.
It gives the agent a contained filesystem, process boundary, network policy, and place to run tests without touching a developer laptop or production system. Runtime's docs describe sessions as sandboxed cloud environments where agents can build, test, and ship code. They also expose concepts for guardrails, observability, organizations, templates, secrets, files, prompts, and team activity (Runtime docs).
That is the important part: the sandbox is one primitive among many.
If you stop at "agent runs in a container," you still have open questions:
- Which repo and branch did it modify?
- Which secrets were visible?
- Which domains could it call?
- Which commands did it run?
- Which policy checked the diff?
- Who approved the merge?
- What happens if the agent got the task wrong?
- Can you replay the run later?
Those questions are not edge cases. They are the product surface.
HN Asked the Right Questions
The Launch HN comments were useful because they skipped the hype layer.

One commenter asked whether every sandbox change ends in a pull request, and what happens if a non-engineering teammate sends a PR the engineer hates. Another asked how guardrails differ by team. Another pointed out that sandboxed execution and static analysis catch different risk classes, so they should be complementary instead of competing. Someone else raised the hard secret-management problem: many useful tools still expect credentials on disk.
That is the right skepticism.
Agent sandboxes are not enough if the output still slides into main with weak review. They are not enough if every team gets the same permissions. They are not enough if a session can read production credentials because a template made onboarding convenient. They are not enough if the only audit trail is a chat transcript.
The practical take is simple: sandboxing controls where the agent can act. A control plane controls whether the result should be trusted.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
The Control Plane Has Five Jobs
For team coding agents, the control plane needs five boring capabilities.
1. Policy by team and task
Marketing agents, data agents, infrastructure agents, and product-engineering agents should not share the same permissions.
The policy should include repository access, branch rules, write permissions, network allowlists, tool permissions, runtime limits, and approval requirements. Runtime's docs expose guardrail concepts around allowlists, hooks, network rules, approvals, RBAC, and audit trails. That is the right mental model.
The mistake is treating "sandboxed" as a universal permission.
2. Secrets that are scoped, visible, and revocable
Agent platforms need a real answer for secrets.
Some tasks need package registry tokens, preview deploy credentials, GitHub tokens, API keys, or cloud credentials. But the agent should not inherit everything a human has on disk. The control plane should separate personal secrets from team secrets, expose only what the task needs, and make it obvious which secret names were available during a run.
This is where agent security content has to move beyond prompt injection. Credential scope is often the more immediate operational failure.
3. Diff review as a first-class state
Every useful coding agent eventually produces a diff.
The control plane should know whether that diff is still a sandbox artifact, a draft branch, a pull request, a merged change, or a rejected change. If a teammate from outside engineering triggers an agent, the result should not be "surprise, here is code." It should be a reviewable artifact with owner, context, tests, trace, and rollback path.
That is why agent swarms need receipts. Parallelism without review discipline just creates more plausible diffs.
4. Static checks next to runtime isolation
Runtime isolation and static analysis solve different problems.
A sandbox can prevent the agent from damaging the host during execution. It does not prove the generated code is secure, maintainable, licensed correctly, or safe to merge. Static analysis, dependency review, secret scanning, test coverage, and code ownership checks still belong in the path.
The strongest workflow is layered:
- Run the agent in a constrained workspace.
- Capture commands, files, and tool calls.
- Run tests and policy checks.
- Open a reviewable PR.
- Require human approval for risky areas.
That is not anti-agent. It is what lets agents run more often.
5. Observability that survives the demo
The control plane should give every run a durable record.
At minimum, that means status, prompt history, command output, changed files, token usage, elapsed time, cost, approvals, errors, and final result. Runtime's docs list activity summaries, traces, team events, session usage, prompt history, and session events. Anthropic's managed-agent webhooks point in the same direction. OpenAI's Codex security docs similarly push teams toward reviewing logs and outputs.
When an agent fails quietly, the trace is the product.
The Opposing Take
The skeptical response is fair: is this just CI, GitHub Actions, and cloud dev environments with an agent bolted on?
Partly, yes.
That is not a dismissal. It is the clue.
The best agent infrastructure will look familiar because teams already know how to operate queues, jobs, logs, policies, approvals, CI checks, and pull requests. What changes is that the worker is now an agent that can interpret tasks, run tools, edit code, ask for help, and revise its own work.
The danger is believing the agent needs a magical new operating model. It mostly needs the old operating model adapted to a worker that writes code.
What Developers Should Watch
Runtime is one example, but the trend is broader. Codex, Claude Code, Claude Managed Agents, GitHub Copilot coding agents, Devin-style cloud environments, and open-source harnesses are all moving toward the same question:

Can a team safely delegate work without losing control of the path to production?
That question is bigger than model quality.
For small teams, the answer might be a simple harness around Codex or Claude Code with worktrees, test commands, and PR templates. For larger teams, it may be a shared control plane with team policies, audit logs, templates, secrets, usage reporting, and integrations with Slack, Linear, GitHub, and CI.
The right choice depends less on which agent writes code fastest and more on which system makes bad outcomes obvious before they merge.
A Practical Checklist
Before giving coding agents to a whole team, require:
- one sandbox or worktree per run
- explicit repo and branch boundaries
- team-specific permissions
- network allowlists
- scoped secrets
- command and file-change logs
- test and typecheck receipts
- static analysis and dependency review
- pull request based merge flow
- human review for protected paths
- cost and runtime limits
- replayable final summaries
That is the baseline for team use.
The future of coding agents is not one agent with unlimited power. It is many agents inside a control plane that makes their work inspectable, constrained, and mergeable.
FAQ
What is a sandboxed coding agent?
A sandboxed coding agent is an AI that writes, tests, and modifies code inside an isolated environment - typically a container or cloud workspace - rather than directly on a developer's machine or production system. The sandbox provides process boundaries, filesystem isolation, network policies, and resource limits that contain the agent's blast radius if something goes wrong.
What is a control plane for coding agents?
A control plane is the operational layer that governs agent work beyond just isolation. It handles team policies, secrets management, approval workflows, observability, cost tracking, merge discipline, and audit trails. While a sandbox controls where an agent can act, a control plane controls whether the result should be trusted and how it flows to production.
Why do teams need more than sandboxing?
Sandboxing solves blast radius but leaves critical questions open: which secrets were visible, who approved the merge, what commands ran, whether tests passed, and whether the diff matches team policy. Teams deploying agents at scale need answers to these questions before code reaches production. A control plane provides the governance layer that makes agent work auditable and trustworthy.
How do agent control planes handle secrets?
Strong control planes scope secrets by team and task rather than inheriting everything a developer has access to. They separate personal secrets from team secrets, expose only what a specific task needs, log which secret names were available during a run, and support revocation. This is more secure than traditional approaches where agents inherit credentials from disk or environment variables.
Should different teams have different agent permissions?
Yes. Marketing agents, data agents, infrastructure agents, and product-engineering agents should not share the same permissions. Team-specific policies should cover repository access, branch rules, write permissions, network allowlists, tool permissions, runtime limits, and approval requirements. Treating "sandboxed" as a universal permission misses the point of role-based access control.
How do agent control planes integrate with code review?
Control planes treat diff review as a first-class state. Every agent-generated change flows through a reviewable artifact - typically a pull request - with owner, context, tests, trace, and rollback path. Non-engineering teammates triggering agents should not produce surprise code merges; instead, changes go through the same review workflow as human-authored code.
Is an agent control plane just CI with an agent?
Partly. The best agent infrastructure looks familiar because teams already operate queues, jobs, logs, policies, approvals, CI checks, and pull requests. What changes is the worker: an agent that interprets tasks, runs tools, edits code, asks for help, and revises its own work. The operating model adapts existing patterns to a worker that writes code.
What observability do coding agents need?
Every agent run should have a durable record including status, prompt history, command output, changed files, token usage, elapsed time, cost, approvals, errors, and final result. When an agent fails quietly, the trace is the product. Teams should be able to replay runs, audit decisions, and understand why a particular diff was produced.
Read next
Long-Running Agents Need Harnesses, Not Hope
A long-running coding agent is only useful if the environment around it can queue tasks, capture logs, checkpoint state, verify behavior, limit cost, and recover from failure.
9 min readClaude Managed Agents Are Starting to Look Like Backend Jobs
Claude Managed Agents now have multiagent sessions, outcomes, webhooks, and vault events. The practical takeaway is not just better agents. It is that agent runs need backend job discipline.
9 min readOpenAI Codex Cloud Security Playbook 2026: Internet Access, Prompt Injection, and Safe Defaults
A practical security playbook for running Codex cloud tasks safely in 2026 using OpenAI docs: internet access controls, domain allowlists, HTTP method limits, and review workflows.
10 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
InfrastructureOpen source
E2B
Open-source cloud sandboxes for AI agents. Isolated environments that start in under 200ms, run code in Python, JavaScri...
View ToolAI Frameworks
Composio
Gives AI agents access to 250+ external tools (GitHub, Slack, Gmail, databases) with managed OAuth. Handles the auth and...
View ToolAI Frameworks
OpenAI Agents SDK
Lightweight Python framework for multi-agent systems. Agent handoffs, tool use, guardrails, tracing. Successor to the ex...
View ToolAI Frameworks
A
Agency Swarm
Multi-agent orchestration framework built on the OpenAI Agents SDK. Define agent roles, typed tools, and directional com...
View ToolApps from Developers Digest
SaaS Products
Overnight Agents
Spec out AI agents, run them overnight, wake up to a verified GitHub repo.
View AppSaaS Products
Auto Company
Describe your company and agent teams handle operations.
View AppDeveloper ToolsPlus $20/mo
Skills Pro
Unlock pro skills and share private collections with your team.
View AppRelated Guides
Guide
Claude Code Complete Course
A complete, citation-backed Claude Code course with setup, prompting systems, MCP, CI, security, cost controls, and capstone workflows.
ai-developmentGuide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsGuide
MCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
AI AgentsRelated Videos

Agents 101: How to Build and Deploy Anything with AI Agents
Build Anything with Vercel, the Agentic Infrastructure Stack Check out Vercel: https://vercel.plug.dev/cwBLgfW The video shows a behind-the-scenes walkthrough of how the creator rapidly builds and d
Video·

TRAE: Custom AI Agents That Actually Understand Your Codebase
Check out Trae here! https://tinyurl.com/2f8rw4vm In this video, we dive into @Trae_ai a newly launched AI IDE packed with innovative features. I provide a comprehensive demonstration...
Video·

Introducing Augment Remote Agent: Parallel Autonomous AI Agents
Boost Your Productivity with Augment Code's Remote Agent Feature Sign up: https://www.augment.new/ In this video, learn how to utilize Augment Code's new remote agent feature within your...
Video·
Related Posts

9 min read
AI Agents
Long-Running Agents Need Harnesses, Not Hope
A long-running coding agent is only useful if the environment around it can queue tasks, capture logs, checkpoint state,...

9 min read
Claude
Claude Managed Agents Are Starting to Look Like Backend Jobs
Claude Managed Agents now have multiagent sessions, outcomes, webhooks, and vault events. The practical takeaway is not...
10 min read
OpenAI Codex
OpenAI Codex Cloud Security Playbook 2026: Internet Access, Prompt Injection, and Safe Defaults
A practical security playbook for running Codex cloud tasks safely in 2026 using OpenAI docs: internet access controls,...
8 min read
AI Coding
Agent Swarms Need Receipts
GitHub is filling with multi-agent frameworks, skills, and coding harnesses. The useful lesson is not that every team ne...

9 min read
AI Coding
Terminal Agents Are the New Developer Runtime
Terminal agents like Claude Code, Codex CLI, OpenCode, Copilot CLI, and DeepSeek-TUI are converging on the same runtime...

8 min read
OpenAI
OpenAI's June API Updates Are Really a Control-Plane Upgrade
OpenAI's June 2026 API changelog looks like scattered platform plumbing. Read together, moderation scores, workload iden...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever