Program-as-Weights Turns Prompts Into Local Fuzzy Functions
TL;DR
The Program-as-Weights paper is a useful signal for developers: some LLM calls may move from per-request API prompts into compact local artifacts that behave like reusable fuzzy functions.
Official Sources
| Source | What it covers |
|---|---|
| Program-as-Weights on arXiv | Paper abstract, authors, submission date, core method, and headline results |
| Program-as-Weights on Hugging Face Papers | Daily paper ranking, discussion entry, project page, and linked repository |
| Program-as-Weights project site | Project framing and release links |
| Program-as-Weights Python repository | Public code surface linked from the Hugging Face paper page |
Last updated: July 5, 2026
The most interesting paper on Hugging Face this week is not another bigger model announcement. It is a paper about making some model calls smaller, local, and reusable.
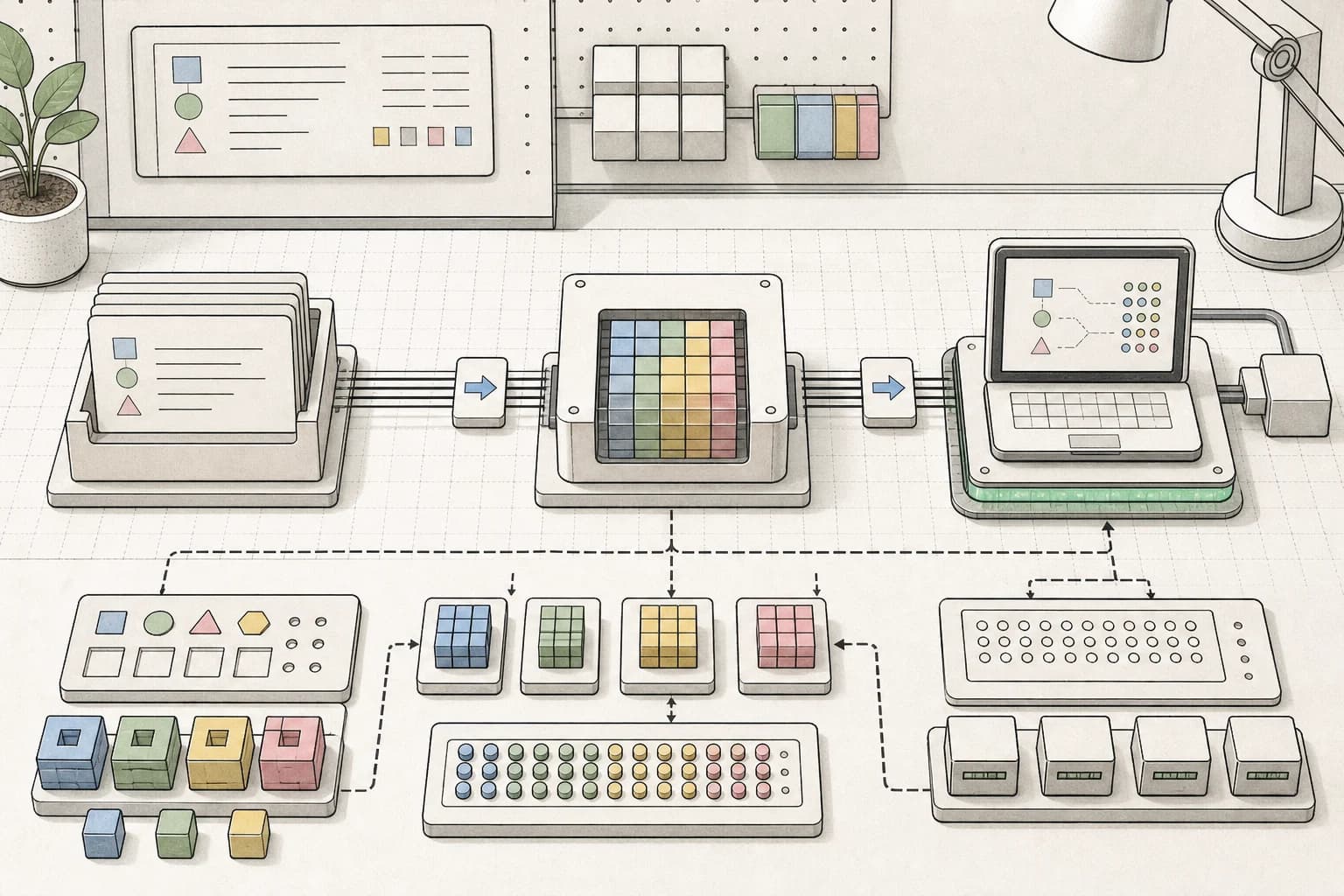
Program-as-Weights, from Wentao Zhang, Liliana Hotsko, Woojeong Kim, Pengyu Nie, Stuart Shieber, and Yuntian Deng, proposes a programming pattern the authors call fuzzy-function programming. The idea is simple enough to be dangerous: write a natural-language function specification once, compile it into a compact neural artifact, then call that artifact locally instead of sending every input back through a large model API.
That is a different mental model from most AI app architecture today.
Right now, the default pattern for fuzzy work is runtime prompting. If you need to classify noisy logs, repair malformed JSON, label support tickets, rank search results by intent, normalize messy user input, or extract a weak signal from ambiguous text, you usually call a frontier or mid-sized model for every request.
The Program-as-Weights paper asks whether some of that work should look more like compilation.
Not "replace every LLM call." Not "agents are over." A narrower and more useful take:
Some prompts want to become functions.
What PAW Claims
The paper instantiates the idea with Program-as-Weights, or PAW. The authors describe a 4B compiler trained on FuzzyBench, a 10 million example dataset they release. That compiler emits parameter-efficient adapters for a frozen lightweight interpreter.
The headline result is the part developers will remember: a 0.6B Qwen3 interpreter executing PAW programs matches direct prompting of Qwen3-32B, while using roughly one fiftieth of the inference memory and running at 30 tokens per second on a MacBook M3.
Treat those numbers as research claims, not production guarantees. The interesting part is the architectural shape.
In the normal pattern, the foundation model is a per-input problem solver:
input -> prompt -> large model -> output
In the PAW pattern, the foundation model becomes a tool builder:
function spec -> compiler model -> compact weights
input -> local interpreter + compact weights -> output
That is why the paper matters. If this class of method holds up, developers get a new category between deterministic code and live LLM calls: small neural functions that are cheap to run, local by default, and specialized to a narrow behavior.
The Developer Shape: Fuzzy Functions
Most production codebases already contain fuzzy functions. They just do not call them that.
A fuzzy function is the kind of operation that has clear examples but messy boundaries:
- "Is this log line important enough to page someone?"
- "Does this user message contain a cancellation intent?"
- "Which docs page best answers this vague support question?"
- "Can this malformed JSON be repaired safely?"
- "Is this pull request description a useful summary or a placeholder?"
You can write rules for these tasks, but the rule set gets brittle fast. You can call an LLM, but then every request inherits API latency, cost, privacy exposure, provider availability, and model drift.
The PAW bet is that some of these tasks are stable enough to compile.
That should feel familiar to developers working with agent systems. In Agent Memory Needs a Context Ledger, the core point is that long-running agents need a persistent structure outside the prompt. In Agent Context Reduction Is a Product Pattern, the useful pattern is to stop treating the context window as an infinite trash bag. PAW makes a related move at the function level: stop treating the largest model as the only place fuzzy behavior can live.
The prompt is not the product. The reusable behavior is.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Claude Sonnet 5 Developer Guide: Migration, API, and Effort Levels
Jul 4, 2026 • 8 min read
Dan Luu's Agentic Coding Notes Point to the Real Bottleneck
Jul 4, 2026 • 8 min read
Image Token Compression Is a Real Agent Cost Lever
Jul 4, 2026 • 8 min read
Jamesob's Guide to Running SOTA LLMs Locally: The Hardware and Config That Actually Works
Jul 4, 2026 • 9 min read
Where This Could Fit First
The early production targets are not glamorous. They are the boring calls that run thousands or millions of times.
Start with high-frequency, low-drama classification and normalization:
- log triage
- routing support tickets
- intent labeling
- search-result reranking
- lightweight moderation prefilters
- noisy schema repair
- document chunk quality scoring
- agent trace summarization
These are not places where you want a deeply creative model. You want a cheap, consistent, inspectable function with a known input and output contract.
That is also why PAW sits next to model routing rather than replacing it. In Model Routing Is Becoming the AI Infrastructure Layer, the practical advice is to route work by task shape, not brand loyalty. PAW adds another possible route:
- deterministic code for exact behavior
- compiled fuzzy functions for stable ambiguous behavior
- small hosted models for flexible low-stakes tasks
- frontier models for hard reasoning, planning, or generation
The reason this is exciting is not that it removes model routing. It makes routing more granular.
The Catch: Compilation Needs Evals
The easiest bad version of this idea is obvious: compile a fuzzy function, ship it, and assume it behaves like code.
It does not.
A PAW artifact is still a learned behavior. It needs test sets, drift checks, calibration, and rollback. If a compiled log-triage function quietly stops recognizing a new class of production incident, the fact that it runs locally does not help you.
That makes the eval harness more important, not less. For agent work, Long-Running Agents Need Harnesses, Not Hope makes the same argument: the model is only one piece of the system. The harness decides whether the behavior is useful enough to trust.
For fuzzy functions, a practical harness should include:
- a golden set of representative inputs
- known hard negatives
- recent production examples
- latency and memory budgets
- regression checks against the hosted-model baseline
- a rollback path to the old runtime prompt
The hosted model call is your baseline. The compiled artifact has to earn the right to replace it.
Why This Is Different From Fine-Tuning
It is tempting to file PAW under "fine-tuning, but smaller." That undersells the programming model.
Fine-tuning usually asks you to train or adapt a model around a task family. PAW asks whether a natural-language function specification can produce a compact program-like weight artifact for one fuzzy function. The unit of reuse is not "our company support model." It is closer to:
const isPagerWorthy = compileFuzzyFunction(`
Return true only when this log line suggests user-facing impact,
data loss, auth failure, payment failure, or sustained outage risk.
`);
That pseudo-code is not copied from the PAW repository. It is the developer interface this research points toward.
If that interface becomes real, AI engineering starts to look less like prompt sprawl and more like a typed library of fuzzy functions with benchmarks beside them.
That connects directly to the skills conversation. In Skills for Real Engineers Need Governance, Not Fandom, the argument is that reusable agent instructions should be governed like production controls. A compiled fuzzy function deserves the same treatment: owner, version, test set, intended scope, and deletion criteria.
Opposing View: Most Prompts Should Stay Prompts
The fair skeptical view is that most LLM calls are not stable enough to compile.
Developers often use prompts because the target keeps moving. The input distribution changes. The product changes. The tolerance for false positives changes. A prompt is easy to tweak during that phase. A compiled artifact adds ceremony.
That is a good objection.
The right boundary is not "compile everything." It is "compile the calls whose shape has stabilized."
If you are still discovering the behavior, keep the prompt. If the task is high-stakes and requires nuanced reasoning, keep the larger model and add review. If the call is stable, frequent, narrow, and expensive, PAW-style compilation becomes interesting.
The other caveat is ecosystem maturity. The paper links a project page and a Python repository through Hugging Face, but this is still a research release. Before building production architecture around it, check the repository state, licenses, supported models, dataset access, and whether the benchmark tasks match your workload.
The Practical Take
Program-as-Weights is worth watching because it names a real pain in AI apps: too many fuzzy operations are trapped in per-request prompts.
The durable idea is not the exact PAW implementation. It is the split between specification time and execution time.
For developers, the useful question becomes:
Which prompts in my system are actually functions?
Find the calls that are stable, repetitive, narrow, and measurable. Keep the frontier model as the compiler or teacher. Move the hot path toward smaller local execution when the evals prove it works.
That is a more grounded version of local AI than "run the biggest model on your laptop." It is also more useful. The win is not local chat. The win is local behavior that your app calls a thousand times without asking permission from a remote model.
FAQ
What is Program-as-Weights?
Program-as-Weights is a research system for compiling a natural-language fuzzy function specification into compact neural weights that can run through a lightweight local interpreter.
Is PAW a replacement for LLM APIs?
No. It is better understood as a possible replacement for specific high-frequency, narrow, stable LLM calls. Frontier model APIs still make sense for open-ended reasoning, planning, creative generation, and tasks whose behavior is still changing.
What kinds of tasks fit fuzzy-function programming?
Good candidates include log classification, intent detection, search reranking, malformed JSON repair, support routing, document-quality scoring, and other tasks where examples are easy to gather but deterministic rules become brittle.
Is Program-as-Weights production-ready?
Treat it as promising research until you verify the code, license, supported models, and benchmark fit for your workload. The production pattern still needs evals, regression tests, drift checks, and a fallback to the original hosted-model path.
Why does this matter for AI coding agents?
Coding agents depend on many repeated fuzzy judgments: which file matters, whether a test failure is relevant, whether a patch summary is truthful, and whether a trace should be escalated. PAW-style artifacts suggest that some of those judgments could become local, benchmarked helper functions instead of live prompts.
Sources
- Program-as-Weights: A Programming Paradigm for Fuzzy Functions, arXiv, submitted July 2, 2026.
- Program-as-Weights on Hugging Face Papers, checked July 5, 2026.
- Program-as-Weights project site, checked July 5, 2026.
- Program-as-Weights Python repository, checked July 5, 2026.
Read next
AI Agent Memory Needs a Context Ledger
GitHub Trending is full of agent memory and context tools. The useful version is not magic recall. It is a context ledger: source-linked, scoped, expiring memory that agents can inspect and users can audit.
8 min readThe 98% Context Reduction Pattern
Efficient agents do not stuff every tool result into the model context. They keep intermediate state in code, files, and execution environments, then return compact summaries and receipts.
8 min readWhere Should Your AI Agent Run Code: E2B vs Daytona vs Modal vs Cloudflare vs Vercel Sandbox
A builder's guide to picking a code-execution sandbox for AI agents - E2B, Daytona, Modal, Cloudflare Sandbox, and Vercel Sandbox compared on isolation, latency, state, and pricing model.
7 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Coding
Aider
Open-source AI pair programming in your terminal. Works with any LLM - Claude, GPT, Gemini, local models. Git-aware ed...
View ToolLocal AI
Ollama
The easiest way to run LLMs locally. One command to pull and run any model. OpenAI-compatible API. 52M+ monthly download...
View ToolLocal AI
LM Studio
Desktop app for discovering, downloading, and running local LLMs. Clean chat UI, OpenAI-compatible API server, and autom...
View ToolLocal AI
Jan
Open-source ChatGPT alternative that runs 100% offline. Desktop app with local models, cloud API connections, custom ass...
View ToolApps from Developers Digest
Developer ToolsIn Progress
Skill Builder
Turn a one-liner into a working Claude Code skill. From idea to installed in a minute.
View AppSaaS ProductsIn Progress
Community Insight Engine
Turn community complaints and requests into validated product bets and weekly briefs.
View AppDeveloper ToolsIn Progress
Docs To Demo
Turn API docs into endpoint maps, auth setup, demo ideas, and build-ready prompts.
View AppRelated Guides
Guide
Run AI Models Locally with Ollama and LM Studio
Install Ollama and LM Studio, pull your first model, and run AI locally for coding, chat, and automation - with zero cloud dependency.
Getting StartedGuide
Bash Mode - Claude Code
Prefix prompts with ! to run shell commands directly, bypassing Claude.
Claude CodeGuide
Multiline Input - Claude Code
Shift+Enter, Option+Enter, or backslash+Enter for multi-line prompts.
Claude CodeRelated Videos

ChatLLM Operator | New 1 Click AI Agent automates your work and research
Meet ChatLLM Operator 🌐✈️📊 In this video, I'll show you the capabilities of ChatLLM Operator. Discover how this affordable tool, at just $10 a month, can autonomously handle tasks...
Video·

Genie 2: Google's New AI Model Turns One Image into Infinite Playable Worlds
Learn The Fundamentals Of Becoming An AI Engineer On Scrimba; https://v2.scrimba.com/the-ai-engineer-path-c02v?via=developersdigest In today's video, I discuss Google's latest announcement...
Video·

LM Studio: Run Local LLMs in 7 Minutes
Exploring LM Studio: A Guide to Running AI Models Locally in 7 Minutes This video tutorial introduces LM Studio, a comprehensive application that allows users to run a variety of AI models...
Video·
Related Posts

8 min read
AI Agents
AI Agent Memory Needs a Context Ledger
GitHub Trending is full of agent memory and context tools. The useful version is not magic recall. It is a context ledge...

8 min read
Context Engineering
The 98% Context Reduction Pattern
Efficient agents do not stuff every tool result into the model context. They keep intermediate state in code, files, and...

7 min read
AI Agents
Where Should Your AI Agent Run Code: E2B vs Daytona vs Modal vs Cloudflare vs Vercel Sandbox
A builder's guide to picking a code-execution sandbox for AI agents - E2B, Daytona, Modal, Cloudflare Sandbox, and Verce...

9 min read
AI Agents
Long-Running Agents Need Harnesses, Not Hope
A long-running coding agent is only useful if the environment around it can queue tasks, capture logs, checkpoint state,...

7 min read
AI Coding
Skills for Real Engineers Need Governance, Not Fandom
Matt Pocock's skills repo is a useful signal for AI coding teams. The next step is treating skills like governed product...
12 min read
AI Model Routing
AI Model Routing: Why the Orchestration Layer Is the Next Big Play Next to the Labs
A $500M accidental Claude bill and an open-weights model beating GPT-5.5 at one-sixth the cost point to the same conclus...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever