Topic
LLM
Large language models - architecture, capabilities, and how to pick the right one for the job.
23 resources - 14 posts, 9 tools
Blog Posts
View in blog →
The One-Cent Attack: Prompt Injection Through Bank Transfer Memos
Security researchers showed a €0.02 bank transfer could compromise a banking AI assistant. Here is the exact attack chain - and what every developer building agents needs to do differently.
8 min read
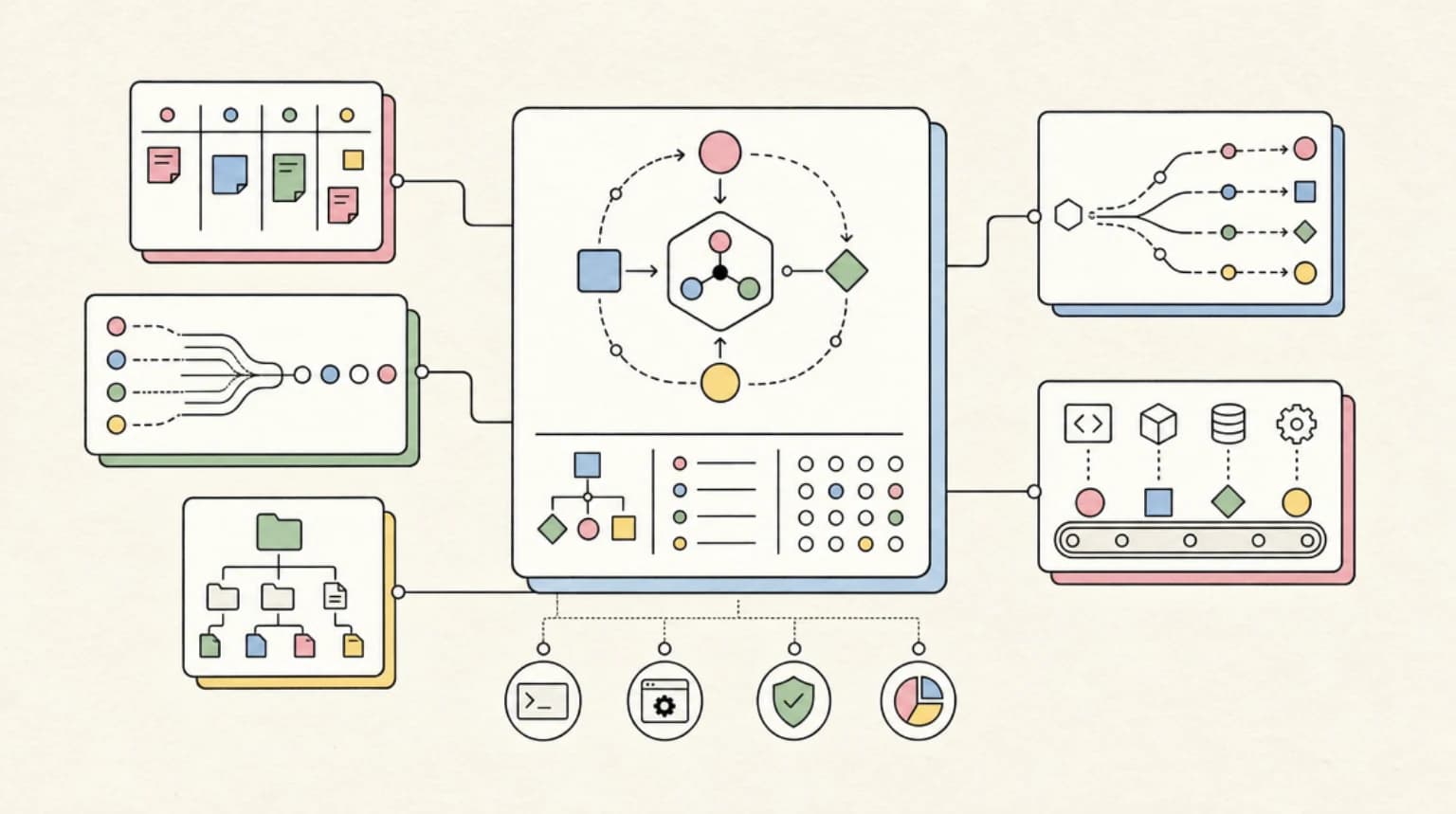
Mastra: Review and Setup Guide for TypeScript Agent Apps (2026)
A hands-on look at Mastra, the open source TypeScript framework for building production-ready AI agents and workflows -- with verified setup commands, honest tradeoffs, and current pricing.
8 min read

OpenRouter in 2026: Review, Setup, and When Model Routing Pays
OpenRouter gives you one API key for 300+ models, automatic fallbacks, and intelligent provider routing. Here is what it actually costs, how to set it up in five minutes, and when you should skip it entirely.
8 min read
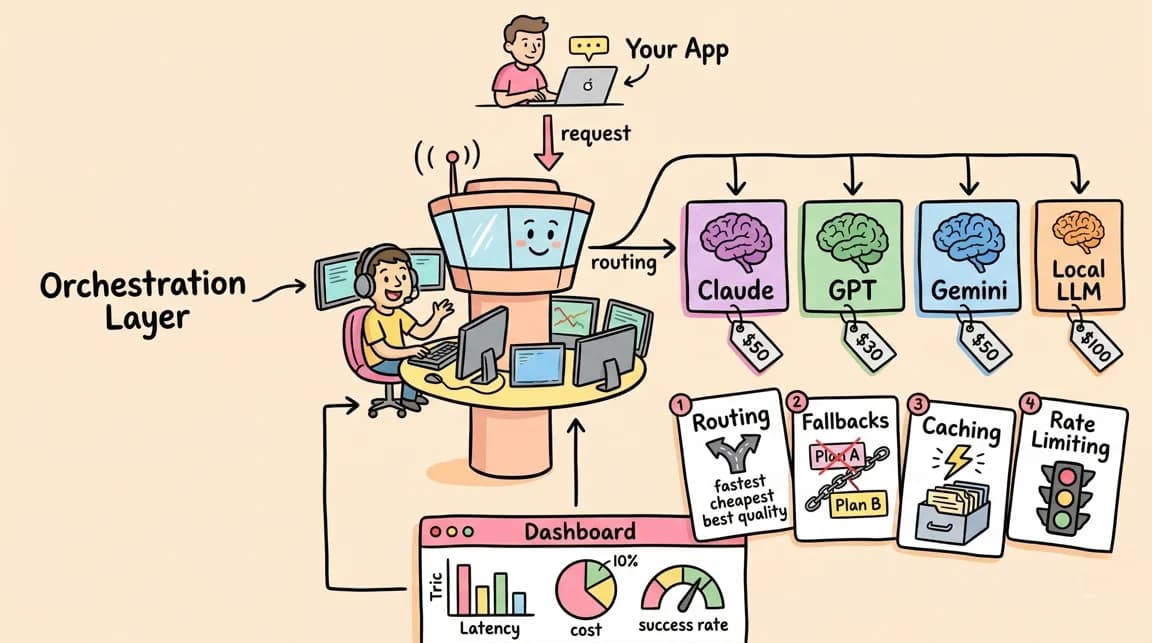
LLM Routers Compared: LiteLLM vs Portkey vs OpenRouter in 2026
A practical comparison of LLM routing tools - LiteLLM, Portkey, and OpenRouter - covering cost management, fallbacks, caching, and when to use each for production AI applications.
10 min read

KV Caching: A Practical Guide to Optimizing Transformer Inference
How KV caching speeds up LLM inference - the math, the code, the memory tradeoffs, and when it stops helping. Every dev running local models hits this wall.
11 min read

Mercury 2 Developer Guide: Building With a Diffusion LLM in Production
A hands-on developer guide to Mercury 2 from Inception Labs. OpenAI-compatible API, reasoning levels, tool use, structured outputs, and when a diffusion LLM beats an autoregressive one in real apps.
10 min read

Promptlock: Deterministic Prompt Versioning for LLM Apps
Promptlock gives every prompt a 12-char content-addressable id and a diff-able artifact, turning silent prompt drift into a reviewable change.
7 min read
Mercury 2: The LLM That Doesn't Generate Like an LLM
Inception Labs shipped the first reasoning model built on diffusion instead of autoregressive generation. Over 1,000 tokens per second, competitive benchmarks, and a fundamentally different approach to how AI generates text.
8 min read

Claude Skills: A technical deep dive into Anthropic's new approach to AI context management
A comprehensive look at Claude Skills-modular, persistent task modules that shatter AI's memory constraints and enable progressive, composable, code-capable workflows for developers and organizations.
8 min read

GPT-5: OpenAI's Most Capable Model
GPT-5 introduces a fundamentally different approach to inference. Instead of forcing developers to manually configure reasoning parameters, the model operates as a unified system with real-time rou...
7 min read

Diffusion Language Models: How Mercury Changed the LLM Speed Game
Inception Labs launched Mercury, the first commercial-grade diffusion large language model. It generates over 1,000 tokens per second on standard Nvidia hardware by replacing autoregressive generation with a coarse-to-fine diffusion process.
7 min read

Unstract: Open-Source AI Document Parsing at Scale
Unstract is an open-source, no-code platform for extracting structured data from PDFs, invoices, scanned documents, and more. Here is how it works, how to set it up, and why automated document processing is becoming essential for organizations drowning in unstructured data.
10 min read

Microsoft PHI-4: A 14B Parameter Model That Rivals Models 5x Its Size
Microsoft's PHI-4 is an MIT-licensed 14 billion parameter model that matches Llama 3.3 70B and Qwen 2.5 72B on key benchmarks. Here is what makes it special, how to run it locally, and why small language models are increasingly practical for real development work.
9 min read

Llama 3.3 70B: Meta's Cost-Effective Frontier Model
Meta surprised the AI community with Llama 3.3, a 70 billion parameter model that delivers 405B-class performance at a fraction of the cost. Here is what the benchmarks show, where to run it, and why this release matters for developers building with open-source models.
8 min read
Related Tools
All tools →Ollama
The easiest way to run LLMs locally. One command to pull and run any model. OpenAI-compatible API. 52M+ monthly downloads. Supports GGUF, Safetensors, and custom Modelfiles.
Local AILM Studio
Desktop app for discovering, downloading, and running local LLMs. Clean chat UI, OpenAI-compatible API server, and automatic GPU detection. MLX engine optimized for Apple Silicon.
Local AIJan
Open-source ChatGPT alternative that runs 100% offline. Desktop app with local models, cloud API connections, custom assistants, and MCP integration. AGPLv3 licensed.
Local AIGPT4All
Private local AI chatbot by Nomic. 250K+ monthly users, 65K GitHub stars. LocalDocs feature lets you chat with your own files. Runs on Windows, macOS, and Linux.
Local AILocalAI
Open-source OpenAI API replacement. Runs LLMs, vision, voice, image, and video models on any hardware - no GPU required. 35+ backends. Distributed mode for scaling.
Local AIvLLM
High-throughput inference server for LLMs. PagedAttention memory management. The go-to for serious local or self-hosted serving.
Local AIBrowser Harness
Self-healing browser automation harness that lets LLMs complete any browser task. 5,000+ stars in under a week.
InfrastructureLiteLLM
Open sourceOpen-source AI gateway: call 100+ LLM providers in the OpenAI format via a Python SDK or proxy. Spend tracking, budgets, rate limiting, load balancing, and fallbacks built in.
AI FrameworksLangfuse
Open sourceOpen-source LLM engineering platform: tracing, evals, prompt management, and datasets. Self-hostable, OpenTelemetry-native, with 50+ framework integrations.
InfrastructureKeep exploring
More on LLM
- - Ollama - recommended LLM tool from the Developers Digest directory
- - Compare Tools - dive deeper across the Developers Digest knowledge base
- - All LLM articles in the blog archive
- - Developers Digest on YouTube - video tutorials covering LLM and more

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever
Explore 659 topics
Browse All Topics