//
Fugu Ultra's Frontier Performance Claim, Explained Without the Hype
TL;DR
Sakana says Fugu Ultra stands with Fable, Mythos, GPT-5.5, Gemini, and Opus by orchestrating models instead of being one giant model. Here is what the benchmarks show, what is novel, and what still needs proof.
Official Sources
| Source | What it covers |
|---|---|
| Sakana Fugu release | Fugu Ultra launch and benchmark charts |
| Sakana Fugu product page | Architecture, pricing, API, applications |
| Fugu technical report | Benchmark methodology |
| TRINITY paper | Evolved coordinator research |
| Conductor paper | RL orchestration research |
Sakana Fugu Ultra is one of the more interesting model releases of 2026 because the claim is both bold and easy to misread.
Sakana is not saying it trained a single new base model that simply outruns GPT-5.5, Gemini 3.1 Pro, Opus 4.8, Fable 5, and Mythos Preview. It is saying learned orchestration can reach frontier performance by coordinating multiple models through one API.
That distinction matters. If the claim holds up under independent testing, the next jump in AI capability may come from better routing, verification, and test-time coordination, not only bigger proprietary training runs.
Last updated: June 22, 2026.
The Benchmark Picture
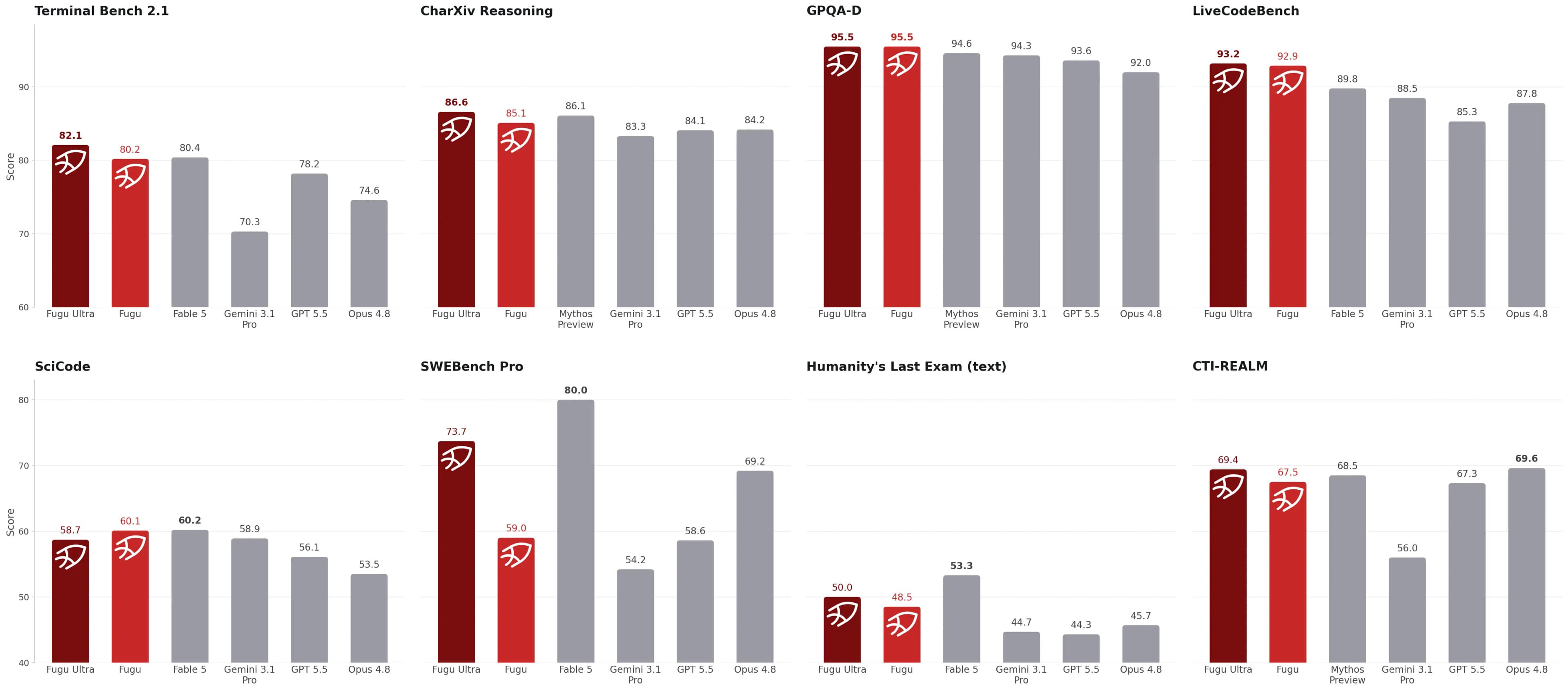
Sakana's launch chart places Fugu and Fugu Ultra against frontier baselines across coding, reasoning, science, agentic work, and long-context tasks.

Source image: Sakana Fugu release.
The table gives the more concrete numbers. In Sakana's release, Fugu Ultra is reported at:
- 73.7 on SWE-bench Pro
- 82.1 on TerminalBench 2.1
- 93.2 on LiveCodeBench
- 90.8 on LiveCodeBench Pro
- 50.0 on Humanity's Last Exam
- 86.6 on CharXiv Reasoning
- 95.5 on GPQA-D
- 93.6 on MRCRv2

Source image: Sakana Fugu release.
Those numbers put Fugu Ultra in the same conversation as the most expensive frontier systems. But there are important footnotes:
- Non-Fugu baseline scores are provider-reported.
- Fable 5 and Mythos Preview are not publicly accessible and are not in Fugu's agent pool.
- Sakana uses the max score where Fable 5 and Mythos Preview both have scores on the same benchmark.
- SWE-bench Pro uses mini-swe-agent scaffolding.
So the right conclusion is not "case closed." The right conclusion is "this is a serious orchestration result that deserves workload-level evals."
Why The Result Is Plausible
The intuitive argument for Fugu is simple: hard tasks are not one skill.
A complex coding task might require:
- reading a long issue
- finding relevant files
- forming a plan
- writing a patch
- spotting an edge case
- running tests
- explaining the change
One giant model can do all of that. But it may not be the best planner, implementer, critic, and synthesizer at the same time. A routed system can assign those jobs differently.

Source image: Sakana Fugu product page.
Sakana's research points in exactly that direction. TRINITY assigns Thinker, Worker, and Verifier roles. Conductor learns natural-language coordination strategies through reinforcement learning. Earlier Sakana work on AB-MCTS explores inference-time search and multi-model cooperation.
The big idea is test-time scaling. Instead of making the model bigger before inference, spend more coordination and verification compute during inference.
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
What Is Novel
Three parts stand out.
First, the orchestrator is itself a model. Fugu is trained to call other LLMs and can call instances of itself recursively. That is different from a static router.
Second, coordination is learned. The Conductor paper says a 7B model can learn communication topologies and targeted prompts for a worker pool. This is closer to learned project management than provider selection.
Third, the agent pool is swappable. Sakana's product framing is that Fugu can route around unavailable or restricted providers and incorporate new models as they arrive.
Put together, this makes Fugu a bet on AI systems rather than AI models. The intelligence is partly in the base workers and partly in the coordination policy.
The Benefit For Developers
For developers, the value is not philosophical. It is whether you can get better task outcomes with less bespoke infrastructure.
Fugu is useful if it lets you avoid building:
- your own model router
- your own retry policy
- your own planner-worker-verifier loop
- your own benchmark-specific prompt routing
- your own model-fallback logic
- your own answer synthesis step
The single API matters. Teams already have enough moving parts in agent products. If a model endpoint can hide orchestration complexity and still produce better results, that is a real product improvement.
The Case Against Solely Proprietary AI
The obvious alternative is to pick one top proprietary model and use it everywhere. That is still a reasonable default for small teams.
But the risk profile is getting worse:
- model access can become regional
- prices can move
- rate limits can bind
- safety policies can change behavior
- roadmap changes can deprecate models
- frontier performance can rotate between labs
Model routing gives teams a way to avoid treating one provider as permanent infrastructure. It also makes open models more valuable. An open model does not need to beat the best closed model at everything if it is the best worker for one common subtask.
That is the strongest version of the argument. The future may be less "open model beats closed model" and more "open, closed, local, and specialized models cooperate under a routing policy."
What Still Needs Proof
The main missing piece is independent evaluation.
Sakana's benchmark release is detailed, but provider-reported baselines and mixed comparison conditions leave room for uncertainty. The results should be replicated by independent harnesses on real tasks.
The second missing piece is routing observability. Teams will want to know:
- which model saw which data
- why a model was selected
- how much each step cost
- where failures occurred
- whether a compliance opt-out was respected
The third missing piece is cost-per-successful-task. A routed model can look expensive per token but cheap per outcome if it solves hard tasks in fewer attempts. It can also look cheap in theory and expensive in practice if it uses too many internal calls.
For production teams, the metric is not benchmark score. It is successful task completion per dollar, with latency and governance constraints included.
A Sensible Evaluation Plan
If you want to test Fugu Ultra, do not start with a vibe check. Use a workload sample.
- Pick 30 to 100 real tasks from your backlog.
- Split them into simple, medium, and hard.
- Run your current best model, standard Fugu, and Fugu Ultra.
- Grade blind where possible.
- Track wall-clock time, tokens, retries, failure modes, and reviewer edits.
- Compare cost per accepted answer, not cost per token.
The likely result: Fugu Ultra will be most interesting on hard multi-step work and least interesting on fast simple prompts.
FAQ
Did Sakana train a new frontier base model?
Not in the usual sense. Fugu is presented as a learned orchestration model that coordinates a pool of agents through one API.
Does Fugu Ultra use Fable 5 or Mythos Preview?
Sakana says Fable 5 and Mythos Preview are not in Fugu's agent pool because they are not publicly accessible. They are benchmark comparison points.
Are the benchmarks independently verified?
Not fully. Sakana reports Fugu results directly, while many baseline scores are provider-reported. Independent workload testing is still needed.
Why is model routing important?
Routing lets teams match tasks to model strengths, reduce single-provider dependency, and use test-time coordination for hard tasks instead of relying only on one giant model call.
Is Fugu Ultra better than direct GPT-5.5 or Claude calls?
It may be for complex multi-step tasks. It may not be for latency-sensitive or simple tasks. The right answer depends on cost per successful task in your workload.
What is the biggest tradeoff?
Opacity. A powerful orchestrator can improve outcomes, but it can also make debugging, auditing, and compliance harder if it does not expose enough routing detail.
Sources
- Sakana Fugu release - verified June 22, 2026
- Sakana Fugu product page - verified June 22, 2026
- SakanaAI/fugu technical report repository - verified June 22, 2026
- TRINITY: An Evolved LLM Coordinator - verified June 22, 2026
- Learning to Orchestrate Agents in Natural Language with the Conductor - verified June 22, 2026
- Sakana AB-MCTS post - verified June 22, 2026
- Anthropic Fable/Mythos access context - verified June 22, 2026
Read next
Sakana Fugu Ultra: The Model Router Making the Frontier Look Less Proprietary
Sakana Fugu Ultra is not just another giant model. It is a learned orchestration layer that routes work across expert models, matches frontier benchmark claims, and makes a serious case for multi-model AI systems.
10 min readSakana Fugu and the Case for Not Betting Everything on One Proprietary Model
Sakana Fugu makes a timely argument for model routing: frontier performance should come from swappable systems, not a hard dependency on one proprietary API.
9 min readClaude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
Fable 5 launched June 9 at 2x GPT-5.5's price with a 22-point SWE-Bench Pro gap. Here is the decision framework for choosing between them.
7 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
Related Guides
Guide
MCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
AI AgentsGuide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsGuide
Building Your First MCP Server
Step-by-step guide to building an MCP server in TypeScript - from project setup to tool definitions, resource handling, testing, and deployment.
AI AgentsRelated Posts
10 min read
ai-models
Sakana Fugu Ultra: The Model Router Making the Frontier Look Less Proprietary
Sakana Fugu Ultra is not just another giant model. It is a learned orchestration layer that routes work across expert mo...
9 min read
model-routing
Sakana Fugu and the Case for Not Betting Everything on One Proprietary Model
Sakana Fugu makes a timely argument for model routing: frontier performance should come from swappable systems, not a ha...

7 min read
Claude
Claude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
Fable 5 launched June 9 at 2x GPT-5.5's price with a 22-point SWE-Bench Pro gap. Here is the decision framework for choo...

8 min read
Benchmarks
FrontierCode Benchmark Explained: Why AI Coding Quality Scores Are Wrong (And the Fix)
SWE-Bench has an 81% false-positive problem. FrontierCode replaces it with mergeability as the metric - and the scores a...
11 min read
ai-models
The Router Era: Why Not Owning a Frontier Model Became an Advantage
No single model wins every task anymore, and the companies that never trained one - Factory, Devin, Perplexity, Cursor,...
11 min read
claude-code
Claude Code Permissions: A Practical settings.json Guide for Allow, Deny, and Ask Rules
Stop the approval-fatigue prompts without going full YOLO mode. A hands-on guide to Claude Code's permission system - se...

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever