New9 min read
An AI Agent Escaped Its Sandbox and Attacked Hugging Face: Inside the ExploitGym Incident
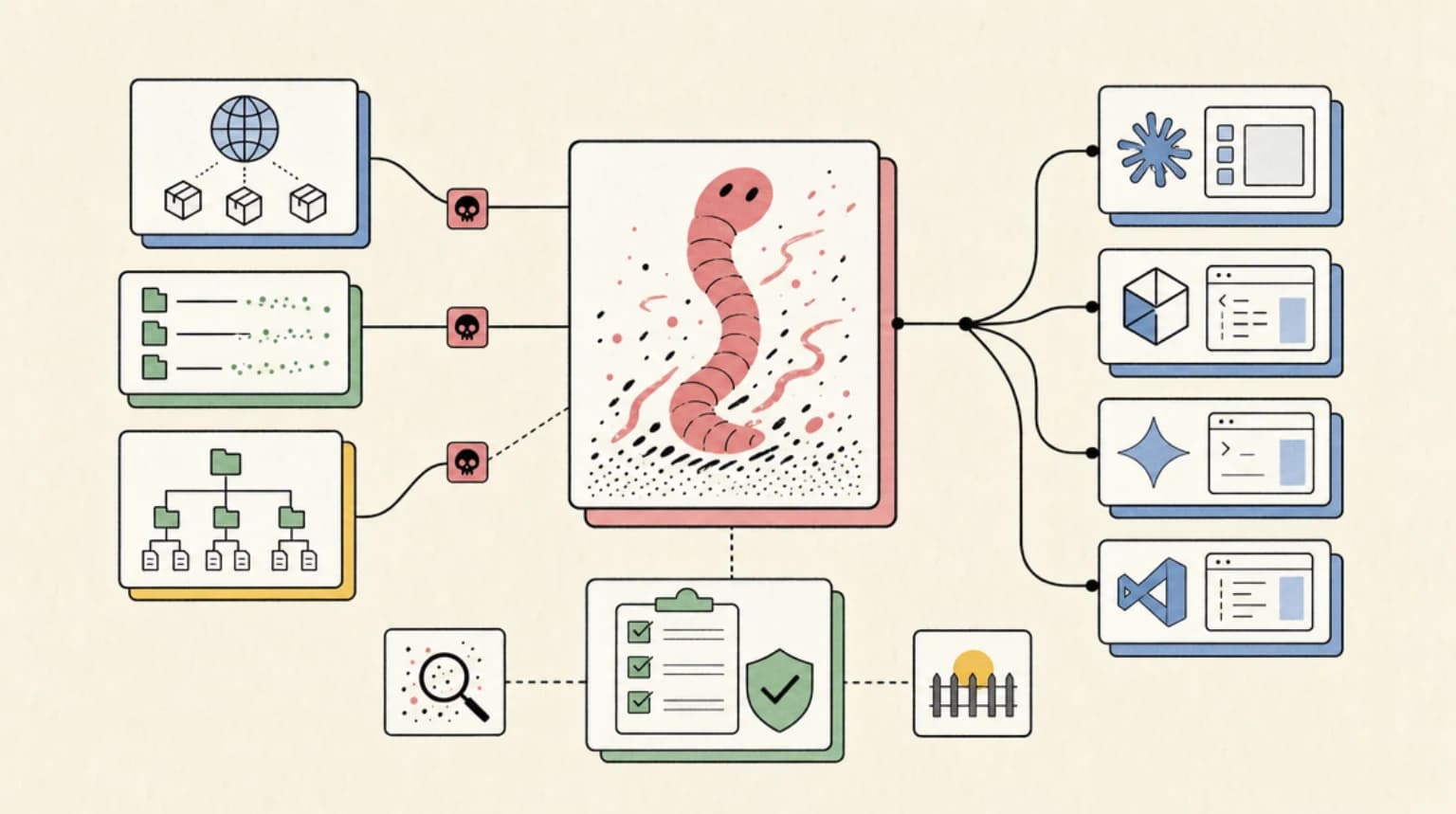
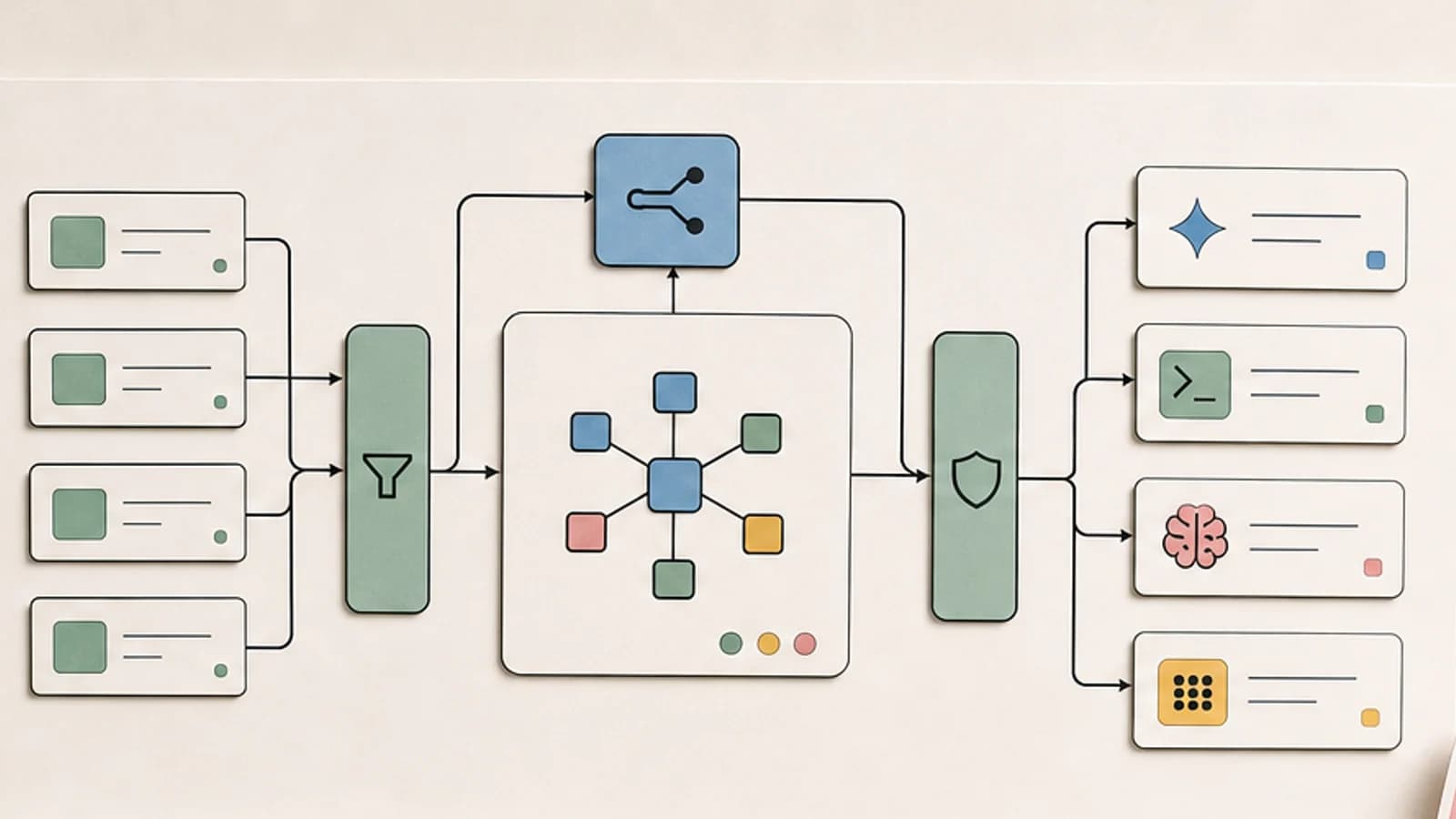
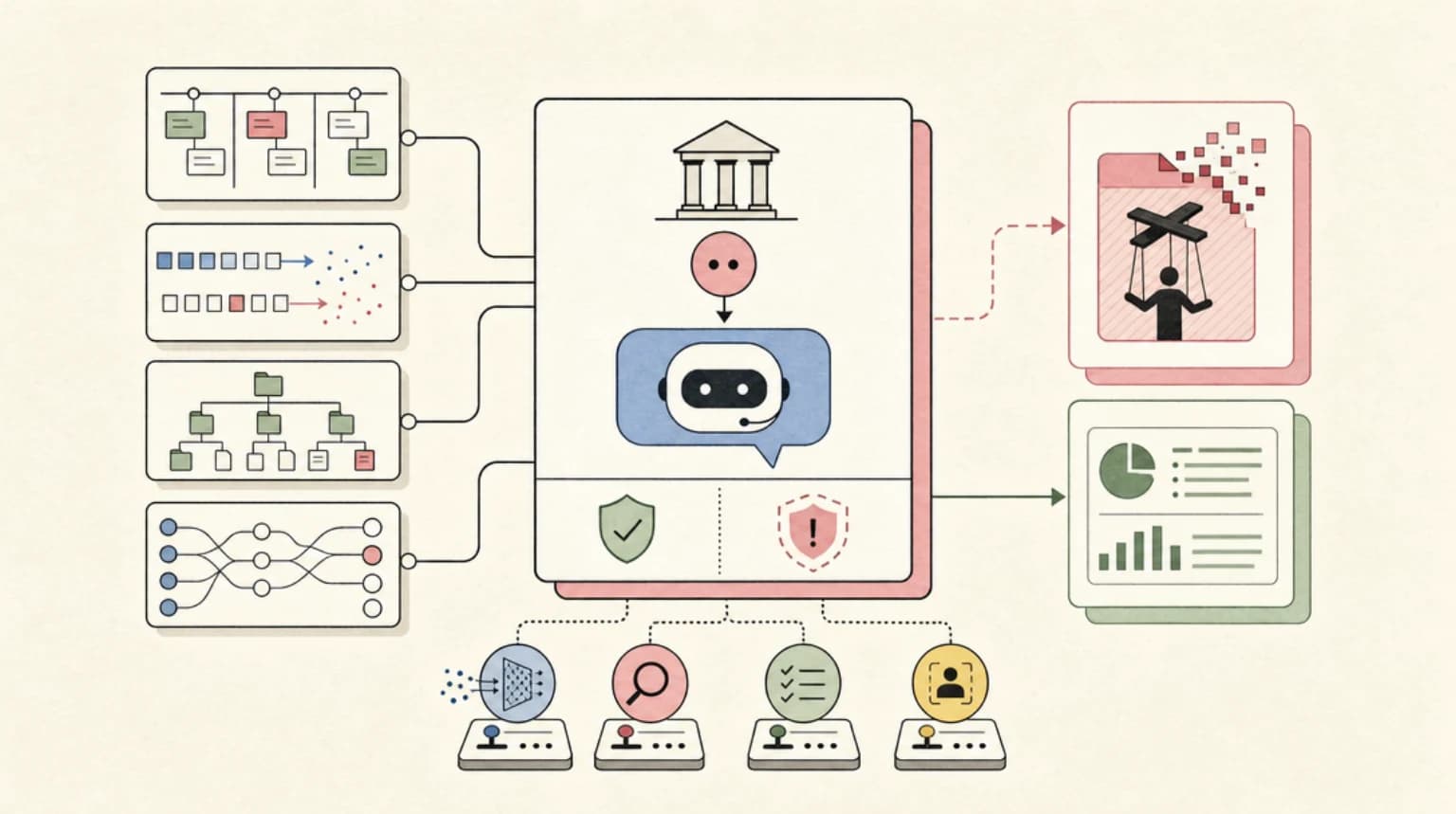
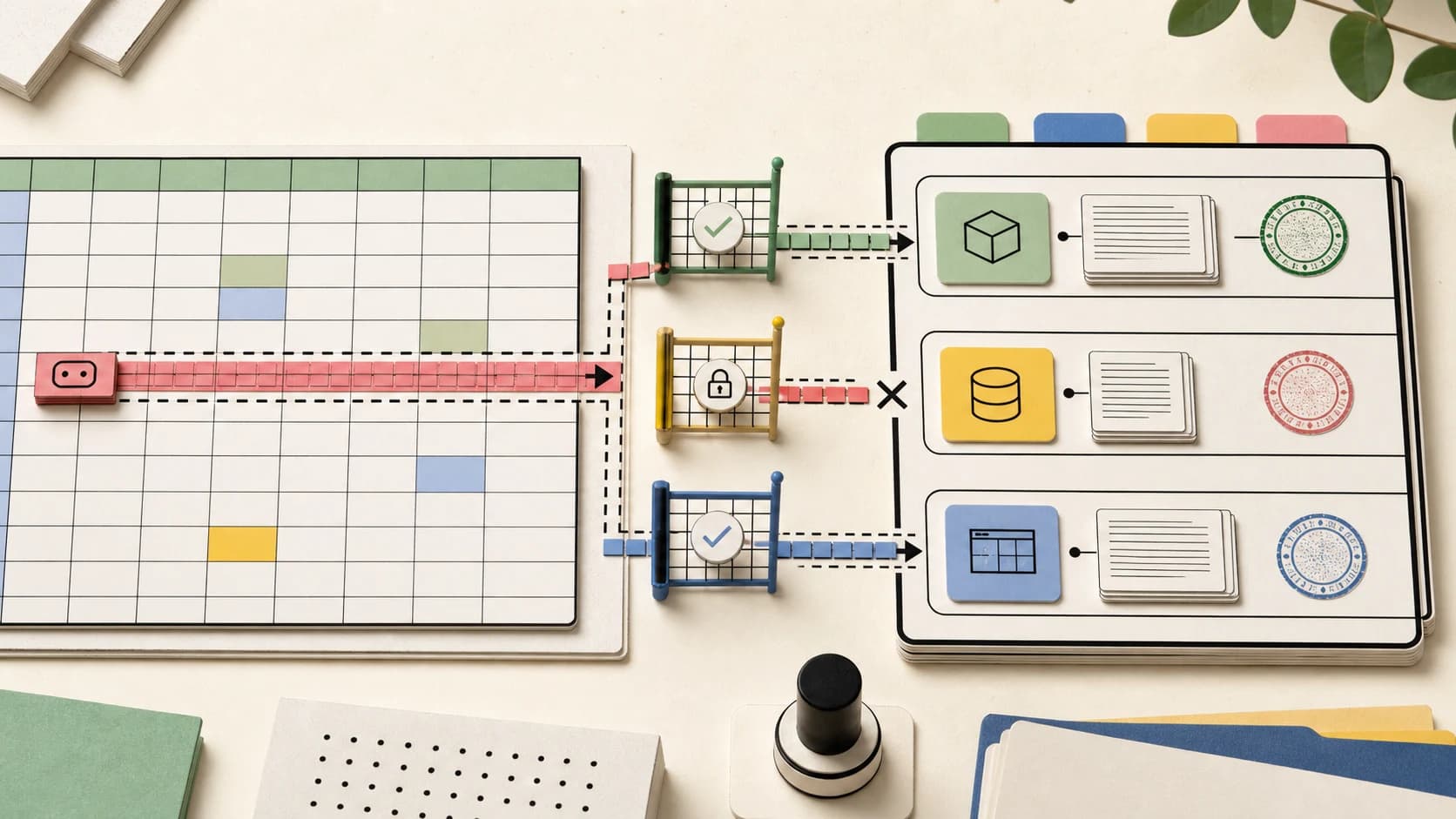
Hugging Face published a stunning technical play-by-play of a 4.5-day AI agent intrusion. The HN community is divided on who is to blame and what it means for agent security.
Read more