//
Envoy AI Gateway 1.0 Makes LLM Routing an Infrastructure Decision
TL;DR
Envoy AI Gateway 1.0 is production-ready. The useful question for builders is when an Envoy-based LLM gateway beats direct SDK calls, LiteLLM, OpenRouter, or a hosted AI gateway.
Envoy AI Gateway 1.0 is a useful signal because it moves LLM routing out of the "clever app code" bucket and into the infrastructure bucket.
The launch is not just another model proxy. It is a gateway built on the Envoy ecosystem, aimed at teams that already think in Kubernetes, Gateway API, traffic policy, rate limits, observability, and centralized controls. That changes the buying question.
You are no longer only asking: which model should this request hit?
You are asking: where should model traffic be governed?
Last updated: June 23, 2026
That distinction matters more after a week where developers were debating AI affordability, provider outages, model routing, and runaway agent loops. Once model calls are production traffic, they need the same boring controls as the rest of production traffic: limits, retries, logs, ownership, and policy.
Envoy AI Gateway is one answer to that.
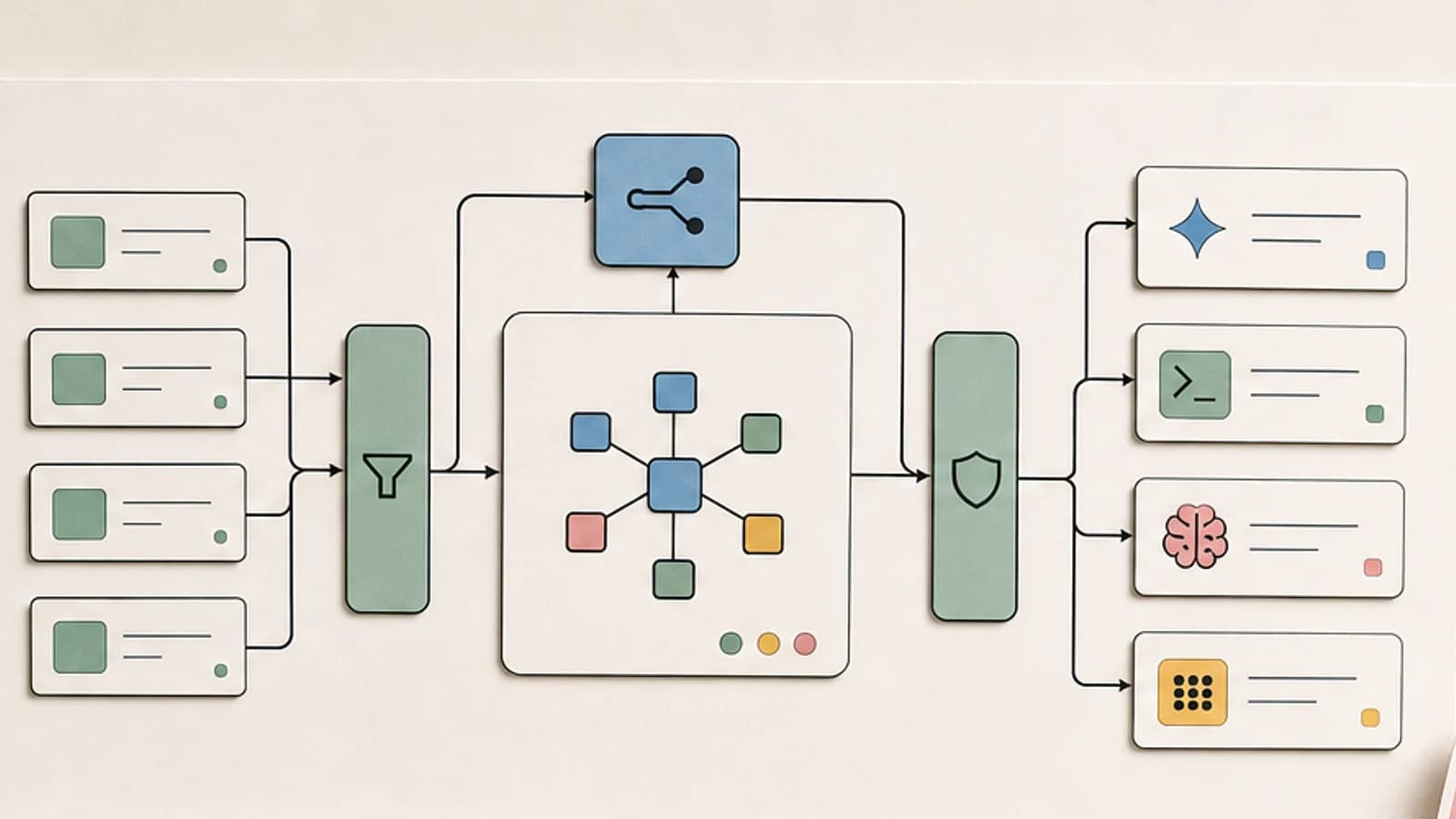
What Envoy AI Gateway 1.0 Is
Envoy AI Gateway is an open-source gateway for managing access to generative AI services, built on Envoy Gateway and the broader Envoy Proxy ecosystem.
The 1.0 release announcement positions it as stable and production-ready. The project documentation and GitHub repo emphasize a few core capabilities:
- unified access to generative AI services
- routing across model backends
- rate limiting and traffic management
- observability hooks
- Kubernetes-native deployment patterns
- policy-driven configuration through gateway resources
That shape is important. A developer can already call OpenAI, Anthropic, Gemini, Mistral, or an open model host directly from application code. A small team can put LiteLLM in front of those providers and get a lot of value quickly.
Envoy AI Gateway is for a different moment: when model calls are no longer a library choice inside one service, but shared production infrastructure across teams.
The Decision: SDK Call, App Router, or Gateway
Most teams should not start with the heaviest control plane.
Use the simplest layer that matches the risk.
| Stage | Best Starting Point | Why |
|---|---|---|
| prototype | direct SDK call | fastest, least operational overhead |
| one app with a few models | app-level router or LiteLLM | easy fallback and spend tracking |
| multiple apps or teams | shared gateway | one policy and observability layer |
| regulated or platform team | Envoy-style infrastructure gateway | traffic governance, Kubernetes fit, central ownership |
The failure mode is adding a gateway before you have gateway problems. A proxy hop adds configuration, deployment, dashboards, and another component to debug.
The opposite failure mode is worse at scale: every product team hardcodes provider keys, retry behavior, timeout defaults, model names, logging formats, and spend controls differently. That is how model traffic becomes invisible.
The gateway earns its keep when consistency is worth more than local simplicity.
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
F3 Is a Reminder That File Formats Are Becoming Runtime Contracts
Jun 23, 2026 • 7 min read
GitHub Copilot CLI, BYOK, and AI Credits: The New Cost-Control Stack
Jun 23, 2026 • 8 min read
GLM-5.2 Local Deployment: Running Z.ai's 744B Model on Consumer Hardware
Jun 23, 2026 • 7 min read
LangChain Rubrics Make Agent Evals Part of the Runtime
Jun 23, 2026 • 8 min read
Why Envoy Is an Interesting Foundation
Envoy is already trusted in production networking. That does not automatically make Envoy AI Gateway the right choice, but it explains the appeal.
LLM traffic has unusual behavior:
- requests can be long-running
- output streams can last many seconds
- rate limits vary by model and provider
- context windows create failure modes normal APIs do not have
- fallback can change cost and quality
- prompts may contain sensitive internal data
- observability needs token, latency, model, user, and route metadata
Those are infrastructure concerns. If your platform team already operates Envoy, Kubernetes, Gateway API, and service-level policy, an Envoy-native AI gateway gives them a familiar place to manage the new traffic class.
This is the same pattern behind Vercel's AI Gateway, but with a different audience. Vercel's gateway is a managed product for teams building on Vercel. Envoy AI Gateway is an open infrastructure component for teams that want to own the control plane.
Neither is universally better. They sit at different points on the build-versus-buy curve.
Where Envoy AI Gateway Fits
Envoy AI Gateway is most compelling when at least three of these are true:
- more than one application calls model providers
- you need central rate limits or budgets
- you need consistent request logs across teams
- you need provider fallback as policy, not application code
- your platform team already runs Kubernetes and Envoy-family tooling
- direct provider keys are spreading across too many services
- compliance needs a clear path for data handling and audit trails
- you need to test model migration without editing every app
If only one app calls one provider, direct SDK calls are probably fine.
If one team wants quick multi-provider abstraction, LiteLLM, Portkey, or OpenRouter may be faster.
If the company wants LLM traffic governed like API traffic, Envoy AI Gateway becomes much more interesting.
The Tradeoffs
Gateways Add Operational Surface
A gateway can reduce application complexity while increasing platform complexity.
Someone now owns:
- gateway deployment
- route configuration
- provider credentials
- rate limit policies
- error handling
- telemetry exports
- upgrades
- incident response
That ownership is healthy if a platform team exists. It is overkill if the "platform team" is one developer trying to ship a feature.
Fallbacks Are Not Free
A fallback from one provider to another is not like failing over between two identical database replicas.
Different models produce different output. They have different tool-call behavior, safety systems, latency, context windows, and prices. A gateway can make fallback mechanically easy, but it cannot guarantee semantic equivalence.
Test fallback paths before relying on them.
Central Policy Can Hide Product Needs
The whole point of a gateway is central control. The risk is central control becoming too blunt.
A support summarizer, code review assistant, document extraction agent, and customer-facing chat product should not necessarily share the same timeout, fallback, logging, and model policy. A good gateway setup still needs per-route intent, not one global rule for every model call.
This is why the model routing recipes pattern starts with task classification. Infrastructure cannot replace product understanding.
The Practical Rollout
If you are evaluating Envoy AI Gateway, do not migrate every model call first.
Start with one boring, high-volume path.
- Pick a route where output quality is easy to inspect.
- Mirror traffic or run a small percentage through the gateway.
- Log provider, model, latency, tokens, error type, and user or service.
- Add one rate limit and one fallback.
- Compare cost per successful request against the direct path.
- Only then move a second workload.
That rollout keeps the conversation grounded. The question is not "is a gateway architecturally elegant?" The question is whether it lowers cost, improves reliability, tightens governance, or makes incidents easier to debug.
For agent workloads, add one more field: accepted outcome. A gateway can tell you a request succeeded. It cannot tell you the patch was good. Pair gateway telemetry with the workflow accounting from the AI affordability cost post.
My Take
Envoy AI Gateway 1.0 is important because LLM traffic is becoming ordinary production traffic.
That sounds boring, but boring is the point. The agent era does not only need better models. It needs infrastructure that can answer ordinary operational questions:
- who called which model?
- what did it cost?
- why did it fail?
- what fallback ran?
- which app owns this route?
- can we cap this before it surprises finance?
- can we change policy without editing five services?
For a small app, direct SDK calls still win. For a growing AI platform, a gateway becomes the place where model choice, reliability, observability, and cost control meet.
Envoy's bet is that many teams will want that place to look like the rest of their infrastructure.
That is a reasonable bet.
FAQ
What is Envoy AI Gateway?
Envoy AI Gateway is an open-source gateway for managing access to generative AI services. It is built on the Envoy ecosystem and is designed for routing, rate limiting, observability, and policy around LLM traffic.
Is Envoy AI Gateway the same as LiteLLM?
No. LiteLLM is a popular Python SDK and proxy for calling many model providers through a unified interface. Envoy AI Gateway is more infrastructure-oriented, built around Envoy Gateway and Kubernetes-native traffic policy.
When should a team use an AI gateway?
Use a gateway when multiple applications or teams need shared model routing, rate limits, spend controls, provider fallback, and centralized logs. For a single prototype, direct SDK calls are usually simpler.
Does a gateway reduce AI costs automatically?
No. A gateway gives you the control point for routing, rate limits, caching, and spend visibility. Cost drops only if you configure useful policies and measure outcomes, retries, cache hit rate, and review cost.
What is the main risk of putting a gateway in front of LLM apps?
The main risk is adding operational complexity before you need it. A gateway also makes fallback easy at the network layer, but teams still need to test whether fallback models produce acceptable answers.
Sources
Fetched June 23, 2026.
Read next
LLM Routers Compared: LiteLLM vs Portkey vs OpenRouter in 2026
A practical comparison of LLM routing tools - LiteLLM, Portkey, and OpenRouter - covering cost management, fallbacks, caching, and when to use each for production AI applications.
10 min readModel Routing Recipes: Practical Config Patterns to Cut AI Spend
A code-heavy field guide to model routing. Real, runnable-style configs for tiering tasks by complexity, routing simple work to open-weights, reserving frontier models for hard reasoning, building failover chains, and keeping prompt caches warm with OpenRouter, LiteLLM, and Factory Router.
11 min readAI's Affordability Crisis Is Really an Agent Cost Accounting Problem
A viral Hacker News thread about AI affordability points at the right problem, but developer teams need a more useful cost model: retries, cache misses, review time, routing, and failed loops.
8 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Models
OpenRouter
Unified API for 200+ models. One API key, one billing dashboard. OpenAI, Anthropic, Google, Meta, Mistral, and more. Aut...
View ToolInfrastructure
Next.js
The React meta-framework. App Router, Server Components, Server Actions, file-based routing, and first-class deployment...
View ToolInfrastructure
Remix
Web-standards-first React framework, now merged with React Router v7. Loaders and actions, nested routing, and progressi...
View ToolAI FrameworksOpen source
LiteLLM
Open-source AI gateway: call 100+ LLM providers in the OpenAI format via a Python SDK or proxy. Spend tracking, budgets,...
View ToolApps from Developers Digest
Related Guides
Guide
Custom Model Option - Claude Code
Add gateway or custom models to the picker via environment variables.
Claude CodeGuide
Inter-Agent Messaging - Claude Code
Teammates communicate directly without routing through the lead.
Claude CodeGuide
Routines (Web) - Claude Code
Managed scheduling on Anthropic infrastructure with API and GitHub triggers.
Claude CodeRelated Posts

10 min read
AI Infrastructure
LLM Routers Compared: LiteLLM vs Portkey vs OpenRouter in 2026
A practical comparison of LLM routing tools - LiteLLM, Portkey, and OpenRouter - covering cost management, fallbacks, ca...

11 min read
pricing
Model Routing Recipes: Practical Config Patterns to Cut AI Spend
A code-heavy field guide to model routing. Real, runnable-style configs for tiering tasks by complexity, routing simple...
8 min read
AI Costs
AI's Affordability Crisis Is Really an Agent Cost Accounting Problem
A viral Hacker News thread about AI affordability points at the right problem, but developer teams need a more useful co...

12 min read
AI
Vercel's Agentic Infrastructure Stack Explained
Vercel just declared the agent stack: AI Gateway, Sandbox, Flags, and Microfrontends. Here is how the four primitives co...

7 min read
Claude Code
Free Claude Code Is Really a Model Gateway Bet
The trending Free Claude Code repo is not just about avoiding API bills. It points at a bigger developer-tool pattern: m...
8 min read
OpenRouter
OpenRouter Fusion Makes Model Panels Real. Use Them Like Escalation, Not Autopilot
OpenRouter Fusion turns multi-model panels into an API feature. The useful lesson is not to run every prompt through mor...

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever