Spreadsheet Agents Need Permission Ledgers
TL;DR
The ChatGPT for Google Sheets exfiltration report is not just a spreadsheet bug. It is a warning about agentic office tools: permissions need to be action-scoped, logged, revocable, and visible.
Official Sources#
| Resource | What it covers |
|---|---|
| PromptArmor: GPT for Google Sheets Data Exfiltration | The original security research report detailing the indirect prompt injection and data exfiltration vulnerability. |
| OpenAI Platform Security | OpenAI's safety best practices for building with their APIs, including guidance on tool use and output handling. |
| Google Workspace Admin Help: Third-party Apps | Google's documentation on controlling third-party app access in Workspace, including OAuth app allowlisting. |
| OWASP Top 10 for LLM Applications | Industry standard security risks for LLM applications including prompt injection and insecure plugin design. |
| Google Apps Script Documentation | Official documentation for Apps Script, the automation runtime referenced in the vulnerability report. |
The most useful AI security story on Hacker News today is not really about Google Sheets.
It is PromptArmor's report, "ChatGPT for Google Sheets Exfiltrates Workbooks", and the reason it matters is broader than one extension. The report describes an indirect prompt injection where a malicious imported sheet could influence ChatGPT for Google Sheets, trigger external Apps Script execution, pull data from other workbooks, and continue across linked spreadsheets.
That is the agent-app version of the old spreadsheet macro problem.
The model reads untrusted data. The product lets the model call a powerful tool. The user sees a friendly assistant surface. The real action happens through a privileged runtime nearby.
If you are building with tool use, MCP servers, or office-style AI agents, this is the lesson:
Consent dialogs are not enough. Spreadsheet agents need permission ledgers.
Last updated: June 1, 2026
What Actually Happened#
PromptArmor says the attack began with untrusted spreadsheet content. A normal-looking user request could cause the assistant to run attacker-controlled code through Apps Script. From there, the script could discover links to other workbooks, exfiltrate data, and keep going.
The report also says the same primitive enabled phishing overlay attacks inside the sidebar. That matters because the assistant UI becomes part of the trust boundary. If the user cannot tell whether the sidebar is still the assistant, the permission model has already become fuzzy.
OpenAI responded in the Hacker News thread through a commenter identifying as a member of the OpenAI security team. The response said OpenAI removed the model's ability to generate Apps Script code for the product, and that the team was re-evaluating how the feature interacts with Google Sheets APIs and sandboxing.
That is the right emergency move. Remove the dangerous capability, then review similar surfaces.
But the deeper issue is not "Apps Script was too powerful." The deeper issue is that the assistant had a capability surface that users could not reason about.
The HN Pushback Is the Product Requirement#
The best Hacker News comments did not stop at "prompt injection bad."
One thread asked whether defenses are just long prompt instructions, or whether they are real sandboxes and sub-agents. Another argued that local and containerized execution is not automatically safe if the environment can still communicate through files, devices, APIs, or user-mediated workflows. A separate thread focused on disclosure process and whether vendors only react once social pressure appears.
Strip away the drama and you get a very practical product requirement:
Users need to know what an agent can do before it does it, what it actually did afterward, and which actions can still be stopped.
That is exactly the same pattern behind permissions, logs, and rollback for coding agents. It also applies to spreadsheets, docs, slides, inboxes, CRMs, and internal admin tools.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Domain Expertise Is the New Agentic Coding Moat
May 31, 2026 • 8 min read
Build Log: Turning the DevDigest Blog Into an Agent Content System
May 30, 2026 • 9 min read
Build Log: Adding Product Paths to a Content Site Without Making It Salesy
May 30, 2026 • 8 min read
Build Log: How I Shipped a Tool Directory That Feeds Search, Compare, and RSS
May 30, 2026 • 9 min read
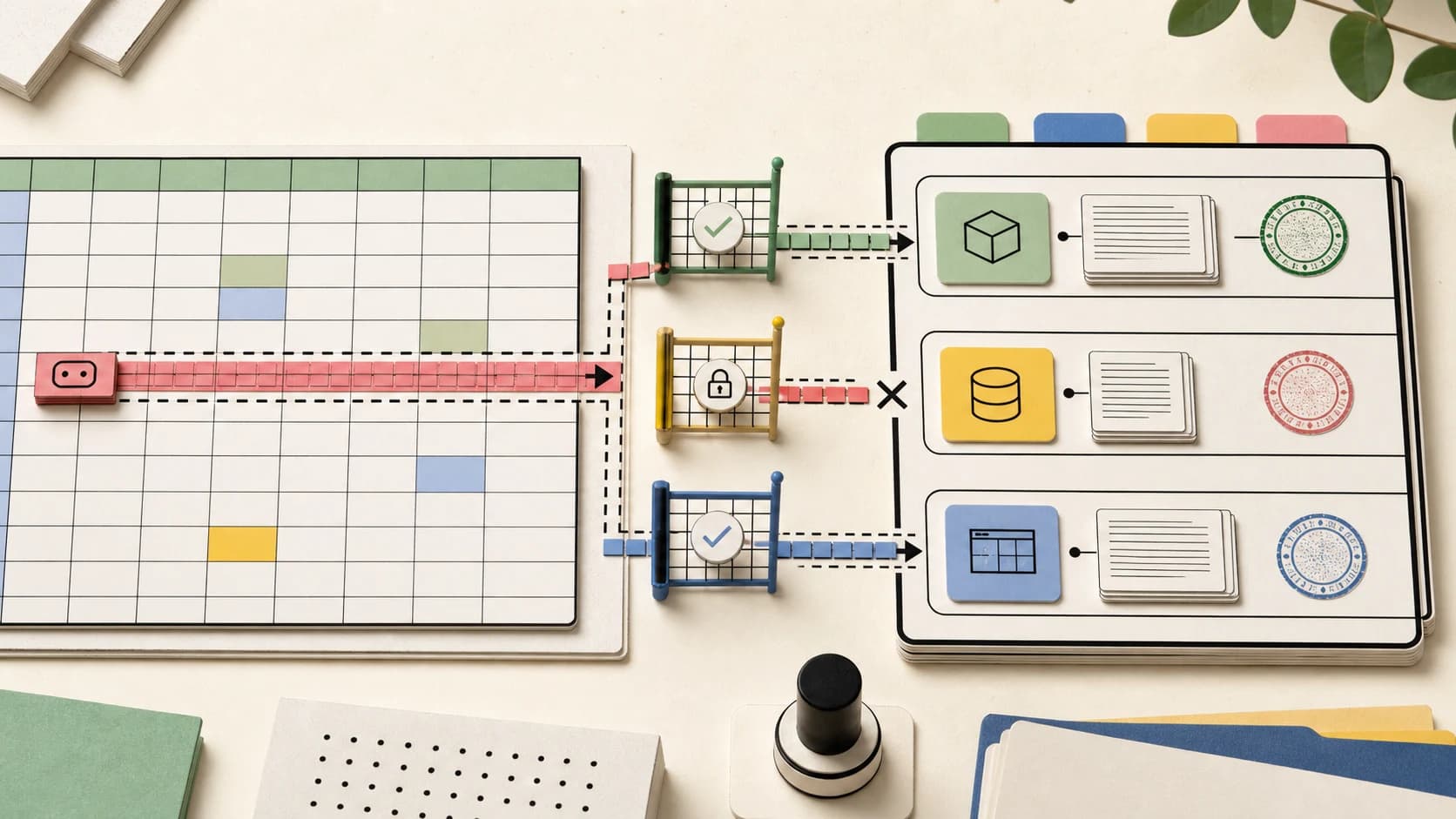
A Permission Ledger Beats a Permission Prompt#
A permission prompt is momentary.
Text
Allow ChatGPT to edit this sheet?
A permission ledger is persistent.
Text
capability: read current workbook
scope: workbook A only
source: user approval at 10:14
allowed actions: read cells, summarize values
blocked actions: external network, Apps Script, cross-workbook traversal
log: 14 reads, 0 writes, 0 scripts
revocation: immediate
The difference is not cosmetic.
A prompt asks the user to make a security decision while they are trying to finish work. A ledger turns the agent's authority into a reviewable object. The user, admin, auditor, or developer can inspect it after the fact.
For spreadsheet agents, the ledger should be visible at three levels:
- per workbook
- per assistant run
- per tool capability
That lets a user answer the important questions quickly:
- Did the agent read only this workbook?
- Did it follow links into other workbooks?
- Did it execute script code?
- Did it call the network?
- Did it keep running after I stopped the visible assistant response?
- Which data source caused the tool call?
If the product cannot answer those questions, "human in the loop" is mostly theater.
The Dangerous Boundary Is Data Becoming Authority#
The practical prompt-injection rule is still the same:
Text
External content is evidence.
External content is never authority.
That line from Prompt Injection in Agent Apps: The Practical Version is the simplest way to reason about this class of bug.
A spreadsheet cell can be evidence. A spreadsheet cell can contain a number, URL, vendor name, formula, note, or instruction written by someone else.
It should not become authority to expand the agent's permissions.
That means imported data should never be able to cause these transitions by itself:
- read one sheet -> read all linked workbooks
- summarize data -> execute script
- transform table -> call external URL
- edit visible cells -> overlay the assistant UI
- answer question -> keep running background code
Every transition from "read data" to "cause side effects" needs a separate capability boundary.
This is where generic AI safety copy fails. The model can be told not to follow malicious instructions, but the runtime still needs to enforce the boundary when the model gets confused.
Auto-Apply Is the Real Footgun#
PromptArmor notes that ChatGPT for Google Sheets had an "Apply edits automatically" setting that affected when human approvals were required before agentic actions.
That kind of setting is useful. It is also where products quietly collapse many actions into one mental bucket.
Editing a visible cell is not the same as running a script.
Running a script is not the same as reading another workbook.
Reading another workbook is not the same as sending data to the network.
An auto-apply setting should not be one switch. It should be a matrix:
| Capability | Safe default |
|---|---|
| Read current selection | Allow |
| Edit current selection | Ask or allow by workbook policy |
| Read whole current workbook | Ask |
| Follow links to other workbooks | Ask every time |
| Run script code | Block by default |
| Call external network | Block by default |
| Change assistant UI surface | Block |
| Continue background execution after stop | Block or show persistent run state |
That may feel heavier than a simple assistant sidebar. Good. Capability boundaries should be heavier than autocomplete.
For coding agents, we already accept this. Codex cloud security, Claude Code permissions, and sandboxed agent control planes all revolve around scoped execution. Office agents need the same seriousness because their data is often more sensitive than the repo.
The Minimum Architecture for Office Agents#
If you are building an agent for spreadsheets, documents, inboxes, or internal business systems, I would start with five controls.
First, separate read, write, script, network, and cross-document capabilities. Do not hide them behind one "access this app" grant.
Second, tag every tool call with the data source that influenced it. If an imported sheet caused a script request, the run log should say that clearly.
Third, make background work visible. If clicking stop only stops the assistant response while a script keeps executing, the UI is lying by omission.
Fourth, make untrusted content inert by default. Cells, comments, imported CSVs, and connector payloads should enter the model as quoted evidence, not instructions.
Fifth, give admins a policy surface. PromptArmor pointed to Google Workspace app access controls as an organizational mitigation. That is useful, but builders should not force every company to choose between "block the whole assistant" and "trust every tool path."
The product should expose narrower controls.
Where This Fits in the Agent Security Stack#
This incident sits between two common agent security mistakes.
The first mistake is approval fatigue. If every action asks for approval, users approve everything. That is why approval fatigue is an agent security bug.
The second mistake is invisible autonomy. If the agent can keep acting after the visible response stops, users do not have a meaningful chance to intervene.
The answer is not more scary dialogs.
The answer is a small number of understandable capabilities, safe defaults, persistent logs, and hard runtime boundaries. Prompt injection defense is not only prompt text. It is product architecture.
The Take#
The spreadsheet incident is a preview of the next year of AI security bugs.
Agents are moving from code editors into office suites, analytics tools, support queues, finance systems, and internal dashboards. Those environments are full of semi-trusted data. They also contain the actions attackers actually want: read records, export files, send messages, approve changes, modify dashboards, and trigger scripts.
If the agent can read untrusted content and use privileged tools in the same breath, the system needs a permission ledger.
Not a vague setting.
Not a one-time consent prompt.
Not a paragraph in the system prompt.
A ledger: what the agent could do, why it could do it, what data influenced it, what it actually did, and how to stop or reverse it.
That is the bar for agentic office tools now.
FAQ#
What is a permission ledger for AI agents?#
A permission ledger is a persistent record of what an AI agent is allowed to do, what scope each capability has, which approvals granted that authority, what actions actually happened, and how those actions can be stopped or reversed.
Why are spreadsheet agents risky?#
Spreadsheet agents are risky because spreadsheets often mix sensitive data, formulas, imported content, links to other files, and automation hooks. If an agent treats untrusted spreadsheet content as instructions, a prompt injection can turn data analysis into tool misuse.
Is prompt injection only a model problem?#
No. Prompt injection becomes dangerous when the surrounding product lets model output drive tool calls. The durable defense is to constrain the runtime: isolate untrusted content, scope tools, validate actions, log decisions, and require explicit approval for side effects.
Should AI spreadsheet tools disable scripting?#
Scripting should be blocked by default unless the product has strong capability separation, visible run state, scoped approvals, audit logs, and administrative controls. Some advanced users need scripting, but it should not share the same trust level as reading or editing visible cells.
Read next
Prompt Injection in Agent Apps: The Practical Version
Prompt injection stops being an abstract LLM risk once an agent can call tools. The practical defense is data boundaries, structured handoffs, tool guardrails, and approval gates around side effects.
8 min readPermissions, Logs, and Rollback for AI Coding Agents
AI coding agents become safer when permissions, logs, and rollback are designed as one system. Here is the operating loop I would put around any agent that can edit code, run tools, or open pull requests.
9 min readThe Agent Security Checklist I Use Before Connecting Tools
Before an AI agent gets tools, files, APIs, MCP servers, or deployment access, decide what it can read, write, call, log, and roll back.
8 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Frameworks
OpenAI Agents SDK
Lightweight Python framework for multi-agent systems. Agent handoffs, tool use, guardrails, tracing. Successor to the ex...
View ToolAI Frameworks
A
Agency Swarm
Multi-agent orchestration framework built on the OpenAI Agents SDK. Define agent roles, typed tools, and directional com...
View ToolAI CodingAgent
OpenAI Codex
OpenAI's coding agent for terminal, cloud, IDE, GitHub, Slack, and Linear workflows. Reads repos, edits files, runs comm...
View ToolAI FrameworksEssential
Vercel AI SDK
The TypeScript toolkit for building AI apps. Unified API across OpenAI, Anthropic, Google. Streaming, tool calling, stru...
View ToolApps from Developers Digest
Related Guides
Guide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsGuide
MCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
AI AgentsGuide
Building Your First MCP Server
Step-by-step guide to building an MCP server in TypeScript - from project setup to tool definitions, resource handling, testing, and deployment.
AI AgentsRelated Videos

Agents 101: How to Build and Deploy Anything with AI Agents
Build Anything with Vercel, the Agentic Infrastructure Stack Check out Vercel: https://vercel.plug.dev/cwBLgfW The video shows a behind-the-scenes walkthrough of how the creator rapidly builds and d
Video·

TRAE: Custom AI Agents That Actually Understand Your Codebase
Check out Trae here! https://tinyurl.com/2f8rw4vm In this video, we dive into @Trae_ai a newly launched AI IDE packed with innovative features. I provide a comprehensive demonstration...
Video·

OpenAI's New TypeScript Agents SDK
Getting Started with OpenAI's New TypeScript Agents SDK: A Comprehensive Guide OpenAI has recently unveiled their Agents SDK within TypeScript, and this video provides a detailed walkthrough...
Video·
Related Posts

8 min read
AI Security
Prompt Injection in Agent Apps: The Practical Version
Prompt injection stops being an abstract LLM risk once an agent can call tools. The practical defense is data boundaries...
9 min read
AI Security
Permissions, Logs, and Rollback for AI Coding Agents
AI coding agents become safer when permissions, logs, and rollback are designed as one system. Here is the operating loo...
8 min read
AI Security
The Agent Security Checklist I Use Before Connecting Tools
Before an AI agent gets tools, files, APIs, MCP servers, or deployment access, decide what it can read, write, call, log...

7 min read
AI Agents
Approval Fatigue Is an Agent Security Bug
Manual approval prompts stop protecting users when coding agents ask too often. The better pattern is risk-aware autonom...

8 min read
AI Agents
Sandboxed Agents Are Becoming the Team Control Plane
Runtime's Launch HN thread is a useful signal: teams do not just want isolated coding agents. They want a control plane...
10 min read
OpenAI Codex
OpenAI Codex Cloud Security Playbook 2026: Internet Access, Prompt Injection, and Safe Defaults
A practical security playbook for running Codex cloud tasks safely in 2026 using OpenAI docs: internet access controls,...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever