Topic
AI AGENTS
Building and using AI agents - multi-agent systems, autonomous coding, and orchestration.
202 resources - 195 posts, 3 tools, 4 guides
Blog Posts
View in blog →
Agent Studio: Authoring the Roles, Not Just the Knowledge
Skills gave an agent what to know. The missing half is what role to play. Agent Studio lets you author subagents next to your skills in one place, serve both over the same MCP endpoint with the same progressive disclosure, browse them over REST and the dd CLI, and publish them to the community under a moderation loop. Here is the design and why the two belong in one studio.
9 min read

App Builder: From a Prompt to a Working App You Can Watch Run
Describe an app in plain language and get a working single-file build back with a live sandboxed preview. Revise it by talking to it, share it with a link, or download the file. Here is what single-file buys you, how revisions work, the honest limits, and what it costs.
8 min read

One Endpoint, Every Capability: A Reference Architecture for Progressive Disclosure
Skills, files, memory, and generation do not need four integrations. They need one MCP endpoint with tiered disclosure, one API key that scopes everything to its owner, and one credit balance. The same tools answer to an MCP client, an in-product chat, and a CLI. Here is the whole architecture, and why it is the shape that makes a fleet of agents coherent.
10 min read

Best AI Agent Memory Providers in 2026: Mem0 vs Zep vs Letta vs Cloudflare
A fair, sourced comparison of the memory layers developers reach for in 2026: Mem0's extract-and-retrieve, Zep's temporal knowledge graph, Letta's self-editing agent memory, and Cloudflare's Durable Objects primitive. Architecture, pricing, the benchmark disputes, and which to pick for your agent.
11 min read

MCP Servers vs Agent Skills: Which to Build in 2026
A decision framework for 2026: MCP servers give an agent access to a live system, Agent Skills teach it how to do a task. Here is when to build each, when to build both, and the criteria that actually decide it, grounded in the MCP spec and Anthropic's skills docs.
10 min read

Non-Developers Using AI Agents Need Platform Engineering
OpenAI's workplace agent data points to a practical shift: non-developers are starting to use agents for real work, so engineering teams need paved paths, policy, and receipts.
7 min read

Linked Context: When a Skill Can Point at the Whole Web
The first version of skills-over-MCP served a fixed first-party catalog. Skill Studio extends it two ways: anyone can author skills that ride the same progressive-disclosure endpoint scoped to their own API key, and a skill file can be a link instead of a copy - a URL whose bytes are only fetched at the moment an agent decides it needs them. Progressive disclosure stops at the skill boundary no longer. It runs out to the open web.
10 min read

The Economics of Agent Fleets: Fable 5 Orchestrators, Sonnet 5 Workers
One expensive orchestrator plus many cheap workers beats an all-frontier fleet for most workloads. Here is the decision-intent cost math with verified Fable 5, Sonnet 5, and Opus 4.8 prices, plus the Sonnet 5 tokenizer caveat that changes worker cost.
8 min read

Where Should Your AI Agent Run Code: E2B vs Daytona vs Modal vs Cloudflare vs Vercel Sandbox
A builder's guide to picking a code-execution sandbox for AI agents - E2B, Daytona, Modal, Cloudflare Sandbox, and Vercel Sandbox compared on isolation, latency, state, and pricing model.
7 min read

Cloudflare's x402 Monetization Gateway Brings Micropayments to the Edge
Cloudflare announces native support for the x402 HTTP payment protocol, letting developers charge for API calls and web resources with stablecoin micropayments - no accounts or API keys required.
6 min read

Coordinating an Agent Fleet for a Day: The Operating Model That Actually Held
We rebuilt and replatformed this site in a day by running a fleet of AI agents in parallel. Here is the honest operating model - the ownership rules, the verification gate on every handoff, and the failure modes we hit, with the guardrail each one produced.
10 min read

We Redesigned Developers Digest: The Applied Story of Rebuilding a 1000-Page Site in a Day
We retired the playful cream-and-pill design system for a hard-edged neutral, Vercel-inspired contract, and rebuilt the whole site in a day by coordinating parallel AI agents. Here is the design direction, the constraints we picked, how it was built, and what is next.
8 min read
Orchestrating a Fleet of Agents with Fable 5
Fable 5 changes multi-agent orchestration because the orchestrator can now hold the whole project in one head. Here is the manager-model pattern: a 1M-context frontier model leading, delegating scoped work to cheaper workers, and verifying results.
8 min read
Running Fable 5 Agent Fleets in Production: The Operations Guide
Standing up a fleet of Fable 5 agents is the easy part. This is the operations layer - data retention rules, refusal-rate alerting, effort tuning, observability, and availability planning - that keeps the fleet running.
8 min read
Running Fable 5 Agents on Vercel's eve Framework
Vercel's eve gives you the agent plumbing - durable sessions, sandboxed code execution, approvals, subagents - as a folder of files. Fable 5 gives you a long-horizon reasoning model. Here is how to wire them together, what it costs, and who the stack fits.
9 min read
Fable 5 vs Opus 4.8: Which Should Orchestrate Your Agents?
The orchestrator is the most important model choice in an agent fleet. A fair head-to-head between Fable 5 and Opus 4.8 for that role, with a decision matrix by run length, budget, compliance, and refusal-handling tolerance.
8 min read
Refusals at Fleet Scale: Building Fable 5 Agents That Do Not Silently Fail
Fable 5 refusals come back as a 200 response, not an error. At fleet scale, that quietly corrupts entire runs. Here is how to detect, fall back, and treat refusal rate as a health metric.
9 min read
Long-Horizon Agents: What Fable 5's 1M Context and Memory Actually Unlock
1M context, 128K output, a memory tool, compaction, and task budgets change what a single agent run can cover. Here is what is verified, what is plausible, and six projects builders can try now.
9 min read

Loop Engineering in 9 Minutes: Stop Prompting, Start Building Loops
A companion guide to the Loop Engineering video: the shift from repeatedly prompting an LLM to building long-running loops, goals, and automations. Here is the core idea and where to go deeper.
6 min read

The MCP 2026-07-28 Rewrite: What Breaks and How to Migrate
The 2026-07-28 Model Context Protocol spec is the largest revision since launch: a stateless core, deprecated Roots/Sampling/Logging, MCP Apps, Tasks, and tougher OAuth. Here is what breaks, what to adopt, and a migration checklist for server authors and client integrators before the July 28 deadline.
11 min read
Point Your Agent at Developers Digest
developersdigest.tech now speaks MCP. Any MCP-capable harness can call the site's tools directly - generate media, pull vetted skills and agents on demand, persist memory across sessions, search the content, and count tokens. Here is what shipped and how to connect.
7 min read

Skills Delivered Over MCP: Why Progressive Disclosure Is the Missing Piece of Both Standards
SKILL.md solved knowledge packaging with progressive disclosure. MCP solved capability transport but ships flat, context-hungry tool lists. The next shape combines them - an MCP server whose tools are a skill directory, so an agent pays context only for what the task needs. Here is the argument and a working implementation.
9 min read

LangSmith Fleet Turns Agent Ops Into On-Call Work
LangChain's June LangSmith updates point to a practical agent-ops pattern: Fleet templates, on-call triage, computer use, Slack interrupts, MCP auth, traces, and eval progress all belong in one operator loop.
8 min read

OpenAI's June API Updates Are Really a Control-Plane Upgrade
OpenAI's June 2026 API changelog looks like scattered platform plumbing. Read together, moderation scores, workload identity, Admin APIs, prompt-cache retention, container billing, and Secure MCP Tunnel are the pieces teams need to run agents with real controls.
8 min read

Vercel AI SDK 7: The Production Agent Upgrade
AI SDK 7 turns Vercel's TypeScript AI layer into a more serious agent runtime: typed tool context, WorkflowAgent durability, approvals, telemetry, realtime voice, and a cleaner migration path from AI SDK 6.
9 min read

Arcade AI Agent Authorization: A Developer Guide
Arcade just raised $60M to become the secure action layer for production AI agents. Here is what their MCP runtime actually does, how it differs from rolling your own OAuth, and when to use it.
7 min read

Agent Identity Is the Missing Security Layer for AI Workflows
The Linux Foundation's Agent Name Service proposal points at a real gap in AI agent infrastructure: agents need verifiable identity, scoped capabilities, revocation, and audit trails before they can safely act across tools.
7 min read

Agent PR Governance: The New Rules for Copilot Reviews
GitHub's June Copilot review updates point to a practical policy stack for agent-authored pull requests: validation, review depth, repo instructions, attribution, and release-note accountability.
8 min read

Agent Sandbox Architecture: How to Choose the Right Runtime Boundary
AI agents are getting their own computers. Here is how to choose a sandbox architecture: filesystem isolation, network policy, secrets boundaries, snapshots, and when shell access is overkill.
8 min read

Agent Workflows as Code: Why State Machines Beat Prompt Checklists
Aharness, LangChain's custom harness pattern, and OpenAI's code-first migration all point to the same next step: agent processes need typed gates, validated evidence, and controlled transitions.
8 min read

AI's Affordability Crisis Is Really an Agent Cost Accounting Problem
A viral Hacker News thread about AI affordability points at the right problem, but developer teams need a more useful cost model: retries, cache misses, review time, routing, and failed loops.
8 min read

Armin Ronacher on The Coming Loop and Why Agent-Driven Code Still Needs Human Comprehension
Armin Ronacher's new essay explores the tension between letting AI agents loop autonomously and maintaining the engineering comprehension that makes software maintainable. The Hacker News discussion adds practical caveats worth reading.
9 min read

Claude Outages Are a Workflow Design Problem
Claude outages and 529 overloads expose whether your AI coding workflow has checkpoints, receipts, model-switch paths, and small enough task slices to survive provider degradation.
7 min read

Anthropic Claude Tag Turns Slack Into a Shared Agent Workspace
Claude Tag is Anthropic's new Slack-based beta for Team and Enterprise users. The important shift is not chat convenience - it is shared agent identity, channel context, and team-visible work.
8 min read

Codex-Maxxing: How to Run Long-Running Codex Workflows Without Losing the Plot
Codex-Maxxing should mean bounded autonomy: AGENTS.md, small worktrees, explicit stop conditions, subagents only when work is separable, and review checkpoints that keep humans in control.
8 min read

Cybersecurity Skills for AI Agents Are Becoming Runtime Infrastructure
A GitHub-trending library of Anthropic cybersecurity skills points at the next agent security layer: framework-mapped playbooks that need provenance, tests, and abuse boundaries before they become trusted runtime tools.
8 min read

F3 Is a Reminder That File Formats Are Becoming Runtime Contracts
F3 is trending on Hacker News as a research prototype for a future-proof columnar file format. The useful takeaway is not to replace Parquet tomorrow. It is that data files are starting to carry more of their own runtime contract.
7 min read

GitHub Copilot CLI, BYOK, and AI Credits: The New Cost-Control Stack
GitHub's June Copilot updates point beyond autocomplete: CLI access, bring-your-own-key model routing, AI credit metrics, and external agent providers make Copilot a governed agent platform.
8 min read

LangChain Rubrics Make Agent Evals Part of the Runtime
LangChain's rubrics for Deep Agents point at a practical agent pattern: self-correction works only when rubrics are versioned, executable, and sampled against human review.
8 min read
Mistral OCR 4 and Unlimited OCR Make Document Parsing an Agent Runtime Choice
Mistral OCR 4 and Baidu's Unlimited OCR both hit Hacker News today. The useful takeaway for developers is that OCR is no longer just text extraction. It is becoming a runtime decision for document agents.
8 min read
OpenAI Agent Builder and Evals Are Shutting Down: Move the Agent Stack Into Code
OpenAI's June deprecations put Agent Builder, hosted Evals, and reusable prompts on a November 30 shutdown path. Here is the practical migration plan: Agents SDK, repo-owned prompts, and eval receipts.
8 min read

OpenAI Daybreak Shows the AppSec Bottleneck Is Patching, Not Finding
OpenAI's Daybreak and Patch the Planet point at the real agentic AppSec shift: security agents only matter when they produce validated, reviewable patches maintainers can actually merge.
8 min read

OpenMontage Shows the Real Future of AI Video: Agents, Not Editors
OpenMontage is trending because it treats video production like a repo-shaped agent workflow: scripts, assets, render pipelines, review loops, and coding agents working across the whole process.
7 min read

Prompt Injection Is Really Role Confusion
New role-confusion research explains why prompt injection keeps surviving better prompts. Models do not reliably perceive which text is instruction, tool output, user content, or their own reasoning.
8 min read

TikZ Editor Is a WYSIWYG LaTeX Figure Tool Built Almost Entirely by Codex
A developer used OpenAI Codex to build a fully open-source WYSIWYG editor for TikZ figures. The technical approach and reception on Hacker News offer a useful case study in what agent-built software looks like when shipped.
7 min read

Microsoft Agent Framework Developer Guide: AutoGen + Semantic Kernel Unified
Microsoft merged AutoGen and Semantic Kernel into a single production-ready SDK. Here is everything developers need to know: architecture, installation, migration paths, pricing, and when to use it over LangGraph or CrewAI.
9 min read

Oak: A New Version Control System Built for AI Agents
Oak rethinks version control for agentic workflows with virtual mounts, faster snapshots, and lower VCS-related token overhead. Here's what the HN community thinks about this Show HN.
8 min read

Fugu Ultra's Frontier Performance Claim, Explained Without the Hype
Sakana says Fugu Ultra stands with Fable, Mythos, GPT-5.5, Gemini, and Opus by orchestrating models instead of being one giant model. Here is what the benchmarks show, what is novel, and what still needs proof.
11 min read

Sakana Fugu Ultra: The Model Router Making the Frontier Look Less Proprietary
Sakana Fugu Ultra is not just another giant model. It is a learned orchestration layer that routes work across expert models, matches frontier benchmark claims, and makes a serious case for multi-model AI systems.
10 min read

Agentic AI Reliability Is a Systems Problem
The Bayer and Thoughtworks PRINCE case study is a useful reminder that reliable agentic AI comes from context routing, traces, evals, monitoring, and human review, not from a better prompt alone.
7 min read

AI Coding Agents Move the Bottleneck to Review Queues
As coding agents get easier to delegate to, the scarce resource shifts from code generation to review capacity, CI minutes, environment reliability, and merge discipline.
8 min read

Agent Evals Need Baseline Receipts
Hex's data-agent lab shows the practical eval pattern AI teams should copy: compare candidates against stable baselines, keep receipts, and judge changes by task behavior.
8 min read
Cloudflare Temporary Accounts: Let Agents Deploy Without OAuth Flows
Cloudflare shipped wrangler deploy --temporary on June 19, 2026. AI agents can now deploy Workers, D1 databases, and KV stores without browser auth flows. Here is how it works.
6 min read

The Definitive Guide to Loop Engineering in Claude Code and Codex
Goal, loop, routine. Three verbs, two tools, one hard part. A complete field guide to running agentic loops in Claude Code and Codex, the real commands, the patterns people actually run, and the two failure modes that burn money.
16 min read

MCP Goes Stateless: The 2026-07-28 Migration Guide
The MCP 2026-07-28 release candidate drops sessions entirely. Here is what changes, what breaks, and how to migrate your MCP servers before the July 28 deadline.
8 min read

Zero-Touch OAuth Is the MCP Feature Enterprises Were Waiting For
MCP's new enterprise-managed authorization flow is not just less login friction. It moves agent tool access into identity, policy, and audit systems enterprises already understand.
8 min read
Zero-Touch OAuth for MCP: Enterprise Auth Gets Practical
MCP's new Enterprise-Managed Authorization removes per-user OAuth friction. Anthropic, Okta, Figma, and Linear ship centralized auth for AI agent tooling.
7 min read
AI Model Routing: Why the Orchestration Layer Is the Next Big Play Next to the Labs
A $500M accidental Claude bill and an open-weights model beating GPT-5.5 at one-sixth the cost point to the same conclusion: the margin is moving to the layer that decides when to use which model for what. Here is how routing and orchestration differ, and how to cut your model spend.
12 min read
Build Your First Agent with Vercel eve: A Step-by-Step Tutorial
A hands-on, beginner-friendly walkthrough of building an AI agent with Vercel eve: scaffold the project, define an agent and a typed tool with defineTool, run it locally, call it through the durable session and stream API, and deploy to Vercel Functions.
10 min read
Claude Code Permissions: A Practical settings.json Guide for Allow, Deny, and Ask Rules
Stop the approval-fatigue prompts without going full YOLO mode. A hands-on guide to Claude Code's permission system - settings.json scopes, allow/deny/ask rules, tool specifiers, and the headless flags that actually matter.
11 min read
The $500M Claude Bill: A Spend-Guardrails Playbook for AI-Native Teams
A company accidentally spent $500M on Claude in one month. Uber torched its whole 2026 AI budget by April. The fix is not less AI - it is guardrails. Here is the playbook: caps, alerts, gateway spend limits, model routing, prompt caching, and approval workflows.
11 min read
Cursor Origin: A Git Forge Built for AI Agents, Not Humans
At its Compile conference, Cursor announced Origin: a Git-compatible code hosting platform designed around AI agents as first-class users. Built on its Graphite acquisition, it promises agent-driven merge conflict resolution, stacked PRs, and MCP-extensible automation. Here is what was actually announced, what is still a waitlist promise, and why it matters for developers.
8 min read
Everything Vercel Shipped at Ship 26 (June 2026)
At Vercel Ship 26 in London on June 17, 2026, Vercel shipped a wave of agent-era tooling: the open-source eve agent framework, Vercel Drop for drag-and-drop deploys with no Git or CLI, spend caps for AI Gateway API keys, and the HarnessAgent API in AI SDK 7 that unifies Claude Code, Codex, and Pi behind one interface.
8 min read
GitHub Copilot SDK Hits GA: Embed the Copilot Agent Runtime in Your Own Apps
On June 2, 2026, GitHub made the Copilot SDK generally available. It exposes the same agent runtime behind Copilot - planning, tool calls, file edits, streaming, MCP - across TypeScript, Python, Go, .NET, Rust, and Java. Here is what changed at GA and what it means for builders.
8 min read

Mastra npm Supply Chain Attack: 140+ AI Framework Packages Backdoored
On June 17, 2026, attackers hijacked a dormant Mastra contributor account and pushed malicious versions of 140+ packages. The payload steals crypto wallets, browser data, and cloud credentials. Here is what happened, how to check your lockfile, and what to do if you installed an affected version.
7 min read
Microsoft's Work IQ APIs Hit GA: What Agent Builders Actually Get on June 16
On June 16, 2026, Microsoft's Work IQ APIs reach general availability - a workplace intelligence layer that hands agents pre-assembled, permission-trimmed Microsoft 365 context instead of raw Graph calls. Here is what the four domains, three protocols, and consumption pricing mean for developers building enterprise agents.
7 min read

Omnigent: Databricks' Meta-Harness for Orchestrating Claude Code, Codex, and Custom Agents
Databricks open-sourced Omnigent, a meta-harness that sits above individual agent CLIs so your sessions, policies, and skills are not locked inside any single tool. Here is what it does, how to install it, and where it fits if you already run Claude Code and Codex.
8 min read

Codex Gets Computer Use in the EU - and a Clean Claude Code Import
OpenAI's mid-June 2026 Codex drop brings Computer Use to the EEA, UK, and Switzerland and adds selective Claude Code imports plus managed Bedrock auth to the CLI. Here is what actually shipped, verified against the changelog.
7 min read

'The Orchestration Is the Product': What Perplexity's Aravind Srinivas Sees That the Model Labs Don't
Perplexity launched a $200-a-month agent that coordinates 19 models and calls orchestration, not the model, the product. Here is the strategic case for why the durable, defensible layer in AI sits next to the labs, not inside them - and what 'token value per watt per user' actually means for builders.
11 min read

Vercel eve: The Framework for Building AI Agents
Vercel launched eve at Ship 26, an open-source agent framework it calls Next.js for agents. You define each agent as files under an agent/ directory, and eve compiles it into a production app on Vercel Functions with durable execution, sandboxes, approvals, subagents, and evals built in.
9 min read

Agent Workspaces Need Filesystem Contracts
GitHub's latest agent workspace trend points at a boring but important primitive: agents need explicit filesystem contracts before they get more tools.
8 min read

AI Infrastructure Agents Need Spend Guardrails
The viral DN42 AWS bill story is funny until you realize the missing primitive: infrastructure agents need hard cloud-spend guardrails before they touch real accounts.
8 min read
WebMCP: Google's Browser Standard That Lets AI Agents Use Websites as Tools
Chrome 149 ships an origin trial for WebMCP - a proposed web standard that lets developers expose JavaScript functions and HTML forms to AI agents. Here is what it does, how to implement it, and why it matters for the future of agentic browsing.
8 min read
Claude Agent SDK vs Claude Code: When to Build and When to Drive
Claude Agent SDK vs Claude Code explained: same engine, two surfaces. Here is the concrete decision line, plus where Managed Agents fits as the hosted third option.
8 min read
Claude Agent SDK vs LangGraph: Choosing Your Agent Stack in 2026
Claude Agent SDK vs LangGraph head-to-head: architecture, state handling, multi-agent patterns, and real pricing - plus a decision guide for which agent stack fits your team in 2026.
9 min read
Claude Agents vs Skills: Which One Do You Actually Need?
Claude agents vs skills, untangled: agents are workers with their own context window, skills are instructions loaded on demand. Here is the decision table.
8 min read
Claude Code Auto Mode Explained: Permissions Without the Prompts
Auto mode replaces permission prompts with a background safety classifier - here is how the Shift+Tab cycle, hard_deny rules, and glob deny patterns actually fit together.
8 min read
Claude Code Dynamic Workflows: The Complete Guide
Claude Code dynamic workflows turn orchestration into a JavaScript script that runs up to 1,000 agents per run - here is how scripts, schemas, budgets, and resume actually work.
10 min read
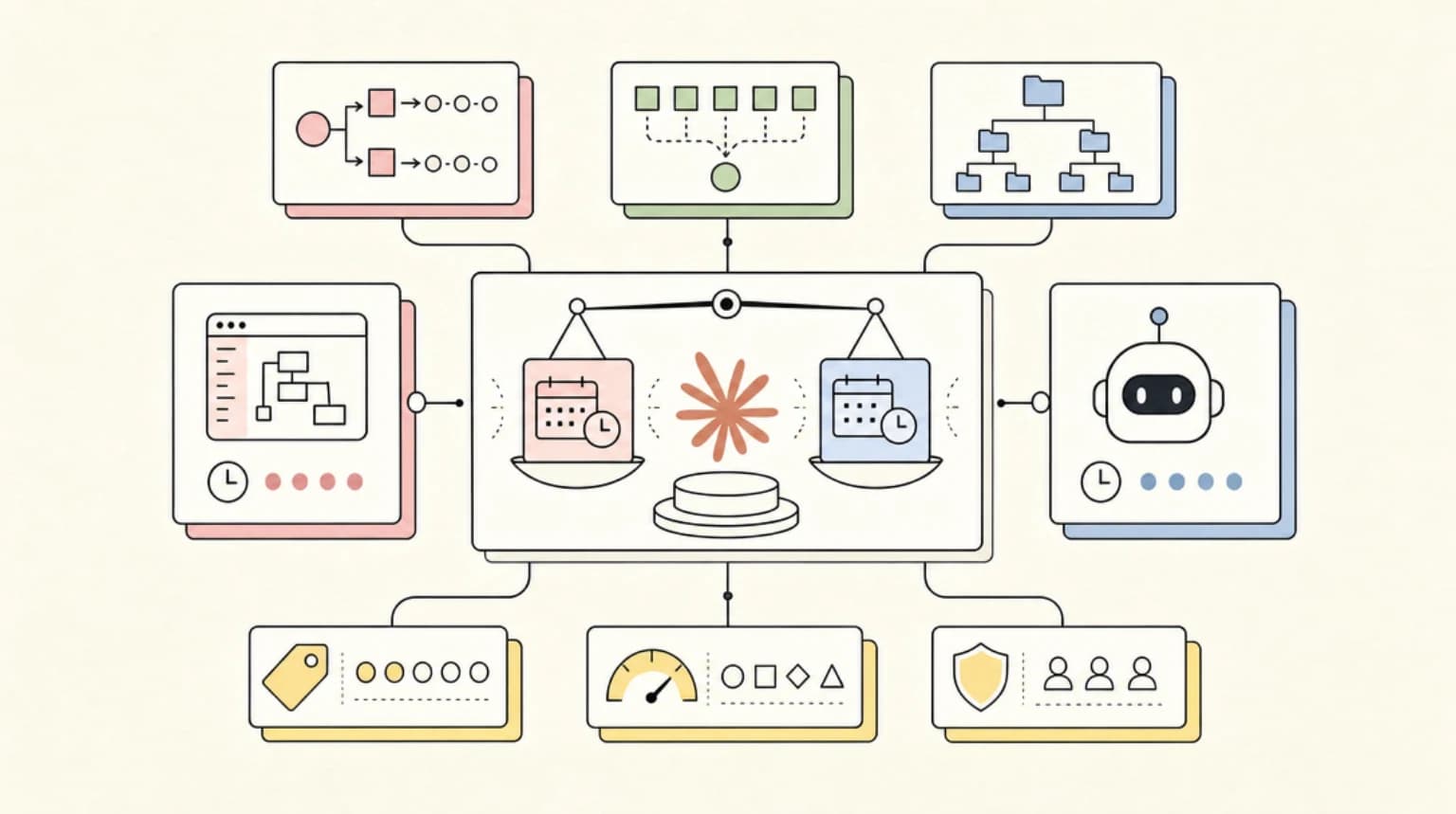
Claude Code Routines vs Managed Agents Schedules: Where Recurring Agent Work Should Live
Claude Code Routines and Managed Agents scheduled deployments both run Claude on a schedule - here is how the triggers, pricing, and limits differ, and which one fits your recurring agent work.
9 min read
Subagents vs Agent Teams vs Workflows: Claude Code's Parallelism Primitives, Compared
Claude Code subagents vs agent teams vs workflows: who holds the plan, the hard limits (16 concurrent, 1,000 agents per run), and which primitive fits your task.
9 min read
Setting Up the Memory Tool with Fable 5: Persistent Agents That Learn
Anthropic says persistent file-based memory improved Fable 5 three times more than it improved Opus 4.8. Here is the full memory tool setup - handlers, security, and context editing included.
8 min read
The Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap Workers
A practical playbook for running Claude Fable 5 as the orchestrator over Sonnet and Haiku workers, with verified cost math on when the premium pays off.
10 min read
Fable 5 Task Budgets: Capping Agent Spend Before It Happens
Task budgets give Claude a token countdown for the whole agentic loop, so the model paces itself instead of discovering the limit when max_tokens truncates it. Here is how the beta works on Fable 5, what it does not enforce, and where it fits next to effort and the Usage API.
8 min read
Managing a Fleet of Claude Agents: A Practical Guide
An ops guide to managing a fleet of Claude agents: spawning patterns, worktree isolation, build gates, orphaned-agent failure modes, and OpenTelemetry monitoring.
10 min read

Recursive Self-Improvement: What Fable 5, Dario's Essay, and Anthropic's Own Data Actually Tell Us
In one 48-hour window Anthropic shipped Fable 5, Dario Amodei called for FAA-style model testing, and the Anthropic Institute published internal data on AI building AI. Here is what recursive self-improvement actually means, and how far along the loop really is.
10 min
Rewriting Your Prompts and Skills for Fable 5
Rewriting prompts and skills for Fable 5: what changes when you migrate agents from Opus 4.x, how effort interplay works, and which old workarounds now hurt.
10 min read
Ultracode: Claude Code Multi-Agent Orchestration Mode Explained
Ultracode is two documented things: a prompt keyword that turns one task into a dynamic workflow, and an /effort setting that pairs xhigh reasoning with automatic orchestration. Here is exactly what the docs say.
8 min read
12 Ways Developers Are Actually Leveraging Claude Fable 5
Twelve documented Claude Fable 5 use patterns - agent orchestration, overnight runs, 1M-context refactors, effort tuning - each with a how-to seed and doc link.
10 min read
What a Fleet of Claude Agents Actually Costs (June 2026 Math)
Claude Code parallel agents cost real money because every session draws from one quota - here is the June 2026 budgeting math, verified against live pricing.
10 min read

The One-Cent Attack: Prompt Injection Through Bank Transfer Memos
Security researchers showed a €0.02 bank transfer could compromise a banking AI assistant. Here is the exact attack chain - and what every developer building agents needs to do differently.
8 min read
Apache Burr vs LangGraph vs CrewAI: Choosing an AI Agent Framework in 2026
Apache Burr hit the front page of Hacker News with 142 points today. Here is what it actually does, how it compares to LangGraph and CrewAI, and when you should skip frameworks entirely.
9 min read
Claude Managed Agents Public Beta: What's Actually Available vs What's Gated
Claude Managed Agents is in public beta with solid sandboxing and session persistence - but the headline orchestration features are still locked behind a research preview waitlist. Here's what teams can actually ship today, what it costs, and when DIY alternatives make more sense.
8 min read
Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
Fable 5 posts an 80.3% SWE-Bench Pro score and costs 2x Opus 4.8 - here is the task-profile scoring guide that tells you when the premium pays off.
7 min read
Managed Agents vs LangGraph vs Rolling Your Own: Who Should Run Your Agent Loop in 2026
The 2026 agent decision is not CrewAI vs LangGraph. It is whether your loop lives in vendor infrastructure, a self-hosted graph runtime, or a plain while-loop you wrote yourself. Here is how to choose.
9 min read
Mastra: Review and Setup Guide for TypeScript Agent Apps (2026)
A hands-on look at Mastra, the open source TypeScript framework for building production-ready AI agents and workflows -- with verified setup commands, honest tradeoffs, and current pricing.
8 min read
Mastra vs LangGraph.js: TypeScript Agent Frameworks Head to Head
Both Mastra and LangGraph.js are serious TypeScript agent frameworks - but they start from opposite philosophies. Here is what that means for your next project.
8 min read
OpenAI Agents SDK vs Claude Agent SDK: Building Agents on the Two Big Platforms
A practical comparison of OpenAI's Agents SDK and Anthropic's Claude Agent SDK - orchestration models, tool ecosystems, sandboxing, and how to choose the right platform for your team.
9 min read

The TypeScript AI Agent Stack in Mid-2026: Mastra vs Vercel AI SDK vs OpenAI Agents SDK vs LangGraph.js
Four mature, production-ready TypeScript frameworks have made building agents genuinely enjoyable. Here is how to pick the right one - and how they fit together.
10 min read
Vercel AI SDK 6 vs LangGraph 1.0: Which Agent Framework Should TypeScript Teams Use?
AI SDK 6 ships ToolLoopAgent and full MCP support. LangGraph hits 1.0 GA with durable state and built-in interrupt/resume. Here is how to choose between them for your TypeScript team.
8 min read
Goose: The Open Source AI Agent With 70+ MCP Extensions
Goose is a Rust-built AI agent with a CLI, desktop app, and API that runs against 15+ LLM providers and extends through 70+ MCP extensions - here is why developers are installing it.
8 min read

Harness Engineering Makes Tokens a Systems Budget
OpenAI's harness engineering post and new token-use research point to the same lesson: agentic coding teams need token budgets, receipts, and eval loops, not vibes.
8 min read
Headroom: Compress Agent Tool Output Before It Reaches the LLM
Headroom is a context compression layer that intercepts your AI agent's tool outputs and strips 60-95% of the tokens before they hit the model - with benchmarked accuracy preserved.
8 min read

Security Agents Need Repro Harnesses, Not More Scan Prompts
Anthropic's open-source vulnerability harness shows where AI security work is going: reproducible exploit loops, separate verification agents, and patch receipts.
9 min read

AI Agent Containment Needs a Capability Ledger
Anthropic's Claude containment writeup points to the next security layer for coding agents: deterministic capability ledgers, not another approval prompt.
9 min read

AI Agent Memory Needs a Context Ledger
GitHub Trending is full of agent memory and context tools. The useful version is not magic recall. It is a context ledger: source-linked, scoped, expiring memory that agents can inspect and users can audit.
8 min read
Spreadsheet Agents Need Permission Ledgers
The ChatGPT for Google Sheets exfiltration report is not just a spreadsheet bug. It is a warning about agentic office tools: permissions need to be action-scoped, logged, revocable, and visible.
8 min read

Domain Expertise Is the New Agentic Coding Moat
A huge Hacker News thread says domain expertise is the real moat in agentic coding. The sharper version: tacit judgment only compounds when you turn it into examples, tests, DSLs, and review gates.
8 min read

The Agent Security Checklist I Use Before Connecting Tools
Before an AI agent gets tools, files, APIs, MCP servers, or deployment access, decide what it can read, write, call, log, and roll back.
8 min read

Mastra for Durable TypeScript Agents: Where It Fits and Where It Does Not
Mastra is the strongest fit when a TypeScript product needs agents, workflows, memory, tools, MCP, evals, and traces in one backend layer. It is not the right answer for every chat feature.
8 min read
Mastra vs CopilotKit vs LangGraph: Build the Same Agent App Three Ways
A practical field note on where Mastra, CopilotKit, and LangGraph fit when you are building the same agent-native product interface.
9 min read
The Model, IDE, CLI, and Agent Framework Changes That Actually Matter
The AI coding market is noisy. The changes that matter are easier to spot when you separate model capability, editor loops, terminal agents, background agents, agent frameworks, UI layers, context, security, and cost.
10 min read
The New AI Coding Stack I Would Pick Today
If I were rebuilding my AI coding workflow on May 30, 2026, I would not pick one magic tool. I would pick a layered stack: terminal agent, editor, background agent, Mastra, CopilotKit, MCP, context, security, and cost controls.
11 min read
Permissions, Logs, and Rollback for AI Coding Agents
AI coding agents become safer when permissions, logs, and rollback are designed as one system. Here is the operating loop I would put around any agent that can edit code, run tools, or open pull requests.
9 min read
Prompt Injection in Agent Apps: The Practical Version
Prompt injection stops being an abstract LLM risk once an agent can call tools. The practical defense is data boundaries, structured handoffs, tool guardrails, and approval gates around side effects.
8 min read
State of AI Coding: What Changed This Month
May 2026 was not about one more coding model leaderboard. The useful signal was control planes, UI-agent contracts, durable TypeScript workflows, usage economics, and runtime security.
10 min read
When CopilotKit Is the UI Layer, Not the Agent Framework
CopilotKit is strongest when you treat it as the product-facing agent UI layer: chat surfaces, frontend tools, shared state, generative UI, and human approval around a backend agent.
8 min read

Claude Opus 4.8 Is an Agent Honesty Release
Claude Opus 4.8 looks like a benchmark bump, but the developer story is better honesty, dynamic workflows, and effort controls that make long-running agent work easier to review.
8 min read

Local Code Graphs Are the Agent Context Layer
CodeGraph shows why coding agents need a local, queryable repo map. The win is not magic token savings. It is faster orientation, fewer wrong files, and better review receipts.
9 min read

AI Agent PMF Is a Cost Control Problem Now
AI coding agents have crossed from demo to daily workflow. The next bottleneck is not demand. It is cost attribution, budget gates, and workflow design that keeps agent fleets from turning useful work into surprise spend.
8 min read

AI Chat Fatigue Is a Workflow Design Bug
A front-page Hacker News essay about being tired of AI answers points at a real developer problem: chat is too easy to launder into fake work. The fix is verifiable workflows, not more conversational polish.
8 min read
Coding Agents Need Codebase Maps, Not Bigger Prompts
GitHub is suddenly full of codebase knowledge graph projects for Claude Code, Codex, Cursor, and other agents. The useful version is not a pretty graph. It is a map that changes planning, editing, and review.
8 min read

Claude Knowledge Work Plugins Turn Agent Setup Into Team Infrastructure
Anthropic's knowledge-work plugin repo is trending because it packages skills, connectors, slash commands, and sub-agents around job functions. The interesting shift is from personal prompts to team-distributed operating systems.
7 min read

Constraint Decay Is the Coding Agent Bug Nobody Can Prompt Around
A new arXiv paper shows coding agents can pass loose backend tasks, then fall apart when architecture, database, and ORM constraints pile up. The fix is not longer markdown. It is executable constraints.
8 min read

Reasonix Shows the Next Coding Agent Fight Is Cache Discipline
Reasonix hit Hacker News with a DeepSeek-native pitch: keep long coding sessions cheap by designing the agent loop around prefix caching. The interesting question is when cache efficiency helps quality, and when it fights the harness.
7 min read
CLI-Anything Turns Any Software Into an Agent-Ready Command Line
HKUDS/CLI-Anything hit 40,000 stars by solving a stubborn gap: most desktop software has no interface AI agents can reliably drive. Its 7-phase pipeline auto-generates a tested CLI harness from source code.
6 min read
12-Factor Agents: Production Principles for Reliable AI Agents
HumanLayer's 12-Factor Agents guide turns agent reliability into an engineering checklist: own prompts, context, tools, control flow, state, human approval, and observability before a demo becomes production.
8 min read

AI Security Scanners Move the Bottleneck to Triage
Anthropic's Project Glasswing update is a useful signal for developer teams: AI can find vulnerability candidates faster than humans can verify, disclose, patch, and ship them.
8 min read
Multi-Stream LLMs Hint at the Next Agent Architecture
The Multi-Stream LLMs paper argues that agents are bottlenecked by single chat streams. The practical takeaway is not to rebuild everything today, but to design agent runtimes around separated channels.
8 min read

Sandboxed Agents Are Becoming the Team Control Plane
Runtime's Launch HN thread is a useful signal: teams do not just want isolated coding agents. They want a control plane for approvals, secrets, telemetry, review, and merge policy.
8 min read
Forge Shows the Local Agent Reliability Gap Is a Harness Problem
Forge hit the Hacker News front page with a strong claim: small local models can become much more useful at tool-calling when the harness catches structural failures, retries intelligently, and controls context.
7 min read

Anthropic Buying Stainless Is About Agent Plumbing
Anthropic's Stainless acquisition is not just an SDK deal. It is a bet that agents need generated SDKs, CLIs, docs, and MCP servers from the same source of truth.
8 min read

AgentMemory Is Useful Only If You Audit What It Remembers
AgentMemory gives Claude Code, Codex, Cursor, and other agents persistent local memory. The real adoption question is not recall accuracy. It is whether your team can inspect, prune, and govern what gets remembered.
8 min read

Agent Memory Benchmarks Are Not Enough
Persistent memory for coding agents is trending because every session still starts too cold. The hard part is not saving facts. It is proving recall, freshness, deletion, and rollback under real development pressure.
9 min read

Claude Platform on AWS Is Enterprise Agent Plumbing, Not Just Procurement
Claude Platform on AWS matters because it moves agent adoption into identity, billing, commitments, and platform controls. That is where enterprise AI work gets real.
8 min read

Interaction Models Are the Next AI Developer Tool Interface
Thinking Machines' interaction-models post points at a useful shift for developer tools: stop designing around single chat turns and start designing around shared work.
8 min read

TanStack's npm Compromise Is the CI Lesson Agent Teams Needed
The TanStack npm incident was not just a package-security story. It was a reminder that AI agent workflows inherit every weak trust boundary in CI.
9 min read

Ruflo Is an Agent Meta-Harness. Treat the Star Count as a Warning Label.
Ruflo turns Claude Code and Codex into a larger agent harness with plugins, memory, swarms, MCP tools, and federation. The useful question is not the star count. It is how much harness you actually need.
8 min read

Claude Managed Agents Are Starting to Look Like Backend Jobs
Claude Managed Agents now have multiagent sessions, outcomes, webhooks, and vault events. The practical takeaway is not just better agents. It is that agent runs need backend job discipline.
9 min read
DeepSeek-TUI: The Rust Terminal Coding Agent With MCP, Skills, and 1M-Token Context
DeepSeek-TUI is a Rust-built terminal coding agent wrapping the DeepSeek V4 API with full tool use, MCP server support, a composable skills system, and three operational modes for different risk tolerances.
6 min read

How We Patched 100+ PRs Across Our App Empire in One Day
31 deployed apps. 7 down. Favicons missing on 20 of 24 reachable hosts. Sentry on zero. Here is how a single audit turned into 58 PRs in one afternoon - and what shipped, what didn't, and what the pattern was.
6 min read
219 PRs in One Day: A Parallel Agent Fan-Out Postmortem
Notes from a single session running 200+ Claude Code subagents in parallel across 35 repos. What worked, what broke, and the patterns I codified into a skill so the recipe replays.
8 min read

Codex Automations: Where Scheduled AI Agents Actually Help
Codex automations are useful when recurring engineering work has clear inputs, reviewable outputs, and safe boundaries. Here is the practical playbook.
9 min read

Codex Is Becoming a General-Purpose AI Agent, Not Just a Coding Tool
OpenAI is turning Codex from a coding assistant into a broader agent workspace for files, apps, browser QA, images, automations, and repeatable knowledge work.
8 min read

Codex Loops: What Boris Cherny Gets Right About Managing Agent Work
Boris Cherny's loop-heavy Claude Code workflow points at the next Codex content lane: recurring agents that babysit PRs, CI, deploys, and feedback streams.
8 min read

Karpathy's Loopy Era Is the Best Way to Understand Codex
Andrej Karpathy's loopy era frame explains why Codex is becoming less like a chatbot and more like an agent loop manager for real software work.
9 min read

The 98% Context Reduction Pattern
Efficient agents do not stuff every tool result into the model context. They keep intermediate state in code, files, and execution environments, then return compact summaries and receipts.
8 min read

Approval Fatigue Is an Agent Security Bug
Manual approval prompts stop protecting users when coding agents ask too often. The better pattern is risk-aware autonomy: safe defaults, narrow deny rules, and approvals only for meaningful changes.
7 min read

Claude Code Agent Teams, Subagents, and MCP: The 2026 Playbook
Claude Code is turning into an orchestration layer for agent teams. Here is how subagents, MCP, hooks, and long context fit together in 2026.
9 min read

Client-Side Tool Calling Is the Privacy Pattern AI Apps Need
A Show HN PDF form demo points at a bigger architecture shift: keep sensitive documents local, expose narrow browser tools to the model, and make AI assistance inspectable.
7 min read

Codex /goal and Claude Managed Outcomes: The New Control Loops
A deep comparison of Codex's new /goal loop and Claude managed agents outcomes, with practical workflow examples, control tradeoffs, and migration guidance for long-running tasks.
18 min read

Flue: The Agent Harness Framework and Why It Feels Different
A long-form technical read on Flue from Fred K Schott, with deeper comparisons against OpenAI Agents, Vercel AI SDK, Google ADK, LangChain, Deep Agents, and CrewAI, plus practical production patterns.
24 min read

Long-Running Agents Need Harnesses, Not Hope
A long-running coding agent is only useful if the environment around it can queue tasks, capture logs, checkpoint state, verify behavior, limit cost, and recover from failure.
9 min read

One Tool Beats Ten Endpoints
Most agent tool APIs are just REST endpoints with nicer names. Production agents need intent-shaped tools that compress workflows, reduce context, and return reviewable receipts.
8 min read

Skills Are How Agents Learn the Job
Skills turn a general coding agent into a trained teammate by packaging runbooks, scripts, examples, and domain-specific judgment into reusable instructions.
7 min read

Warp Open Sourced the Terminal. The Real Story Is Agent Operations
Warp going open source is not just a terminal story. It is a signal that AI coding tools are shifting from chat UX toward agent operations, where planning, execution, review, and feedback loops live close to the shell.
8 min read

12 Tools in One Night: An Honest Overnight Agent Report
I told an agent to improve the site every 10 minutes and went to sleep. Here is what 12 new repos, 60 PRs, and three goofs taught me about overnight orchestration.
11 min read

Agent Architecture: Building Multi-Step AI Workflows That Survive Production
A practical architecture for multi-step Claude agents. Loop patterns, state management, error recovery, and the production gotchas that turn a five-step demo into a 20 percent success rate at scale.
11 min read

Model Context Protocol: A Production Guide To Building MCP Servers
Build MCP servers that connect Claude to your databases, APIs, and tools. Architecture, TypeScript SDK code, debugging, and the production gaps the spec doesn't cover.
13 min read

Tool Use in the Claude API: Production Patterns for Reliable Agents
Master tool use in the Claude API. Schema design, retry logic, multi-step loops, and the failure modes that only show up at 10k calls a day.
12 min read
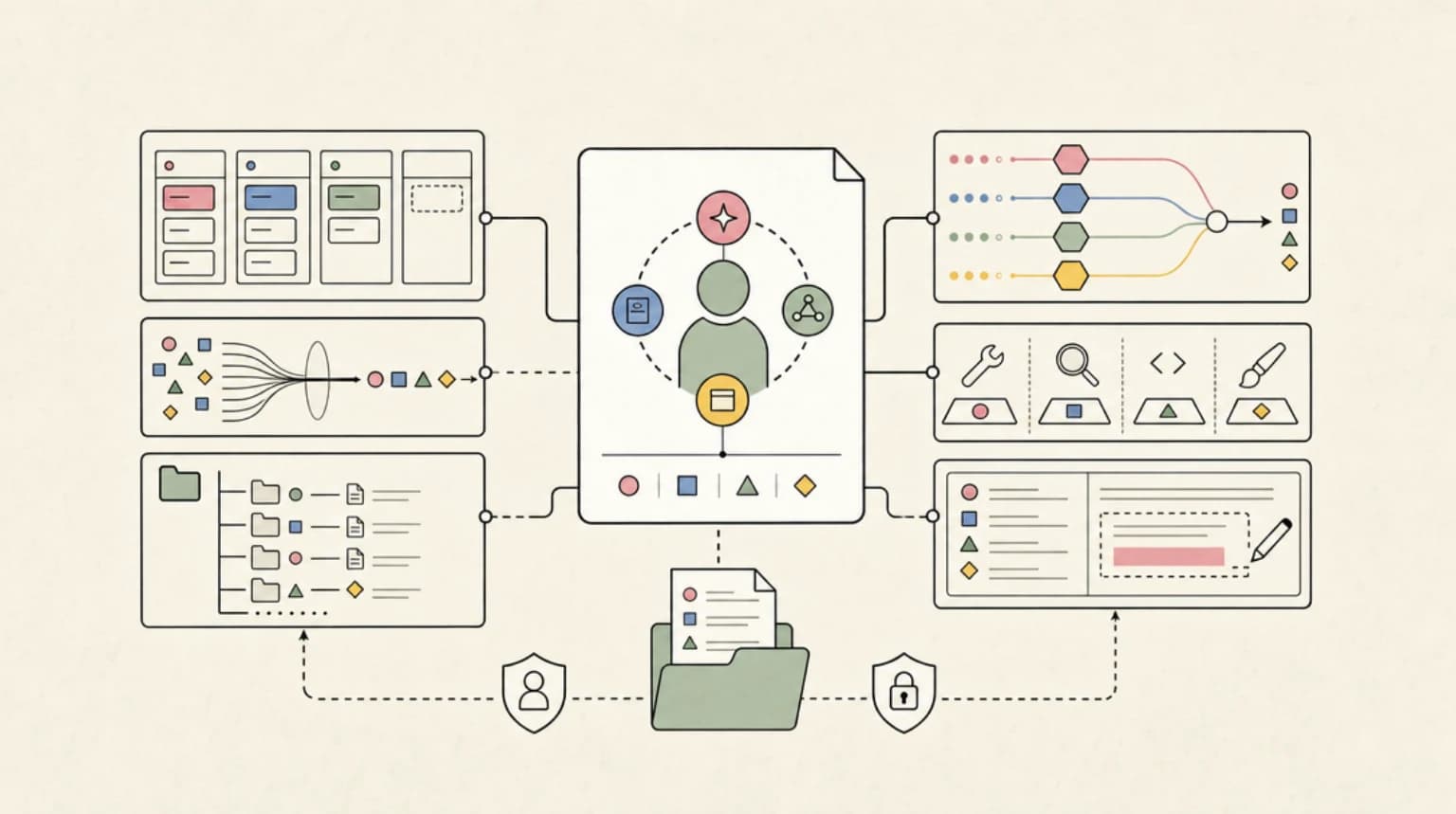
The DD Stack Cookbook: Five Recipes That Compose
Five worked examples showing how the new Developers Digest products plug into each other. Real agent filesystems, auto-snapshots, gated skill libraries, eval suites, and a recursive MCP host.
9 min read

Introducing agentfs: A Filesystem for AI Agents
agentfs is filesystem-shaped storage for AI agents. Postgres-backed on Neon, no cold starts, no exec by design. Pay-only plans start at twenty dollars.
9 min read

10 Tools We Built for Agent Infrastructure
Ten private tools shipped overnight - observability, skills, hooks, prompts, and evals - aimed at the agent infrastructure gap small teams keep falling into.
11 min read

The Agent Reliability Cliff: Why Your 10-Step Chain Only Succeeds 20% of the Time
The math of agent pipelines is brutal. 85% reliability per step compounds to about 20% at 10 steps. Here is why long chains collapse in production, and the six patterns the field has converged on to fight the decay.
9 min read

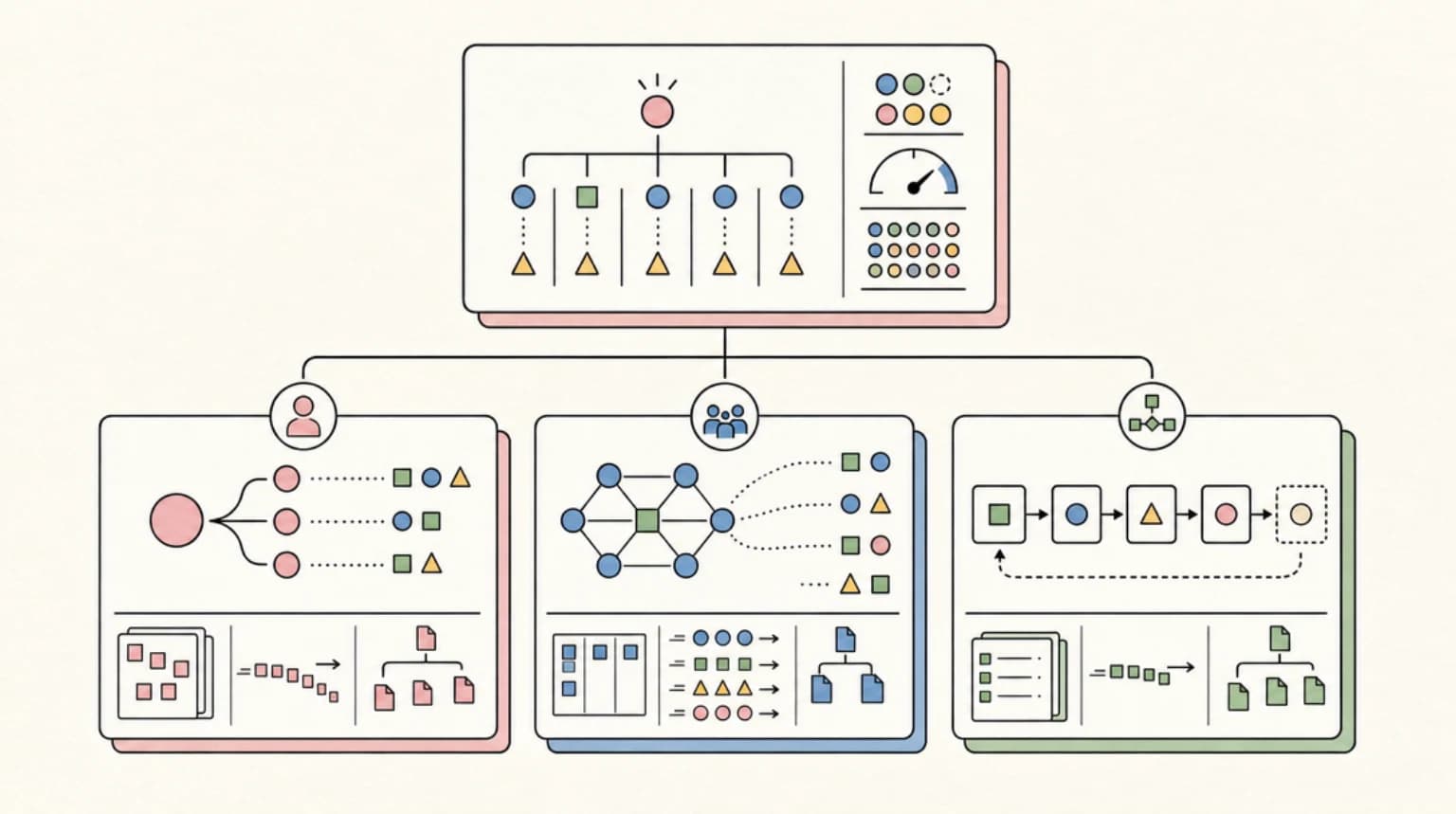
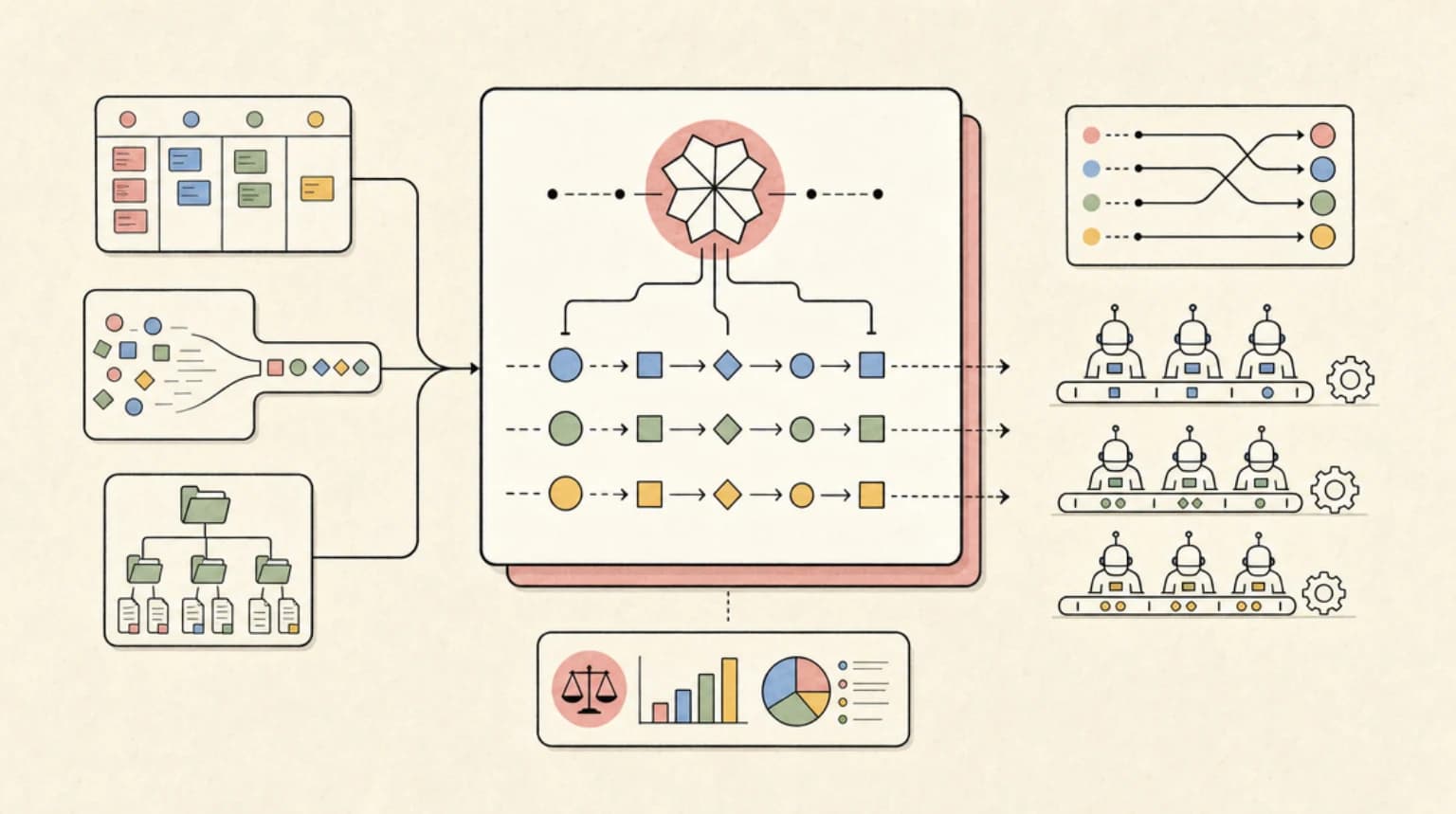
7 AI Agent Orchestration Patterns Every Developer Should Know
From single-agent baselines to multi-level hierarchies, these are the seven patterns for wiring AI agents together in production. Each with a decision rule, an implementation sketch, and the tradeoffs that actually matter.
10 min read
Multica Turns Coding Agents Into Teammates. The Hard Part Is Receipts.
Multica is pushing the agent teammate pattern: assign issues, route work to local runtimes, stream progress, and compound skills. Here is the practical read for AI dev teams.
8 min read
The $400 Overnight Bill: Why Managed Agents Need FinOps Now
Five managed-agent providers, five pricing models, zero unified cost attribution. If you're running agents overnight, you need FinOps you don't have yet.
13 min read

Claude Code vs Codex vs Cursor vs OpenCode: Which Agent Ships More Code?
Four agents, same tasks. Honest trade-offs from a developer shipping production apps with all of them.
10 min read

How to Write a CLAUDE.md: The Complete 2026 Guide
CLAUDE.md is the highest-leverage file in any Claude Code project. Here's what goes in one, what doesn't, and the patterns that actually ship.
12 min read

What Is an AI Coding Agent? The Complete 2026 Guide
Autocomplete wrote the line. Agents write the pull request. The shift from Copilot to Claude Code, Cursor Agent, and Devin - explained with links to the docs that prove every claim.
13 min read

What Is an MCP Server? A Developer's Beginner Guide (2026)
MCP is the USB-C of AI agents. What the Model Context Protocol is, why Anthropic built it, and how to install your first server in Claude Code or Cursor. Fact-checked against the official MCP spec.
13 min read
OpenAI Codex Cloud Security Playbook 2026: Internet Access, Prompt Injection, and Safe Defaults
A practical security playbook for running Codex cloud tasks safely in 2026 using OpenAI docs: internet access controls, domain allowlists, HTTP method limits, and review workflows.
10 min read

What Hacker News Gets Right About AI Coding Agents in 2026
Hacker News keeps arguing about Claude Code, Codex, skills, MCP, and orchestration. Under the noise, the same four truths keep surfacing: workflows matter more than demos, verification is the bottleneck, skills beat prompts, and orchestration matters more than raw autonomy.
11 min read

Building SaaS with AI Agents in 2026: The Complete Workflow
How to use AI agents to plan, scaffold, build, test, and deploy a SaaS product. Parallel development patterns, real workflow examples, and the operational details that determine whether your AI-assisted build succeeds or fails.
15 min read

Context Engineering: The Highest-Leverage Skill in AI-Assisted Development
Context engineering is the practice of designing the persistent information that surrounds every AI interaction. CLAUDE.md files, system prompts, skill libraries, and memory systems. It is the single highest-leverage skill for developers working with AI agents in 2026.
14 min read

How to Coordinate Multiple AI Agents: The Definitive Guide for 2026
Production-tested patterns for orchestrating AI agent teams - from fan-out parallelism to hierarchical delegation. Covers CrewAI, LangGraph, AutoGen, OpenAI Agents SDK, Google ADK, and custom approaches with real code.
14 min read

Self-Improving AI Agents: Building Systems That Learn From Their Mistakes
AI agents that reflect on failures, accumulate skills, and get better with every session. Reflection patterns, memory architectures, skill extraction, and working code examples for building agents that actually learn.
13 min read
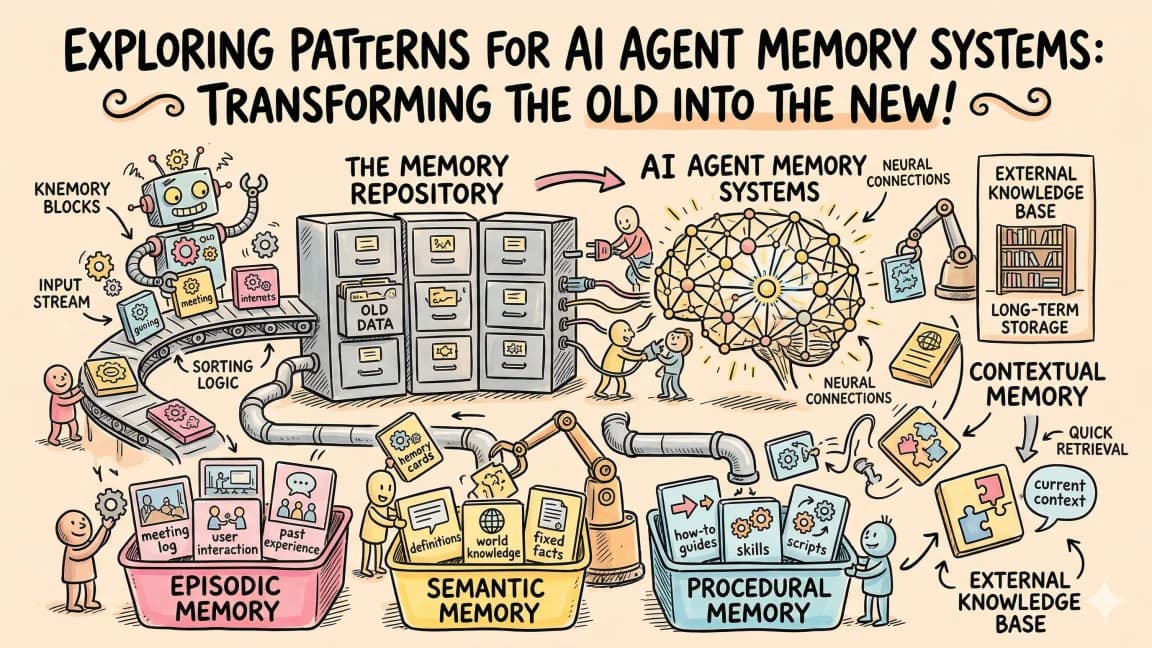
AI Agent Memory Patterns
Agents forget everything between sessions. Here are the patterns that fix that: CLAUDE.md persistence, RAG retrieval, context compression, and conversation summarization.
9 min read

How to Debug AI Agent Workflows
AI agents fail in ways traditional debugging cannot catch. Here are the tools and patterns for finding and fixing broken agent loops, tool failures, and context issues.
9 min read

AI Skills for Every Career: Agents and Knowledge Work
AI agent skills are not just for developers. Here is how 12 professions use packaged AI workflows to do better knowledge work.
12 min read

Local OpenTelemetry Traces Are Agent Receipts
AI agent work needs local observability. OpenTelemetry, OTLP, Vercel AI SDK telemetry, and lightweight trace viewers give developers receipts for model calls, tool use, latency, errors, and cost before anything goes to production.
9 min read

How to Build an AI Agent in 2026: A Practical Guide
A step-by-step guide to building AI agents that actually work. Choose a framework, define tools, wire up the loop, and ship something real.
10 min read

Ship Code While You Sleep: The Overnight Agent Workflow
How to spec agent tasks that run overnight and wake up to verified, reviewable code. The spec format, pipeline, and review workflow.
11 min read

AI Agents Explained: A TypeScript Developer's Guide
AI agents use LLMs to complete multi-step tasks autonomously. Here is how they work and how to build them in TypeScript.
6 min read

How to Build AI Agents in TypeScript
A practical guide to building AI agents with TypeScript using the Vercel AI SDK. Tool use, multi-step reasoning, and real patterns you can ship today.
10 min read
Multi-Agent Systems: How to Orchestrate Multiple AI Agents in TypeScript
From swarms to pipelines - here are the patterns for coordinating multiple AI agents in TypeScript applications.
6 min read
Open Source Has a Bot Problem: Prompt Injection in Contributing.md
AI coding agents now read repository docs, config, issues, and comments before opening pull requests. That turns CONTRIBUTING.md and AGENTS.md into part of the security boundary.
8 min read

What Is Claude Code? The Complete Guide for 2026
Claude Code is Anthropic's AI coding agent for terminal, IDE, desktop, and browser workflows. Learn what it does, how it works, pricing, setup, MCP, skills, hooks, and subagents.
15 min read
What Is MCP (Model Context Protocol)? A TypeScript Developer's Guide
MCP lets AI agents connect to databases, APIs, and tools. Here is what it is and how to use it in your TypeScript projects.
5 min read
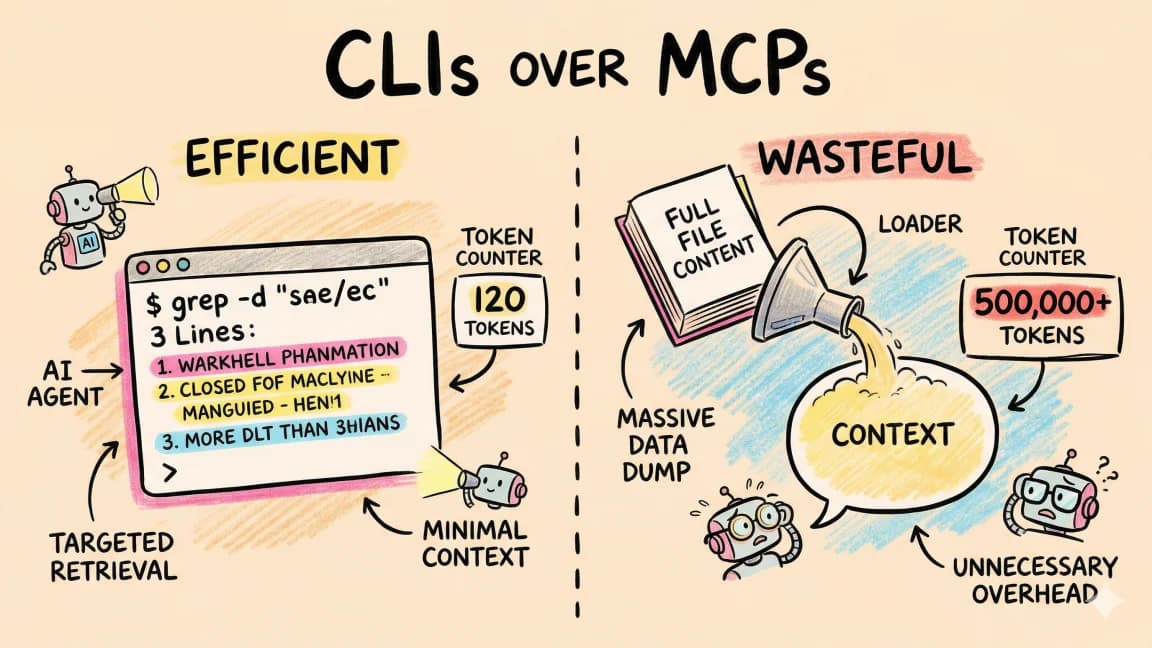
CLIs Over MCPs: Why the Best AI Agent Tools Already Exist
OpenClaw has 247K stars and zero MCPs. The best tools for AI agents aren't new protocols - they're the CLIs developers have used for decades.
8 min read
Composio 101: Give Your AI Agent Access to 500+ Apps
Composio is a tool infrastructure layer that connects AI agents to Gmail, GitHub, Slack, Google Calendar, and hundreds more apps - all auth handled for you. Here is how to set it up and start building real cross-app workflows.
7 min read

OpenAI Agents SDK for TypeScript: A Practical Guide
OpenAI released their Agents SDK for TypeScript with first-class support for tool calling, structured outputs, multi-agent coordination, streaming, and human-in-the-loop approvals. Here is how each piece works.
9 min read

OpenAI Deep Research: The AI Agent That Does Your Homework
OpenAI's Deep Research is an AI agent inside ChatGPT that plans and executes multi-step research workflows, browsing dozens of websites and producing cited reports in minutes instead of hours.
7 min read

ChatGPT Tasks: Scheduled AI Agents Inside ChatGPT
OpenAI added scheduled tasks and reminders to ChatGPT, turning it from a chat interface into something closer to a personal AI agent. Here is how it works, what it can do today, and where this is heading.
8 min read

Gemini Deep Research: Google's AI Research Agent
Google's Gemini Advanced includes a deep research feature that searches dozens of websites, verifies information across multiple sources, and generates detailed cited reports. Here is how it works and how it compares to other AI research tools.
8 min read

Build an AI Agent Web App with LangGraph and CopilotKit
Wire a Python LangGraph agent into a Next.js frontend using CopilotKit's co-agent architecture. Full walkthrough covering the graph, search nodes, streaming state, and the React UI.
14 min read
Related Tools
All tools →OpenAI Agents SDK
Lightweight Python framework for multi-agent systems. Agent handoffs, tool use, guardrails, tracing. Successor to the experimental Swarm project.
AI Frameworksn8n
Self-hostedWorkflow automation platform with native AI agent building. Visual editor plus JavaScript/Python code nodes, 500+ integrations, self-hostable under a fair-code license.
ProductivityAgentCanvas
NewA hosted infinite canvas your headless AI agents drive over MCP. Any MCP-speaking agent - Claude Code, Codex, Cursor, or a script - creates HTML docs, images, and video on a live canvas, streamed in as it builds.
ProductivityGuides
All guides →Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
GuideMCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
GuideBuilding Your First MCP Server
Step-by-step guide to building an MCP server in TypeScript - from project setup to tool definitions, resource handling, testing, and deployment.
GuideAI Agent Frameworks Compared: LangGraph vs CrewAI vs Mastra vs CopilotKit
Deep comparison of the top AI agent frameworks - LangGraph, CrewAI, Mastra, CopilotKit, AutoGen, and Claude Code.
GuideKeep exploring
More on AI Agents
- - OpenAI Agents SDK - recommended AI Agents tool from the Developers Digest directory
- - Compare Tools - dive deeper across the Developers Digest knowledge base
- - All AI Agents articles in the blog archive
- - Developers Digest on YouTube - video tutorials covering AI Agents and more

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever
Explore 659 topics
Browse All Topics