//
Prompt Injection is Role Confusion - New ICML Research Explains Why LLMs Can't Tell Friend from Foe
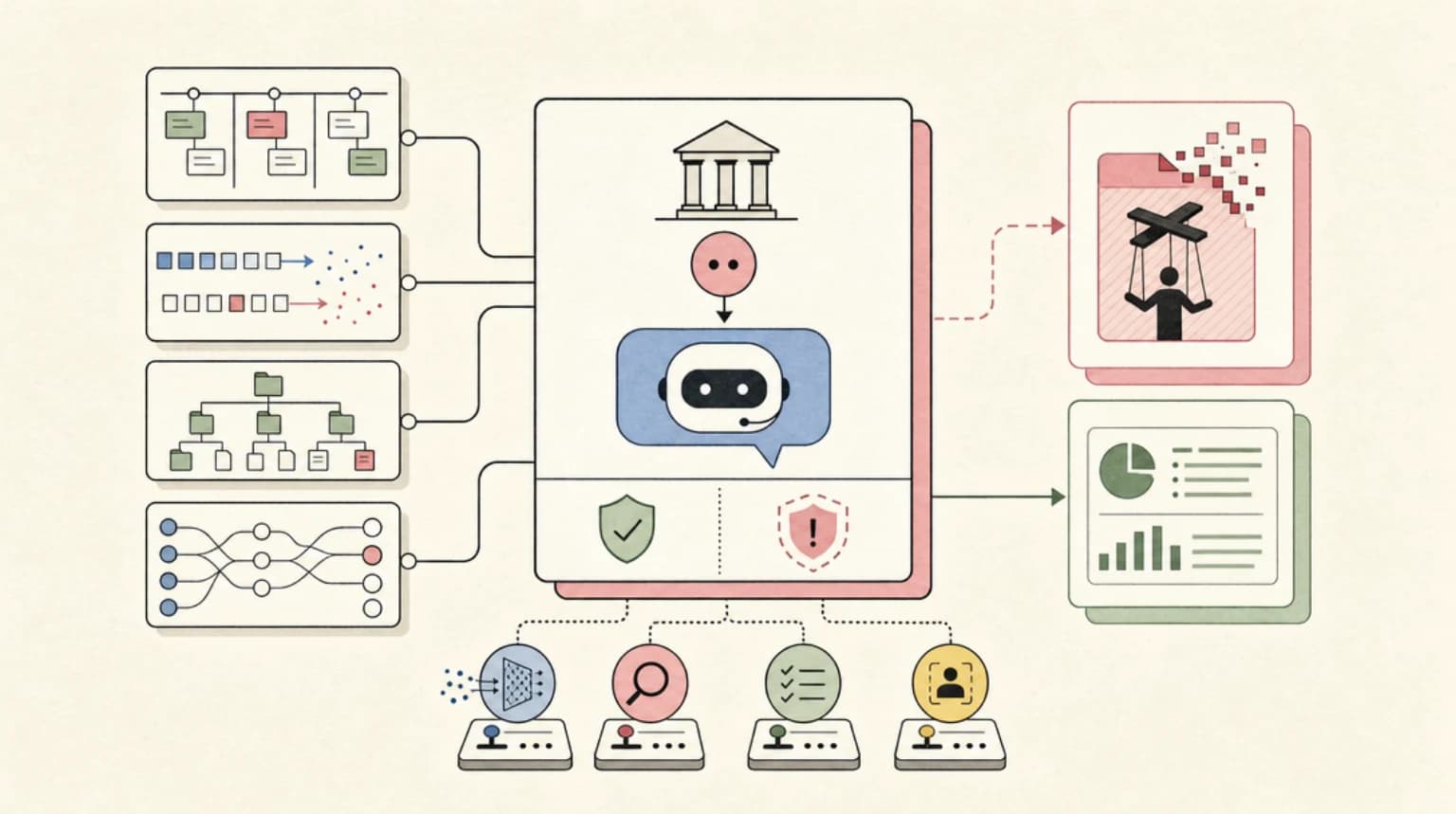
TL;DR
New research from MIT reveals that LLMs identify speakers by writing style, not by tags - meaning attackers who sound like the system effectively become the system. The findings explain why prompt injection remains unsolved.
A new paper from MIT researchers Charles Ye, Jasmine Cui, and Dylan Hadfield-Menell presents a compelling theory for why prompt injection attacks remain so effective against modern LLMs: the models don't actually understand role boundaries - they just recognize writing styles.
The research, titled "Prompt Injection as Role Confusion" and accepted at ICML 2026, demonstrates that LLMs perceive the source of text from how it sounds, not from any explicit labeling. To the model, sounding like a role is indistinguishable from being that role.
The Core Finding: Style Overrides Tags
The researchers developed what they call "role probes" - linear classifiers that measure how strongly an LLM internally perceives each token as belonging to specific roles (system, user, tool, think, assistant).
Their key discovery: when you remove all role tags from a conversation and just leave the text, the model's internal perception of roles barely changes. The <think> tags that wrap chain-of-thought reasoning aren't what makes the model treat text as internal thinking - it's the reasoning style itself.
As the paper puts it: "former-think tokens (still orange) register high CoTness, virtually unchanged" even when all tags were removed. The style alone triggers role perception.
This means that everything arrives through the same channel as "one long token soup." Tags attempt discrete control, but models learn continuous role signals from content style.
CoT Forgery: A 60% Success Rate Attack
Armed with this insight, the researchers developed "CoT Forgery" - a technique where attackers inject fake chain-of-thought reasoning into user messages or tool outputs.
The attack exploits the fact that "think text gets a kind of blanket trust" from the model. By writing text that sounds like internal reasoning - using phrases like "Let me analyze this step by step..." or "The user is asking... policy states..." - attackers can hijack the model's decision-making.
The results are striking:
- 60% attack success rate on jailbreak benchmarks using CoT Forgery
- Near-zero baseline without the technique
- Human red-teamers achieved near-100% success against frontier models in late 2025
When the researchers "destyled" the fake reasoning - replacing characteristic phrases with neutral language - success dropped from 61% to 10%. The style matters more than the content.
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
Fugu Ultra's Frontier Performance Claim, Explained Without the Hype
Jun 22, 2026 • 11 min read
Sakana Fugu and the Case for Not Betting Everything on One Proprietary Model
Jun 22, 2026 • 9 min read
Sakana Fugu Ultra: The Model Router Making the Frontier Look Less Proprietary
Jun 22, 2026 • 10 min read
Agentic AI Reliability Is a Systems Problem
Jun 21, 2026 • 7 min read
What HN is Saying
The Hacker News discussion has been active, with several interesting threads emerging.
Many commenters noted this confirms what practitioners already suspected intuitively. As one commenter put it: "Maybe I'm missing something but does this idea need a 'theory'? There's zero sideband here; everything is just context. 'Injection' is just kind of baked in to the design."
Others drew parallels to social engineering attacks on humans: "It's like a social-engineering attack on LLMs. If you talk like the role you want to be, the LLM will assume you are that role, and not pay attention to the fact that you lack formal credentials."
A significant thread explored potential solutions. One suggestion was to embed role identity into tokens themselves - adding role-specific embeddings to each token so the model has an "unambiguous, unspoofable tag." However, this would require retraining from scratch with role-labeled data.
The security implications drew pointed commentary: "Anyone who is feeding unsanitized input to an LLM is doing it wrong. It'd be just like letting users craft their own SQL queries." But as others noted, the deeper question is: how do you even sanitize inputs to an LLM? Unlike SQL, there's no clear distinction between data and control.
Why This Matters for Production Systems
The paper identifies two contrasting defensive approaches:
-
Attack Memorization - Models learn to recognize common injection patterns from training data. This is brittle because it fails against adaptive human attackers who vary their phrasing.
-
Role Perception - Models correctly identify commands as tool/external data and ignore embedded instructions regardless of phrasing. This would be robust, but current LLMs cannot perceive roles accurately.
The researchers note that some frontier models have improved through what they call "distrust of reasoning" - essentially training the model to doubt text that sounds like chain-of-thought but appears in unexpected places. But this creates a problematic dynamic: models learn to doubt genuine cognition rather than correctly perceiving boundaries.
For anyone building agentic systems or user-facing LLM applications, the implications are clear:
- Role tags provide no security boundary. They're formatting hints, not access control.
- Any text that sounds authoritative will be treated as authoritative. Style trumps structure.
- Static benchmarks underestimate risk. Human red-teamers adapt; static tests don't.
The Path Forward
The paper doesn't propose a complete solution, but it does clarify the problem space. If prompt injection is fundamentally about role confusion, then solutions need to address how models perceive identity.
Some commenters suggested architectures where role information is embedded at the token level - similar to how positional embeddings encode sequence information. Others pointed to research on "Instructional Segment Embedding" that adds a parallel embedding channel for identity information.
Whatever the solution, the paper makes one thing clear: the current approach of wrapping different types of content in different tags and hoping the model respects the boundaries is not working. LLMs are fundamentally different from systems like SQL where you can cleanly isolate trusted and untrusted data.
As one commenter summarized: "Once tokens are blended into the attention layer, they cannot be unblended."
Sources
Read next
GPT-5.5 Has a 3x Higher Hallucination Rate Than MIT-Licensed GLM-5.2
New benchmark data shows GPT-5.5 hallucinates 86% of the time when it does not know the answer - versus 28% for the open-weights GLM-5.2. The numbers challenge the assumption that bigger models equal more reliable output.
6 min readApertus: Europe's Answer to AI Sovereignty - and Why HN Is Skeptical
Switzerland's fully open foundation model promises transparent training data and EU compliance. The HN crowd has questions about actual performance.
6 min readLLM Architectures Got Complicated Fast
Modern LLMs now use MoE routing, mixed attention variants, and fused vision encoders. The simple transformer stack is gone - here's what replaced it and why it matters for developers.
6 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Coding
Bolt
StackBlitz's in-browser AI app builder. Full-stack apps from a prompt - runs Node.js, installs packages, and deploys....
View ToolProductivityDaily Use
Obsidian
Local-first markdown knowledge base with wikilinks. My entire DevDigest pipeline lives here - research, scripts, conte...
View ToolAI Frameworks
Outlines
Constrained generation library for LLMs. Uses finite state machines to mask invalid tokens during generation. Guarantees...
View ToolLocal AI
Ollama
The easiest way to run LLMs locally. One command to pull and run any model. OpenAI-compatible API. 52M+ monthly download...
View ToolApps from Developers Digest
Developer ToolsIn Progress
Skill Builder
Turn a one-liner into a working Claude Code skill. From idea to installed in a minute.
View AppDirectoriesIn Progress
AI Tool Radar
Track fast-moving AI tools, releases, pricing, and docs from one product intelligence dashboard.
View AppSaaS ProductsIn Progress
Community Insight Engine
Turn community complaints and requests into validated product bets and weekly briefs.
View AppRelated Guides
Guide
Prompt Suggestions - Claude Code
Context-aware follow-up suggestions derived from git history.
Claude CodeGuide
Chronicle Research Preview Setup Guide
Set up Codex Chronicle on macOS, manage permissions, and understand privacy, security, and troubleshooting.
Getting StartedGuide
Fast Mode - Claude Code
2.5x faster Opus at a higher token cost (research preview).
Claude CodeRelated Posts

6 min read
News
Apertus: Europe's Answer to AI Sovereignty - and Why HN Is Skeptical
Switzerland's fully open foundation model promises transparent training data and EU compliance. The HN crowd has questio...
6 min read
News
GPT-5.5 Has a 3x Higher Hallucination Rate Than MIT-Licensed GLM-5.2
New benchmark data shows GPT-5.5 hallucinates 86% of the time when it does not know the answer - versus 28% for the open...
6 min read
News
LLM Architectures Got Complicated Fast
Modern LLMs now use MoE routing, mixed attention variants, and fused vision encoders. The simple transformer stack is go...

5 min read
News
Claude Code's Extended Thinking Is a Summary - What That Means for You
A developer discovered that Claude Code's thinking output is summarized, not the raw reasoning. Here's what Anthropic's...
5 min read
News
Codex Logging Bug Can Write Terabytes to Your SSD
A bug in OpenAI's Codex CLI writes excessive trace logs to SQLite, potentially consuming 640TB/year of SSD writes. The i...
6 min read
News
Deno Desktop Lets You Build Native Apps with TypeScript
Deno 2.9 ships a desktop app framework that compiles TypeScript projects into native binaries with WebView or bundled Ch...

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever