Topic
PROMPT INJECTION
Prompt injection in LLM and agent applications - untrusted content, tool-output attacks, guardrails, and practical mitigations.
5 resources - 5 posts
Blog Posts
View in blog →
Prompt Injection Is Really Role Confusion
New role-confusion research explains why prompt injection keeps surviving better prompts. Models do not reliably perceive which text is instruction, tool output, user content, or their own reasoning.
8 min read

The One-Cent Attack: Prompt Injection Through Bank Transfer Memos
Security researchers showed a €0.02 bank transfer could compromise a banking AI assistant. Here is the exact attack chain - and what every developer building agents needs to do differently.
8 min read
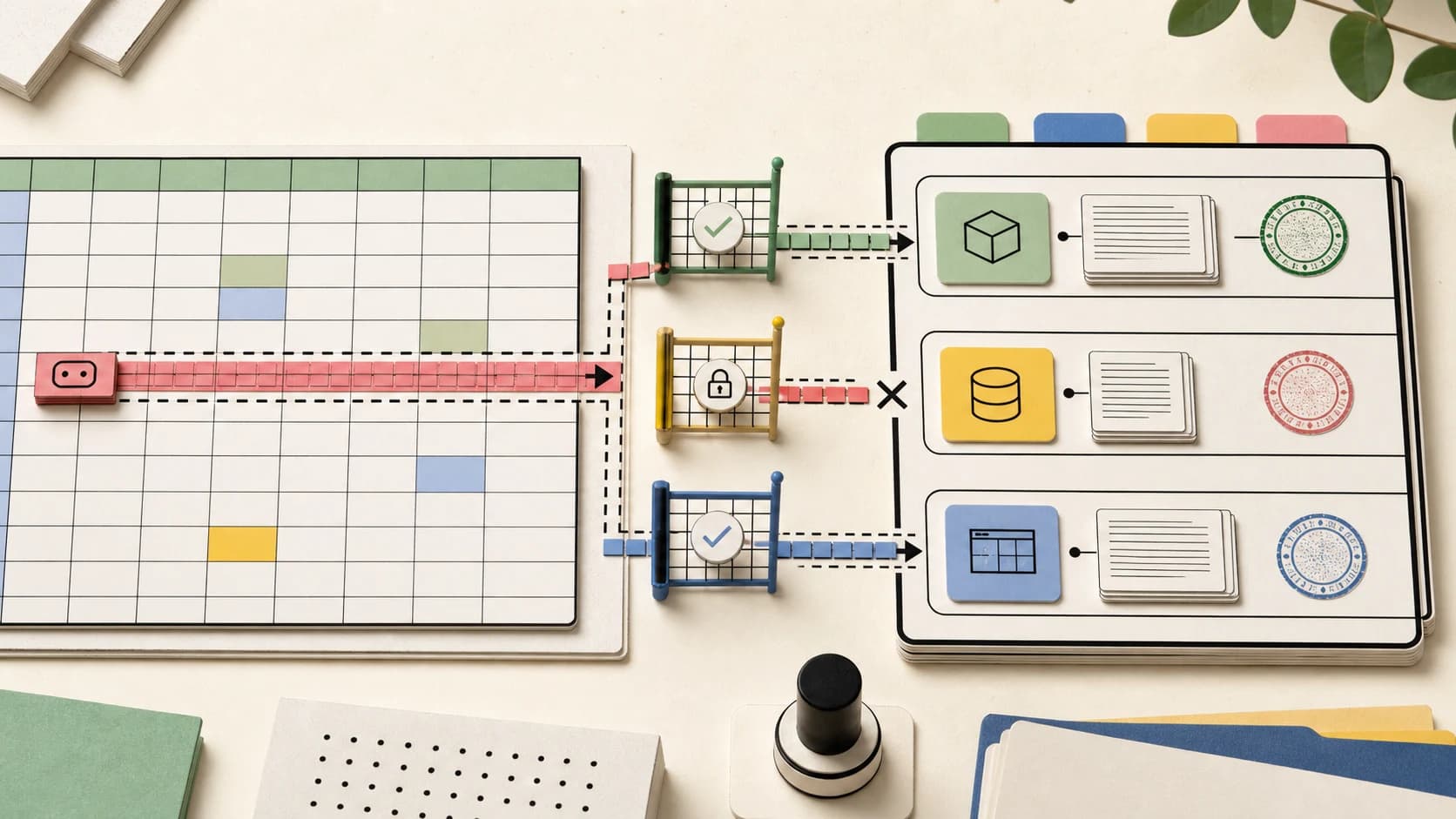
Spreadsheet Agents Need Permission Ledgers
The ChatGPT for Google Sheets exfiltration report is not just a spreadsheet bug. It is a warning about agentic office tools: permissions need to be action-scoped, logged, revocable, and visible.
8 min read

Prompt Injection in Agent Apps: The Practical Version
Prompt injection stops being an abstract LLM risk once an agent can call tools. The practical defense is data boundaries, structured handoffs, tool guardrails, and approval gates around side effects.
8 min read
Open Source Has a Bot Problem: Prompt Injection in Contributing.md
AI coding agents now read repository docs, config, issues, and comments before opening pull requests. That turns CONTRIBUTING.md and AGENTS.md into part of the security boundary.
8 min read
Keep exploring
More on Prompt Injection
- - Glossary - dive deeper across the Developers Digest knowledge base
- - All Prompt Injection articles in the blog archive
- - Developers Digest on YouTube - video tutorials covering Prompt Injection and more

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever
Explore 659 topics
Browse All Topics