//
Codebase Graphs Are the New Agent Map

TL;DR
Graphify is trending because coding agents keep hitting the same wall: they can edit files, but they still need a durable map of how the codebase, docs, schemas, and decisions connect.
Official Sources
| Source | Description |
|---|---|
| Graphify GitHub | Claude Code skill that converts project folders into queryable knowledge graphs |
| Aider Repo Map Docs | Documentation on tree-sitter based repo maps for AI coding |
| Sourcegraph Cody Docs | Cody AI assistant documentation on codebase context |
| Model Context Protocol | Official MCP introduction and protocol specification |
| Claude Code Memory Docs | Anthropic's docs on Claude Code memory and context management |
The most useful GitHub trend this morning is not another chat wrapper.
It is a map.
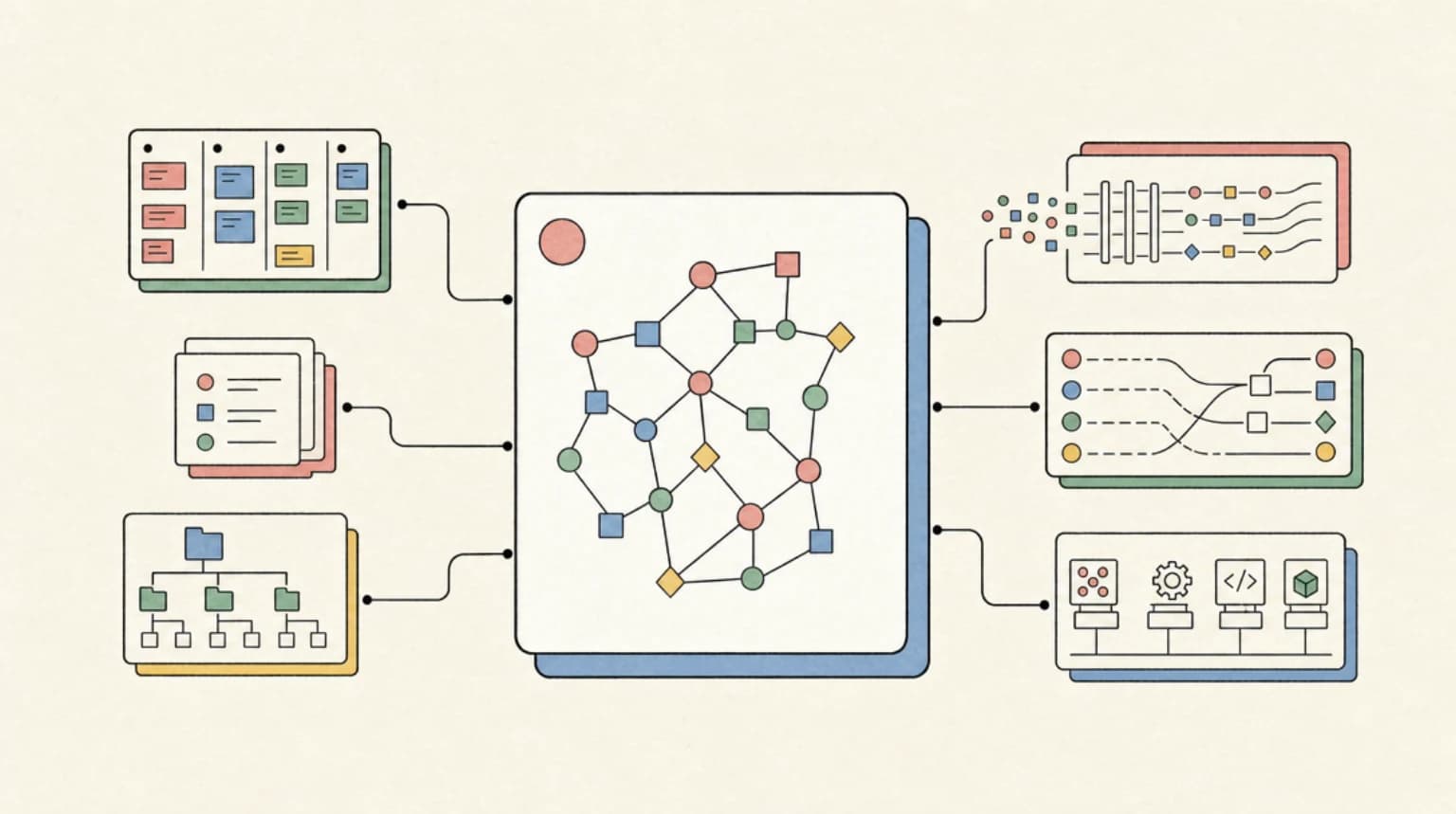
Graphify is a fast-growing Claude Code skill that turns a folder of code, markdown, PDFs, screenshots, diagrams, schemas, and other project material into a queryable knowledge graph. The pitch is specific: drop it on a repo or research folder, get an interactive graph, an Obsidian-style vault, a wiki, a JSON graph, a report of high-degree nodes, surprising connections, suggested questions, and provenance labels for what was extracted versus inferred.
That is a much more interesting signal than the star count alone.
The agent market has spent the last year arguing about which model writes the best patch. The next bottleneck is different: agents need durable maps of the systems they are operating inside. Without that, every long coding run becomes another expensive rediscovery loop.
That is the same pressure behind terminal agents becoming portable runtime surfaces, Claude Code token-burn observability, and the context reduction pattern. The agent does not need every file pasted into context. It needs the right local map, with evidence, boundaries, and a path back to verification.
The Take
Codebase graphs are becoming the new repo map.
Aider made the repo-map idea concrete for AI coding: use tree-sitter to build a compact view of symbols and relationships, then spend context on the parts of the codebase that matter. That pattern still works, and it is why Aider vs Claude Code is still a useful comparison.
Graphify points at the next version of the same idea. Modern agent work is not only source code. It includes:
- product notes
- schemas
- migration history
- screenshots
- architecture diagrams
- bug reports
- transcripts
- research papers
- design system rules
- deployment runbooks
- prior agent decisions
Those objects do not fit neatly into a file tree. They fit better as a graph.
If the agent can ask "what connects this billing route to this auth policy?" or "which docs contradict the current schema?" or "what changed since the last successful deploy?", it can navigate like an engineer instead of rereading the whole repo like a distracted intern.
Why This Is Trending Now
The timing makes sense.
Coding agents have become capable enough that the failure mode moved up a layer. The model can usually make a plausible edit. The hard part is knowing which edit is appropriate inside this specific system.
That is why developers keep building surrounding infrastructure:
- skills and memory files to preserve local conventions
- repo maps to compress code structure
- MCP servers to expose tool state
- terminal runtimes with approvals and rollback
- hooks that run tests after edits
- cost monitors that catch runaway context
- PR receipts that explain what changed and why
Graphify sits in that same category. It is not trying to be the model. It is trying to be part of the agent's working memory.
The README claims a 71.5x token reduction on a mixed corpus of Karpathy repos, papers, and images. Treat that as a project-specific benchmark, not a universal law. But the direction is right: structure beats repeated full-context reads when the corpus gets large enough.
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools - delivered free every week.
From the archive
Ruflo Is an Agent Meta-Harness. Treat the Star Count as a Warning Label.
May 10, 2026 • 8 min read
Claude Managed Agents Are Starting to Look Like Backend Jobs
May 9, 2026 • 9 min read
Agent-Native Backends Are the Next AI Coding Bottleneck
May 8, 2026 • 8 min read
6 Launches in One Day: The DD Empire Expansion
May 7, 2026 • 6 min read
The Real Product Is Provenance
The best detail in Graphify is not the visual graph. It is the edge labeling.
The project says each edge is tagged as EXTRACTED, INFERRED, or AMBIGUOUS. That matters because agent context is dangerous when it looks more certain than it is.
A useful codebase map should separate:
- facts found directly in code
- relationships inferred from names or call paths
- claims copied from docs
- stale notes that may no longer match production
- hypotheses that need verification
That distinction is the difference between a map and fan fiction.
This is also where many memory systems fall apart. A persistent note that says "the checkout flow uses Stripe webhooks" is not enough. The agent needs to know where that came from, when it was observed, which files support it, and which tests or logs can prove it still holds.
That is why the next useful agent-memory product will look less like a notebook and more like a graph with receipts.
The Opposing Take
The skeptical view is fair: knowledge graphs have been oversold before.
Developers have seen enterprise graph demos where everything connects to everything, the visualization looks impressive, and the daily workflow never changes. A codebase graph can become another artifact that ages out of sync, costs tokens to maintain, and gives the agent a false sense of understanding.
There are real failure modes:
- The graph can preserve stale architecture decisions after the code moved on.
- Inferred edges can look factual if the UI does not mark uncertainty clearly.
- Generated wiki pages can compress away the edge case that matters.
- Multimodal extraction can misread screenshots or diagrams.
- A graph can help exploration but still fail to validate behavior.
- Rebuild hooks can add noise if every commit produces a large artifact churn.
So the right question is not "does the graph look clever?"
The right question is "does this graph reduce real agent mistakes?"
If it does not help the agent choose better files, avoid duplicate work, explain risk, run better tests, or leave better receipts, it is decoration.
What A Serious Codebase Graph Needs
For agent work, a codebase graph should be scored like infrastructure.
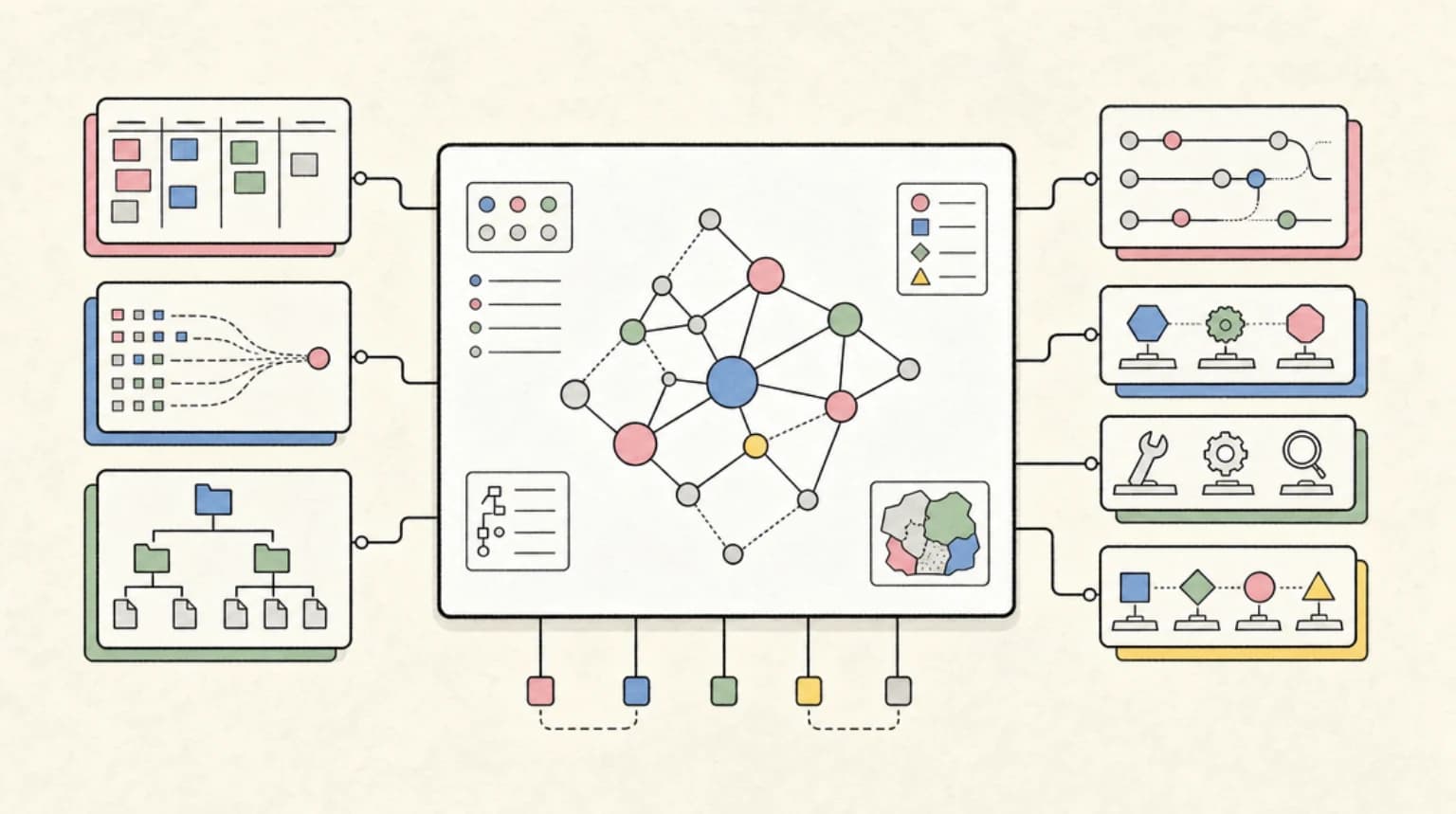
1. Incremental Updates
The graph has to stay current without turning every edit into a full re-index.
Graphify's cache and --update path are the right shape. Code changes should be cheap to refresh. Docs, diagrams, and PDFs can take a slower pass. The important part is that the agent knows whether it is reading a fresh edge or stale context.
2. Source Links
Every useful node should route back to evidence.
If a graph says a route depends on a policy, click through to the route, policy, migration, test, or doc. If the relationship came from inference, say that. If it came from a generated summary, point to the raw source.
This is the same standard public technical content should meet: claims need sources. Agents should hold themselves to the same rule.
3. Agent-Navigable Output
The visual graph is useful for humans, but agents need boring files.
Graphify's wiki output is interesting because it gives another agent a markdown entry point. That is the practical surface. A coding agent can read index.md, follow links, inspect a community page, and then jump to files. It does not need to parse a dense PNG of nodes.
4. Uncertainty Labels
The graph should make uncertainty loud.
EXTRACTED, INFERRED, and AMBIGUOUS are good starting labels. Teams may need more: STALE, TESTED, PRODUCTION_OBSERVED, DOC_ONLY, HUMAN_CONFIRMED, or BROKEN_BY_RECENT_DIFF.
This is where graph memory connects to agent swarms needing receipts. More context is not better unless the context explains how much to trust it.
5. Verification Paths
A graph should not end at an answer. It should end at a check.
If the agent asks "what owns this checkout failure?", the graph can identify likely files and docs. The next step should be a test, log query, smoke check, or reproduction command. That is how codebase maps become operational, not ornamental.
This is the same lesson behind long-running agents needing harnesses. A map is useful because it points the harness at the right verification loop.
Where This Fits In The Stack
I would not replace existing tools with a graph layer. I would add it where current agent workflows already leak time.
Use a codebase graph when:
- the repo is too large for normal context stuffing
- architecture knowledge lives across docs, tickets, schemas, and code
- multiple agents are editing related modules
- onboarding requires repeated "where does this live?" questions
- migrations and policies matter as much as application code
- historical decisions affect current implementation choices
Do not use it as a substitute for:
- tests
- typechecks
- code review
- runtime logs
- source-level inspection
- explicit task acceptance criteria
The graph should narrow the search space. It should not become the authority.
My Take
Graphify is interesting because it names a real pain: agents are still bad at carrying system structure across sessions.
That does not mean every team needs a knowledge graph tomorrow. Small repos still fit in simple context windows. Many projects need better tests before they need better maps. And any generated graph has to prove that it reduces mistakes, not just tokens.
But the direction is right.
AI coding is moving from prompt craft to operating systems. Repos need maps. Agents need provenance. Teams need receipts. The winning context layer will not be the one that remembers the most. It will be the one that helps an agent decide what to inspect, what to trust, and what to verify next.
FAQ
What is Graphify?
Graphify is a Claude Code skill and CLI workflow that turns folders of code, docs, PDFs, images, diagrams, and other project material into a queryable knowledge graph. It can output an interactive graph, markdown wiki, Obsidian-style vault, JSON graph, and report.
Why do AI coding agents need codebase graphs?
Agents need compact structure. A graph can show relationships among files, functions, docs, schemas, decisions, and tests without stuffing the whole repo into context. That helps the agent choose better files and ask better follow-up questions.
Is a codebase graph better than a repo map?
It depends on the job. A repo map is excellent for symbol-level code navigation. A broader graph is more useful when the task crosses code, documentation, diagrams, research, schemas, and prior decisions. The best systems will likely use both.
What is the risk of using generated knowledge graphs?
The main risk is false confidence. If inferred or stale relationships look factual, the agent may make wrong edits faster. A serious graph needs source links, uncertainty labels, freshness metadata, and verification paths.
Should every repo add a codebase graph?
No. Small repos may not need it. Add a graph when repeated context discovery is slowing agents down, when knowledge lives across many artifact types, or when multiple agents need a shared map of the same system.
Read next
Terminal Agents Are the New Developer Runtime
Terminal agents like Claude Code, Codex CLI, OpenCode, Copilot CLI, and DeepSeek-TUI are converging on the same runtime layer: permissions, sandboxing, rollback, diagnostics, subagents, receipts, and cost controls.
9 min readClaude Code Token Burn Is an Observability Problem
The latest Claude Code cache-burn debate is not just a quota complaint. It is a reminder that coding agents need cache-hit telemetry, spend ceilings, and repro-grade usage logs.
8 min readThe 98% Context Reduction Pattern
Efficient agents do not stuff every tool result into the model context. They keep intermediate state in code, files, and execution environments, then return compact summaries and receipts.
8 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Try These Tools
Related Tools
AI CodingDaily Driver
Claude Code
Anthropic's agentic coding CLI. Runs in your terminal, edits files autonomously, spawns sub-agents, and maintains memory...
View ToolAI Coding
Augment Code
AI coding platform built for large, complex codebases. Context Engine indexes 500K+ files across repos with 100ms retrie...
View ToolAI Coding
Conductor
Mac app for running parallel Claude Code, Codex, and Cursor agents in isolated workspaces. Watch every agent work at onc...
View ToolAI CodingAgent
OpenAI Codex
OpenAI's coding agent for terminal, cloud, IDE, GitHub, Slack, and Linear workflows. Reads repos, edits files, runs comm...
View ToolApps from Developers Digest
Developer ToolsIn Progress
Subagent Studio
Design subagents visually instead of editing YAML by hand.
View AppDeveloper ToolsIn Progress
Agent Benchmark Lab
Compare AI coding agents on reproducible tasks with scored, shareable runs.
View AppDeveloper Tools
Agent Hub
Every coding agent in one window. Stop alt-tabbing between Claude, Codex, and Cursor.
View AppRelated Guides
Guide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsGuide
AI Agent Frameworks Compared: LangGraph vs CrewAI vs Mastra vs CopilotKit
Deep comparison of the top AI agent frameworks - LangGraph, CrewAI, Mastra, CopilotKit, AutoGen, and Claude Code.
AI AgentsGuide
AGENTS.md - Claude Code
Define custom subagent types within your project's memory layer.
Claude CodeRelated Videos

Related Posts

9 min read
AI Coding
Terminal Agents Are the New Developer Runtime
Terminal agents like Claude Code, Codex CLI, OpenCode, Copilot CLI, and DeepSeek-TUI are converging on the same runtime...

8 min read
Claude Code
Claude Code Token Burn Is an Observability Problem
The latest Claude Code cache-burn debate is not just a quota complaint. It is a reminder that coding agents need cache-h...

8 min read
Context Engineering
The 98% Context Reduction Pattern
Efficient agents do not stuff every tool result into the model context. They keep intermediate state in code, files, and...

5 min read
Aider
Aider vs Claude Code: Open Source vs Commercial AI Coding CLI
Aider is open source and works with any model. Claude Code is Anthropic's commercial agent. Here is how they compare for...

9 min read
AI Agents
Long-Running Agents Need Harnesses, Not Hope
A long-running coding agent is only useful if the environment around it can queue tasks, capture logs, checkpoint state,...

8 min read
AI Coding
Agent Replays with TraceTrail: Loom for Agent Runs
Agent runs are opaque. TraceTrail turns a Claude Code JSONL into a public share link with a stepped timeline of messages...

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever