OpenRouter Fusion Makes Model Panels Real. Use Them Like Escalation, Not Autopilot

TL;DR
OpenRouter Fusion turns multi-model panels into an API feature. The useful lesson is not to run every prompt through more models. It is to define when a task deserves an expensive second opinion.
OpenRouter Fusion is the most interesting routing feature on Hacker News today because it makes an old pattern feel productized: ask several models, let a judge combine the answers, and return one response. The Hacker News thread is already doing the right thing with it. People are excited, but the useful comments are about cost, latency, judge bias, and where a panel is actually worth paying for.
That is the right framing. Fusion should not become the new default for every AI feature. It should become an escalation lane.
Last updated: June 15, 2026
A single good model is still the default path for most product work. A cheap model is still right for classification, extraction, routing, summarization, and low-risk drafts. A local model is still right when privacy, offline access, or marginal cost matters more than frontier reasoning. A model panel belongs in the cases where a wrong answer is expensive, the task can be judged from multiple angles, and the extra wall-clock time is cheaper than a human rework loop.
That makes Fusion part of the same operating trend as LLM router infrastructure, agent token budgets, and multi-agent receipts. The question is not "can we throw more models at it?" The question is "which prompts deserve escalation, and what evidence proves the escalation helped?"
What Fusion Actually Changes#
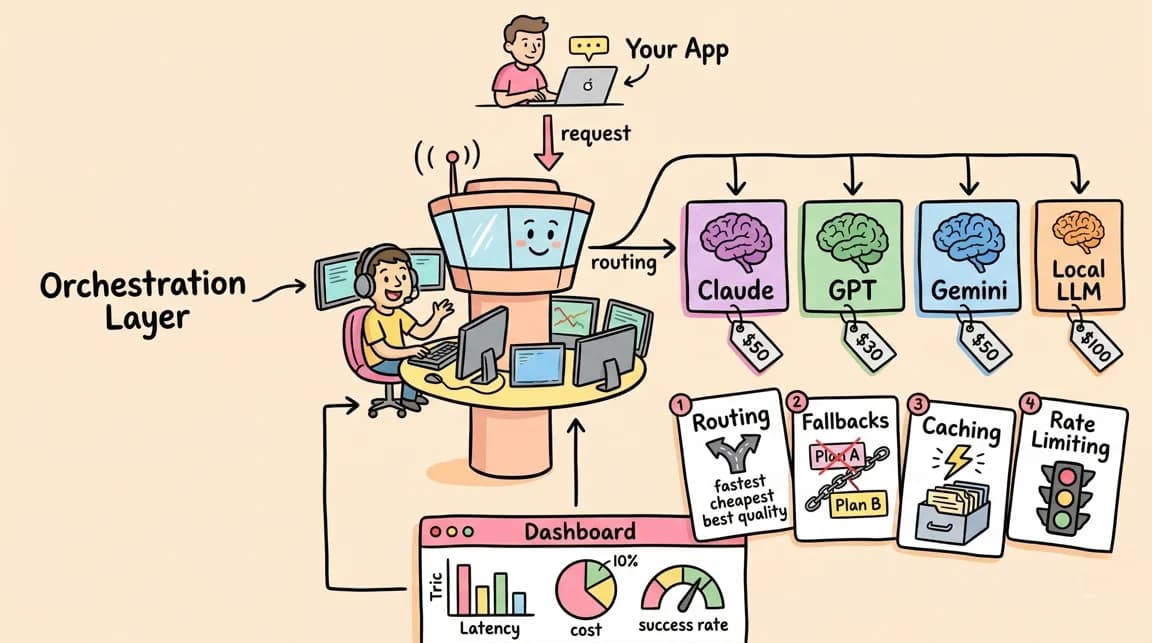
OpenRouter already sits in the provider-abstraction layer. You can call many models behind one API, use routing features, compare providers, and keep one billing surface. Fusion adds a higher-level move: multiple model calls become one logical answer path.
The OpenRouter Fusion page lists current model availability and shows Fusion as a named product surface. The docs index also exposes a dedicated Fusion Router and Fusion plugin/server-tool entries. That is the important product signal. The multi-model panel is no longer just something power users wire together in notebooks or agent frameworks. It is becoming a gateway primitive.
The underlying idea is not new. The Self-Consistency paper showed that sampling multiple reasoning paths and selecting the most consistent answer can improve chain-of-thought reasoning on arithmetic and commonsense benchmarks. The pattern also shows up in agent teams: ask independent workers to solve the same problem, compare outputs, and have a manager reconcile the result.
Fusion packages that instinct into a hosted path. That is useful. It is also dangerous if teams interpret it as a universal quality switch.
The Expensive Answer Is Not Always the Better Product#
One Hacker News commenter said their quick qualitative eval made Fusion much slower and more expensive than a direct frontier-model call. That is exactly the kind of objection product teams should preserve, not wave away. Even if the exact multiple changes with model selection, the shape is obvious: a panel calls more models, waits for more responses, and then spends more tokens judging the outputs.
That extra spend can be smart. It can also be waste.
If your app is generating placeholder copy, summarizing a support note, classifying a log line, or drafting a low-stakes email, a model panel is probably overbuilt. You would be better off with a cheaper model, prompt caching, deterministic validation, or a retry path. If your app is planning a schema migration, reviewing a security-sensitive patch, creating a legal-adjacent customer response, or deciding whether an agent should run a destructive command, a panel can be reasonable.
The boundary is not "hard prompt." The boundary is expected loss.
Use a panel when the cost of being wrong is higher than the incremental model cost and latency. That is the same logic behind human code review, staged rollouts, canary deploys, and incident commander escalation. You do not page five senior engineers for every CSS tweak. You do page them when the blast radius is high.
From the archive
Kimi K2.7-Code Developer Guide: The Open-Source Coding Model Worth Running
Jun 14, 2026 • 8 min read
Agent Workspaces Need Filesystem Contracts
Jun 13, 2026 • 8 min read
Best Claude Model Now That Fable 5 Is Disabled (Mythos vs Opus vs GPT-5.5)
Jun 13, 2026 • 6 min read
Claude Mythos and Fable 5 Banned: The Export Controls That Shut Down Two Frontier Models
Jun 13, 2026 • 6 min read
A Practical Escalation Policy#
The useful implementation is a policy table, not a vibes-based model selector.
| Task class | Default lane | Escalation trigger | Fusion-style panel worth it? |
|---|---|---|---|
| Extraction and classification | cheap deterministic model or rules | schema validation fails twice | rarely |
| Developer docs answer | single strong model with citations | source conflict or low confidence | sometimes |
| Code review comment | single coding model | security, data loss, auth, billing, migrations | yes |
| Agent plan before execution | one planner model | destructive command, broad file scope, expensive cloud action | yes |
| Product copy draft | cheap creative model | regulated claims or launch page headline | sometimes |
| Final answer for paid user | best single model | conflicting retrieved evidence | yes |
The point is to keep the panel behind explicit gates. You want logs that say: this request started on the default lane, hit an escalation condition, spent an additional budget, and produced a different or more confident answer.
Without that ledger, Fusion becomes another invisible premium mode. You will know the bill went up, but you will not know whether quality improved.
For agent products, this is especially important. An agent can already burn tokens through loops, tools, context reloads, and retries. Adding multi-model panels inside that loop without a budget ledger multiplies the uncertainty. The harness engineering token budget pattern applies here directly: record the panel as a child span with models called, input tokens, output tokens, latency, judge model, final decision, and whether the panel changed the action.
The Judge Is Part of the Product#
The weak point in model panels is often not the workers. It is the judge.
HN commenters raised the obvious issue: if one model judges another model's answer, the judge may prefer the answer that resembles its own style. That does not mean judging is useless. It means the judge needs a rubric and the product needs receipts.
For developer tools, the rubric should be concrete:
- Does the answer cite the exact source or file it relies on?
- Does it preserve constraints from the user or project instructions?
- Does it identify uncertainty instead of smoothing it over?
- Does it propose a smaller action before a broader one?
- Does it pass a deterministic check, test, typecheck, schema, or policy rule?
- Does it change the recommended action compared with the default lane?
That last question is the one most dashboards will skip. If Fusion produces the same practical answer as a single model 90 percent of the time, you do not need it on the hot path. You need it for the 10 percent of tasks where disagreement reveals risk.
The panel output should include the disagreement, not just the polished final answer. If three models agree on a refactor but one flags a migration risk, the useful artifact is not only "approved." It is "approved, except the database migration needs a backup plan." That is the difference between a panel and a more expensive autocomplete.
Where This Fits With Local and OS-Level Model Routing#
The other HN trend today was Anthropic's Swift package for Claude on Apple's Foundation Models framework. That points in the opposite direction from Fusion: one standard interface, with the app choosing between Apple's on-device model and Claude depending on the task. I covered the broader Apple angle in the LanguageModel protocol post, but the connection matters here.
The market is splitting into lanes:
- Local/on-device lane: fast, private, offline, low marginal cost.
- Hosted single-model lane: best default for most useful AI product work.
- Router lane: provider choice, fallbacks, price/performance selection.
- Panel lane: high-cost escalation for tasks where disagreement is valuable.
OpenRouter Fusion belongs in the fourth lane. It should not erase the first three.
This also connects with Gabriel Weinberg's HN-front-page argument that not everyone is using AI for everything. His post is about consumer adoption, but the product lesson applies to developer tools too: users do not want "AI everywhere" as an ideology. They want the right amount of AI for the task. Sometimes that is no model. Sometimes that is a local model. Sometimes it is the strongest frontier model. Sometimes it is a panel.
Good AI products will make those lanes explicit.
What I Would Build Around Fusion#
If I were adding Fusion to a developer product today, I would not put a "use Fusion" toggle in the main UI. I would add an escalation policy behind the workflows that already scare users.
For example:
- A coding agent proposes a database migration.
- The harness marks the plan as high blast radius because it touches schema, auth, billing, or data deletion paths.
- The default model writes the plan and risk summary.
- Fusion runs only on the plan review step.
- The judge must return a structured result: approve, revise, block, and reasons.
- The UI shows the user the disagreement summary and the added cost before execution.
- The trace records whether the panel changed the outcome.
That is a product feature. "Every answer is now fused" is a billing feature.
You can do the same for documentation answers. Start with one model plus citations. Escalate only when retrieved sources conflict, when the answer relies on stale versioned docs, or when the user asks for a production migration. The panel then reviews source interpretation, not vibes.
For creative work, I would be even more selective. Panels can make copy safer and more complete, but they can also sand off taste. A single strong model with a sharp brand voice may be better than a committee. Fusion is most interesting when the output has an objective constraint, a high cost of error, or a real disagreement surface.
The Takeaway#
OpenRouter Fusion is a useful sign that model routing is moving up the stack. The next phase is not only "which model should answer?" It is "when should more than one model answer, and how do we know that helped?"
The answer should be operational:
- Start cheap and direct.
- Escalate on risk, uncertainty, or conflict.
- Record cost and latency as first-class evidence.
- Show disagreement when it matters.
- Measure whether the panel changed decisions, not whether it sounded smarter.
That makes Fusion a serious developer primitive. It turns model panels from a demo trick into an escalation system.
FAQ#
What is OpenRouter Fusion?#
OpenRouter Fusion is a multi-model routing surface from OpenRouter that can combine outputs from several models into one final response. The product sits inside OpenRouter's broader model-routing ecosystem, alongside provider selection, fallbacks, model variants, and router features.
Is OpenRouter Fusion better than calling one frontier model?#
Sometimes. Fusion-style panels can help when multiple independent attempts reveal disagreement, catch missing assumptions, or improve reasoning on high-stakes tasks. They are usually overkill for low-risk extraction, summarization, or drafting work where one cheap or strong model already meets the quality bar.
When should developers use model panels?#
Use model panels for tasks where the cost of a wrong answer is higher than the extra cost and latency of multiple model calls. Good examples include security-sensitive code review, database migrations, destructive agent actions, conflicting source interpretation, and final answers for paid users.
What is the risk of using an LLM as a judge?#
An LLM judge can prefer answers that match its own style, miss errors outside its rubric, or smooth over genuine disagreement. Treat the judge as part of the product: give it a concrete rubric, log its decision, preserve disagreement summaries, and validate outputs with deterministic checks whenever possible.
How does Fusion relate to LLM routers?#
Traditional LLM routers pick one model or provider for a request based on cost, latency, quality, availability, or fallback rules. Fusion-style routing can call multiple models for the same request and combine the answers. That makes it an escalation layer on top of routing, not a replacement for normal routing.
Sources#
- OpenRouter Fusion - current Fusion product surface and model list, fetched June 15, 2026.
- OpenRouter model routing docs - routing documentation index and router surfaces, fetched June 15, 2026.
- Hacker News: OpenRouter Fusion API - launch discussion with cost, latency, judge, and use-case pushback, fetched June 15, 2026.
- Self-Consistency Improves Chain of Thought Reasoning in Language Models - research background for sampling multiple reasoning paths.
- Claude for Apple Foundation Models - Anthropic's Foundation Models integration, fetched June 15, 2026.
- No, everyone is not using AI for everything - adoption-counterweight essay discussed on HN, fetched June 15, 2026.
Read next
LLM Routers Compared: LiteLLM vs Portkey vs OpenRouter in 2026
A practical comparison of LLM routing tools - LiteLLM, Portkey, and OpenRouter - covering cost management, fallbacks, caching, and when to use each for production AI applications.
10 min readHarness Engineering Makes Tokens a Systems Budget
OpenAI's harness engineering post and new token-use research point to the same lesson: agentic coding teams need token budgets, receipts, and eval loops, not vibes.
8 min readAgent Swarms Need Receipts
GitHub is filling with multi-agent frameworks, skills, and coding harnesses. The useful lesson is not that every team needs a swarm. It is that every agent needs receipts: tests, logs, diffs, and reviewable checkpoints.
8 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Models
OpenRouter
Unified API for 200+ models. One API key, one billing dashboard. OpenAI, Anthropic, Google, Meta, Mistral, and more. Aut...
View ToolAI ModelsDaily Driver
Claude
Anthropic's AI. Opus 4.6 for hard problems, Sonnet 4.6 for speed, Haiku 4.5 for cost. 200K context window. Best coding m...
View ToolAI Models
ChatGPT
OpenAI's flagship. GPT-4o for general use, o3 for reasoning, Codex for coding. 300M+ weekly users. Tasks, agents, web br...
View ToolAI Models
DeepSeek
Open-source reasoning models from China. DeepSeek-R1 rivals o1 on math and code benchmarks. V3 for general use. Fully op...
View ToolApps from Developers Digest
Related Guides
Guide
Run AI Models Locally with Ollama and LM Studio
Install Ollama and LM Studio, pull your first model, and run AI locally for coding, chat, and automation - with zero cloud dependency.
Getting StartedGuide
Plan Mode - Claude Code
Explore and propose changes without executing them.
Claude CodeGuide
Protected Paths - Claude Code
Auto-guarded directories like .git, .claude, and .vscode.
Claude CodeRelated Videos

Mercury 2: The First Reasoning Diffusion Language Model (1,000+ tokens/sec)
Mercury Two: The First Reasoning Diffusion LLM (1,000+ tokens/sec) - Speed Without Sacrificing Quality Inception Labs releases Mercury Two, a reasoning diffusion-based LLM that exceeds 1,000 tokens p
Video·

Diffusion Large Language Models Are Here
Mercury: A New Diffusion LLM In today's video, I dive into the exciting launch of Inception Labs' Mercury, the first commercial-grade diffusion large language model. Unlike traditional autoregress...
Video·

Not Diamond: AI Model Routing in 11 Minutes
Use OpenAI's O1, GPT-4o, Anthropic Claude Sonnet, Claude Haiku, Gemini Flash, Gemini Pro, Perplexity and More for Optimizing AI Model Selection for Price, Speed, and Quality in AI Applications...
Video·
Related Posts
10 min read
AI Infrastructure
LLM Routers Compared: LiteLLM vs Portkey vs OpenRouter in 2026
A practical comparison of LLM routing tools - LiteLLM, Portkey, and OpenRouter - covering cost management, fallbacks, ca...

8 min read
AI Agents
Harness Engineering Makes Tokens a Systems Budget
OpenAI's harness engineering post and new token-use research point to the same lesson: agentic coding teams need token b...
8 min read
AI Coding
Agent Swarms Need Receipts
GitHub is filling with multi-agent frameworks, skills, and coding harnesses. The useful lesson is not that every team ne...
8 min read
apple
Apple's LanguageModel Protocol: Xcode 27 Just Made Model Lock-In Optional
Apple shipped a LanguageModel protocol at WWDC 2026 that lets iOS and macOS developers swap between Claude, Gemini, and...

8 min read
factory-ai
Factory AI and the Model Routing Era: How Coding Agents Are Learning to Spend Your Tokens Wisely
Factory AI's Droid agent surfaces a new competitive front in coding tools: cost-per-completed-task. Here's what their ar...

7 min read
Grok
Grok 4.5 in 10 Minutes: xAI's Fastest Model, 500K Context, and Build-Mode Integration
A companion guide to the Grok 4.5 video: xAI's most intelligent model with a 500K context window, function calling, stru...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever