//
Sakana Fugu Ultra: The Model Router Making the Frontier Look Less Proprietary
TL;DR
Sakana Fugu Ultra is not just another giant model. It is a learned orchestration layer that routes work across expert models, matches frontier benchmark claims, and makes a serious case for multi-model AI systems.
Official Sources
| Source | What it covers |
|---|---|
| Sakana Fugu release | June 22 launch, benchmark framing, product positioning |
| Sakana Fugu product page | Architecture, pricing, API behavior, EU availability |
| Fugu technical report | Methodology and benchmark details |
| TRINITY paper | Evolved LLM coordinator accepted to ICLR 2026 |
| Conductor paper | RL-trained natural-language agent orchestration |
Sakana AI's latest release is important because it changes the unit of competition. Fugu Ultra is not marketed as a single monolithic model that beats everyone by being bigger. It is a language model trained to coordinate other language models, exposed through one OpenAI-compatible API.
That sounds like a wrapper until you look at the details. Fugu decides whether to answer directly, delegate to specialist agents, verify intermediate work, call itself recursively, and synthesize the final answer. The pitch is simple: the next frontier may be less about owning one giant proprietary model and more about learning how to route across many strong models.
Last updated: June 22, 2026.
What Sakana Fugu Actually Is
Sakana describes Fugu as a multi-agent system delivered as one model. You send one request. Behind the endpoint, Fugu can select models, assign roles, coordinate several steps, and return a single answer.
Source image: Sakana Fugu product page.
The launch has two tiers:
| Model | Best fit | Tradeoff |
|---|---|---|
| Fugu | Everyday coding, code review, chatbots, interactive work | Better latency, lower orchestration depth |
| Fugu Ultra | Hard multi-step work like research, cyber analysis, paper reproduction, patent review | Higher quality target, more latency and cost |
The standard Fugu tier also lets teams opt specific agents out of the pool for privacy, compliance, or data-governance reasons. Fugu Ultra is positioned differently: maximum answer quality from a deeper pool, with less user control over exactly what participates.
The Benchmark Claim
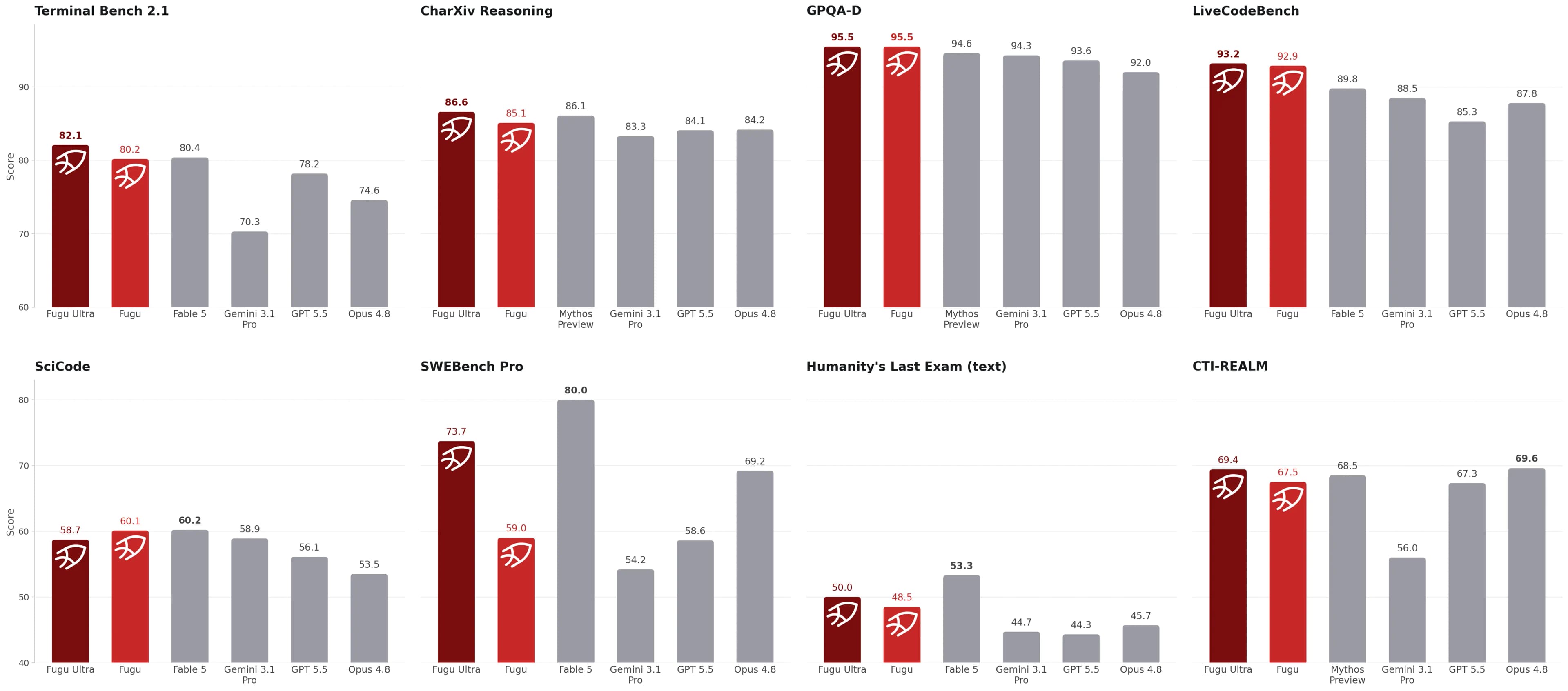
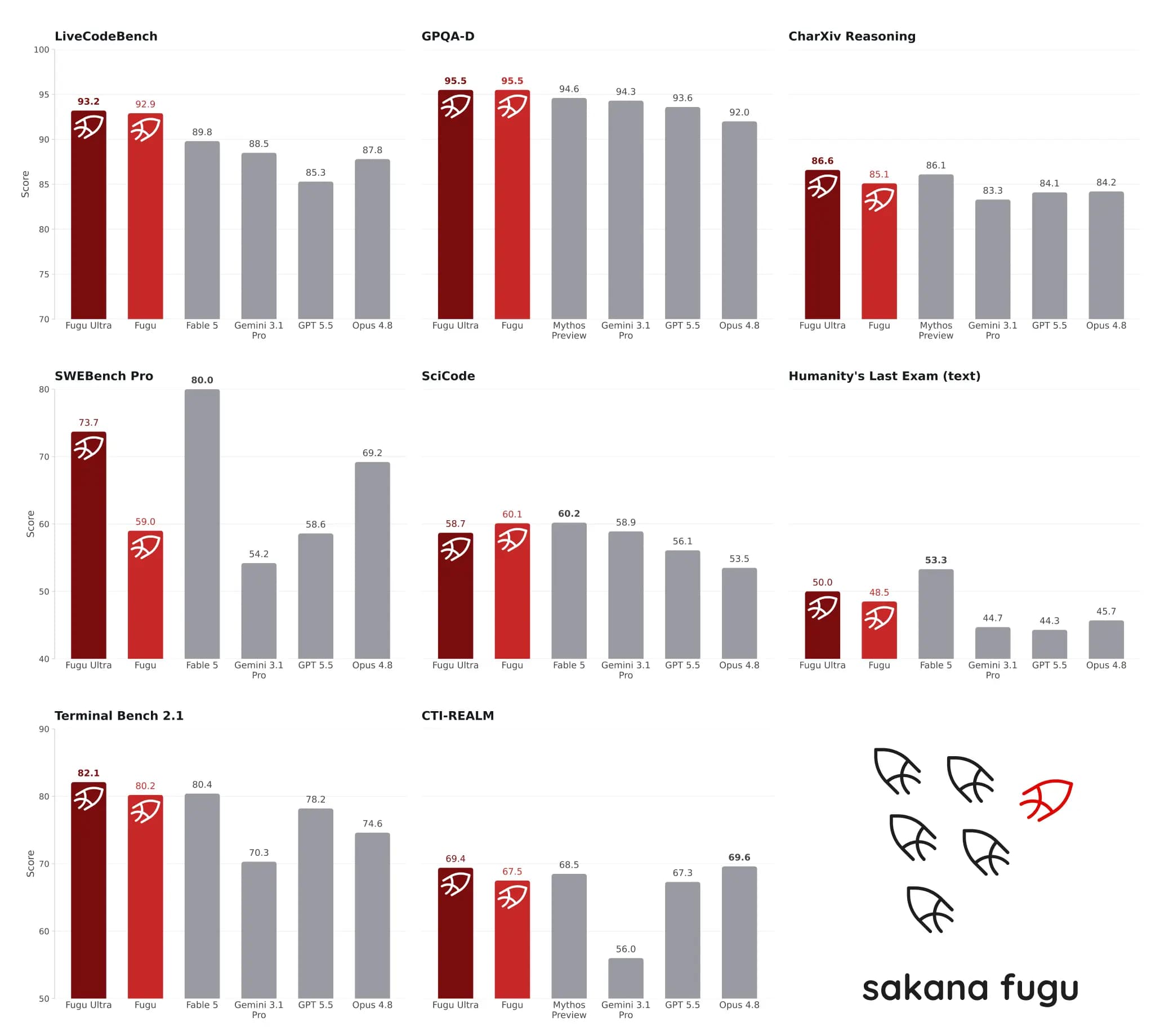
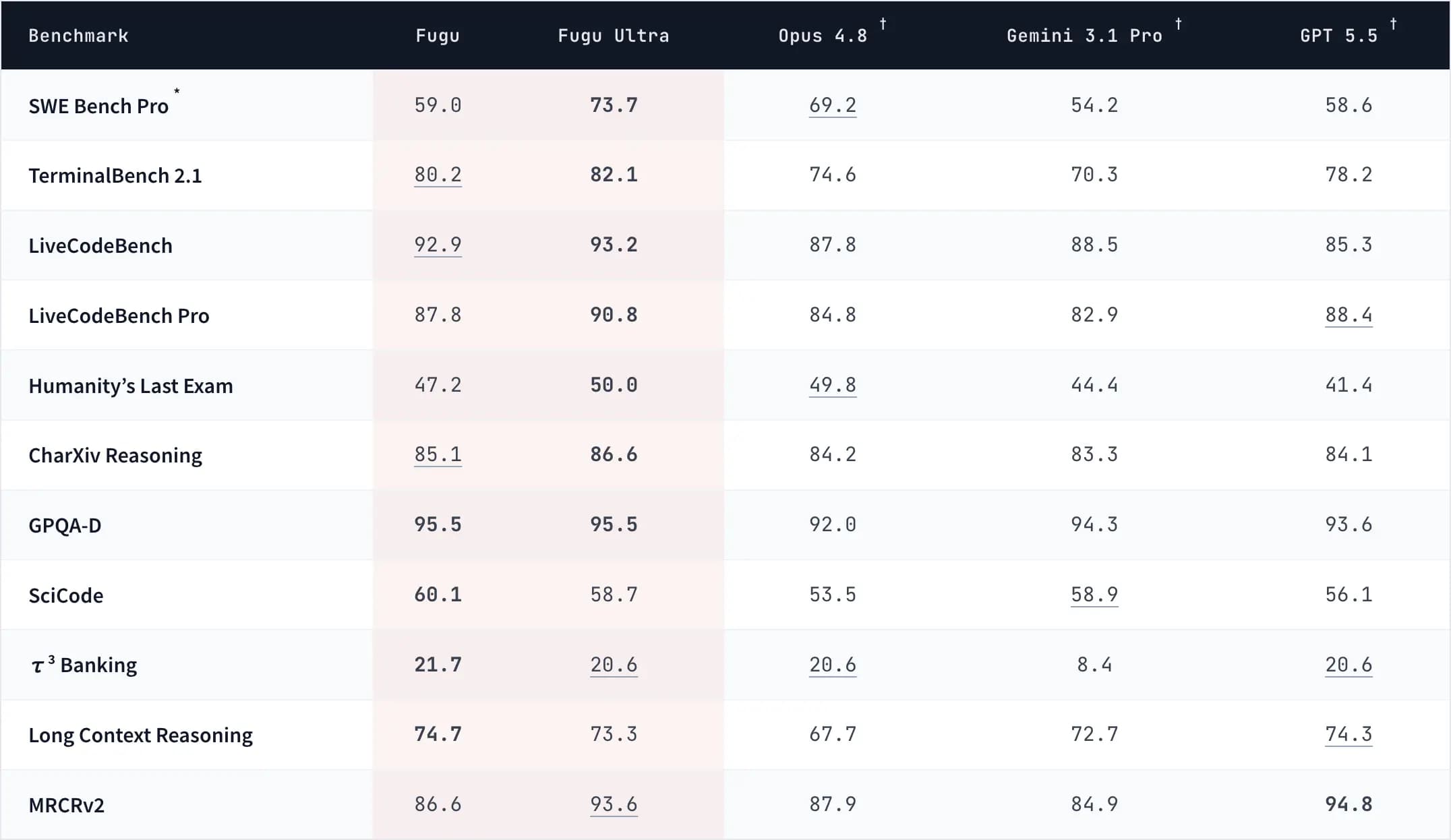
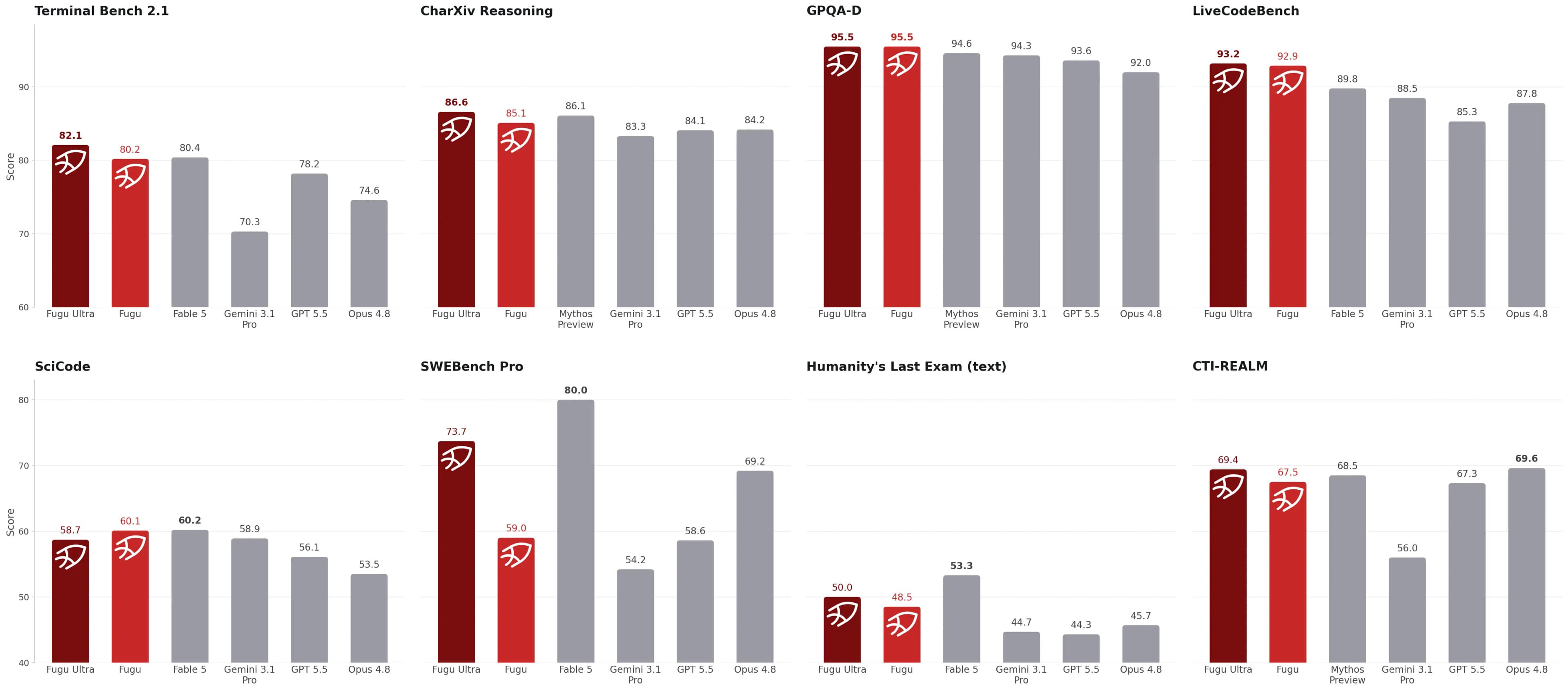
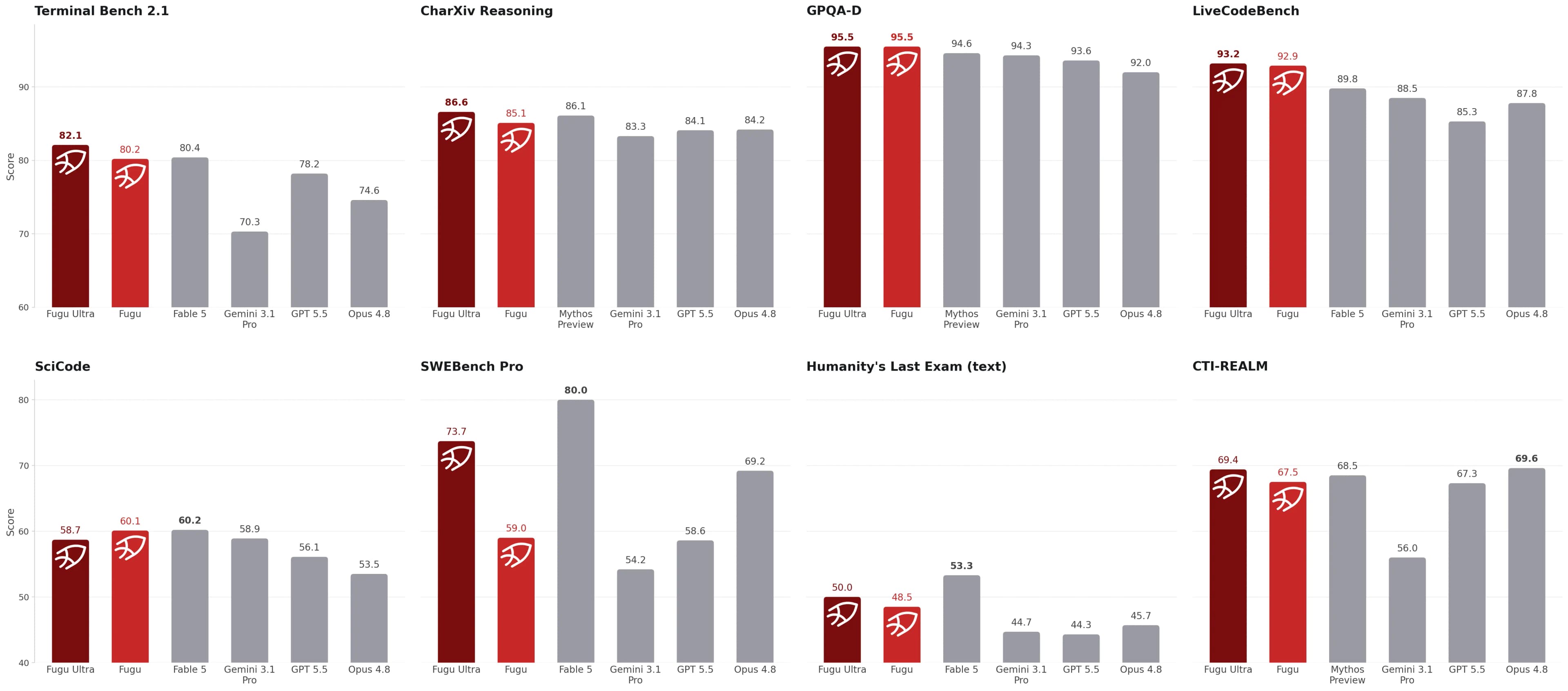
Sakana's headline claim is that Fugu Ultra stands with models such as Anthropic Fable 5 and Mythos Preview across engineering, scientific, and reasoning benchmarks. The release also compares Fugu and Fugu Ultra against provider-reported scores for Opus 4.8, Gemini 3.1 Pro, and GPT-5.5.
Source image: Sakana Fugu release.
The detailed table is more useful than the headline. It shows Fugu Ultra ahead on several coding and reasoning benchmarks, including SWE-bench Pro, TerminalBench 2.1, LiveCodeBench, LiveCodeBench Pro, Humanity's Last Exam, and CharXiv Reasoning. Fugu itself leads on some others, including SciCode, tau3 Banking, and long-context reasoning in Sakana's table.
Source image: Sakana Fugu release.
The caveats matter:
- Baseline scores other than Fugu's are provider-reported.
- Fable 5 and Mythos Preview are not in Fugu's agent pool because they are not publicly accessible.
- The Fable/Mythos comparison uses the higher score where both are available on the same benchmark.
- The SWE-bench Pro result uses mini-swe-agent as scaffolding.
That does not make the result meaningless. It means the right reading is "Sakana reports frontier-class performance from orchestration" rather than "an independent lab proved Fugu is strictly better than every frontier model."
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
Why This Is More Than a Router
Most model routing is simple: classify the request, pick the cheapest model likely to work, call it once.
Fugu is closer to a learned conductor. Sakana points to two ICLR 2026 papers as the technical base.
TRINITY uses a lightweight coordinator to assign Thinker, Worker, and Verifier roles across multiple LLMs over several turns. The paper reports that this coordinator can outperform individual models across coding, math, reasoning, and knowledge tasks.
Conductor goes further. It trains a 7B model with reinforcement learning to discover natural-language coordination strategies among worker models. The paper says the Conductor learns both communication topologies and focused instructions, and can adapt to arbitrary pools of open and closed agents.
That is the novel part. Fugu is not just "Claude for planning, GPT for writing, Gemini for checking" hardcoded into a workflow. The claim is that coordination itself is learned.
The Case for Model Routing
The strongest practical reason to care is not novelty. It is operational leverage.
Better cost-performance. Easy subtasks can go to cheaper or faster models. Hard subtasks can escalate. If the router is good, you get frontier-ish output without paying frontier prices for every token.
Better specialization. Coding, long-context synthesis, math, visual reasoning, and structured critique are not the same skill. A single model may be good enough at all of them, but a coordinated pool can route around individual weaknesses.
Better resilience. If one provider changes pricing, policy, availability, or regional access, a swappable pool can degrade more gracefully than a single-model dependency.
Better product ergonomics. Calling one API while getting multi-agent behavior is cleaner than building and maintaining your own routing harness, eval loop, retry policy, and synthesis layer.
This is the same reason agent teams work in software engineering. The win is not that every agent is smarter than the best solo agent. The win is that planning, execution, verification, and synthesis are different jobs.
The Non-Proprietary Point
Sakana frames Fugu as a response to single-vendor dependency. That is partly technical and partly geopolitical.
If your application depends on one proprietary frontier model, your product inherits that provider's pricing, outage profile, account policy, export-control exposure, regional availability, and product roadmap. That is a lot of business logic to outsource to one model vendor.
Fugu does not eliminate proprietary dependency. It still calls models in an underlying pool, and Sakana does not expose every routing decision. But it changes the dependency shape. Instead of your application being wired directly to one provider, your application is wired to an orchestrator that can swap providers behind the scenes.
That is valuable if the orchestrator is trustworthy and observable enough for your use case. It is dangerous if it becomes a new opaque dependency you cannot audit.
Benefits
| Benefit | Why it matters |
|---|---|
| One OpenAI-compatible API | Easier migration than rebuilding an agent framework |
| Learned routing | Potentially better than hand-authored if/else model selection |
| Recursive orchestration | More inference-time compute on hard tasks without changing your app |
| Provider opt-out in Fugu | Useful for compliance and privacy-sensitive teams |
| Frontier-class benchmark claims | Serious enough to evaluate on real workloads |
| Swappable agent pool | A hedge against single-provider changes |
Tradeoffs
| Tradeoff | Why it matters |
|---|---|
| Opaque routing | You may not know which model handled which part of a task |
| Latency variance | Multi-step orchestration is slower than a direct call |
| Cost variance | Fugu Ultra can be expensive on deep tasks |
| Benchmark caveats | Baselines are provider-reported, not all independently reproduced |
| EU/EEA unavailability | Sakana says it is working through GDPR and EU-specific regulations |
| New single point of failure | The orchestrator can become the dependency you were trying to avoid |
Who Should Try It
Try Fugu Ultra if you already run expensive, long, multi-step work: code review, security analysis, research synthesis, paper reproduction, data-science exploration, benchmark triage, or patent/literature review.
Start with standard Fugu if latency matters and the task is interactive. Use Fugu Ultra only where answer quality is worth the response-time and cost premium.
Stick with direct model calls when the task is simple, low-risk, latency-sensitive, or easy to verify with deterministic code. Routing overhead is not free. A clean single-model call is still the best architecture for many product surfaces.
FAQ
What is Sakana Fugu?
Sakana Fugu is a multi-agent orchestration system exposed as one OpenAI-compatible model API. Internally, it can select, coordinate, verify, and synthesize work across an agent pool.
What is Fugu Ultra?
Fugu Ultra is the quality-maximized tier for hard multi-step problems. It coordinates a deeper pool of expert agents and is aimed at research, cybersecurity, paper reproduction, code review, and other demanding workflows.
Is Fugu Ultra an open model?
No. Fugu is a commercial Sakana product. The non-proprietary angle is not that Fugu itself is open-weight. It is that Fugu orchestrates a swappable pool instead of forcing your application to depend directly on one proprietary model provider.
Does Fugu Ultra beat GPT-5.5 or Claude?
Sakana reports higher scores than several provider-reported frontier baselines on multiple benchmarks. Treat that as a serious launch claim, not final truth. Validate it on your own evals before replacing a production model.
Can I control which models Fugu uses?
Standard Fugu lets teams opt specific agents out of the pool for privacy, compliance, or organizational requirements. Fugu Ultra is optimized for maximum quality and gives less control over the full pool.
Is model routing worth it?
It is worth it when tasks are heterogeneous, expensive, or multi-step. It is overkill for simple prompts where one fast model already clears the quality bar.
Sources
- Sakana Fugu release - verified June 22, 2026
- Sakana Fugu product page - verified June 22, 2026
- SakanaAI/fugu technical report repository - verified June 22, 2026
- TRINITY: An Evolved LLM Coordinator - verified June 22, 2026
- Learning to Orchestrate Agents in Natural Language with the Conductor - verified June 22, 2026
- Sakana AB-MCTS post - verified June 22, 2026
- Anthropic Fable/Mythos access context - verified June 22, 2026
Read next
GLM-5.2 Cost Math: When Open-Weights Coding Models Actually Save You Money
Z.ai's GLM-5.2 lands as a 753B open-weights coding model that beats GPT-5.5 on SWE-bench Pro for roughly one-sixth the per-token cost. Here is the real cost math, a worked cost-per-task example, and a when-to-use-which decision guide.
9 min readFrontier Model API Pricing, June 2026: Claude vs OpenAI vs Gemini vs DeepSeek
Same-day-verified llm api pricing june 2026: Claude Fable 5, GPT-5.5, Gemini 3.1 Pro, and DeepSeek V4 compared per million tokens, plus the three caveats that change the math.
10 min readWhat a Fleet of Claude Agents Actually Costs (June 2026 Math)
Claude Code parallel agents cost real money because every session draws from one quota - here is the June 2026 budgeting math, verified against live pricing.
10 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI CodingOpen source
DeepSeek-TUI
Open-source terminal agent runtime with approval modes, rollback snapshots, MCP servers, LSP diagnostics, and a headless...
View ToolAI Models
OpenRouter
Unified API for 200+ models. One API key, one billing dashboard. OpenAI, Anthropic, Google, Meta, Mistral, and more. Aut...
View ToolAI Models
Gemini
Google's frontier model family. Gemini 2.5 Pro has 1M token context and top-tier coding benchmarks. Gemini 3 Pro pushes...
View ToolAI Models
Claude Haiku 4.5
Anthropic's smallest Claude 4.5 model. Near-frontier coding performance at one-third the cost of Sonnet 4 and up to 4-5x...
View ToolApps from Developers Digest
Related Guides
Guide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsGuide
MCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
AI AgentsGuide
Run AI Models Locally with Ollama and LM Studio
Install Ollama and LM Studio, pull your first model, and run AI locally for coding, chat, and automation - with zero cloud dependency.
Getting StartedRelated Posts
9 min read
pricing
GLM-5.2 Cost Math: When Open-Weights Coding Models Actually Save You Money
Z.ai's GLM-5.2 lands as a 753B open-weights coding model that beats GPT-5.5 on SWE-bench Pro for roughly one-sixth the p...

10 min read
pricing
Frontier Model API Pricing, June 2026: Claude vs OpenAI vs Gemini vs DeepSeek
Same-day-verified llm api pricing june 2026: Claude Fable 5, GPT-5.5, Gemini 3.1 Pro, and DeepSeek V4 compared per milli...
10 min read
claude-code
What a Fleet of Claude Agents Actually Costs (June 2026 Math)
Claude Code parallel agents cost real money because every session draws from one quota - here is the June 2026 budgeting...
8 min read
ai-agents
Omnigent: Databricks' Meta-Harness for Orchestrating Claude Code, Codex, and Custom Agents
Databricks open-sourced Omnigent, a meta-harness that sits above individual agent CLIs so your sessions, policies, and s...
11 min read
ai-benchmarks
Fugu Ultra's Frontier Performance Claim, Explained Without the Hype
Sakana says Fugu Ultra stands with Fable, Mythos, GPT-5.5, Gemini, and Opus by orchestrating models instead of being one...
9 min read
model-routing
Sakana Fugu and the Case for Not Betting Everything on One Proprietary Model
Sakana Fugu makes a timely argument for model routing: frontier performance should come from swappable systems, not a ha...

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever