RAG with Claude: Add Context Without Retraining

TL;DR
A production-grade RAG pipeline with Claude. Chunking that survives real documents, retrieval tuning that actually moves the needle, citation tracking, and the prompt caching trick that makes RAG cheap enough to ship.
Official Sources#
| Resource | Link |
|---|---|
| Anthropic Embeddings Guide | platform.claude.com/docs/en/build-with-claude/embeddings |
| Anthropic Prompt Caching | platform.claude.com/docs/en/build-with-claude/prompt-caching |
| Anthropic Messages API | platform.claude.com/docs/en/api/messages |
| Anthropic TypeScript SDK | github.com/anthropics/anthropic-sdk-typescript |
| Cohere Rerank API | docs.cohere.com/docs/rerank-overview |
| Anthropic Pricing | claude.com/pricing |
Why RAG with Claude beats fine-tuning for almost everyone#
If you have proprietary data and you want a model to answer questions about it, you have three options. Few-shot in the prompt. Retrieval-augmented generation. Fine-tuning.
For 90 percent of teams, the right answer is RAG. Few-shot dies the moment your knowledge base outgrows the context window. Fine-tuning is expensive, slow to iterate on, and changes the model's behavior in ways that are hard to predict and harder to undo. RAG keeps the base model unchanged, scales to arbitrary document counts, and lets you update the knowledge base by re-indexing instead of retraining.
The case for fine-tuning is narrower than people think. Fine-tune when you need a specific output format the base model resists, or when you have millions of high-quality examples and latency matters more than freshness. Everything else is RAG, and Claude is genuinely good at the synthesis step that turns retrieved chunks into a grounded answer.
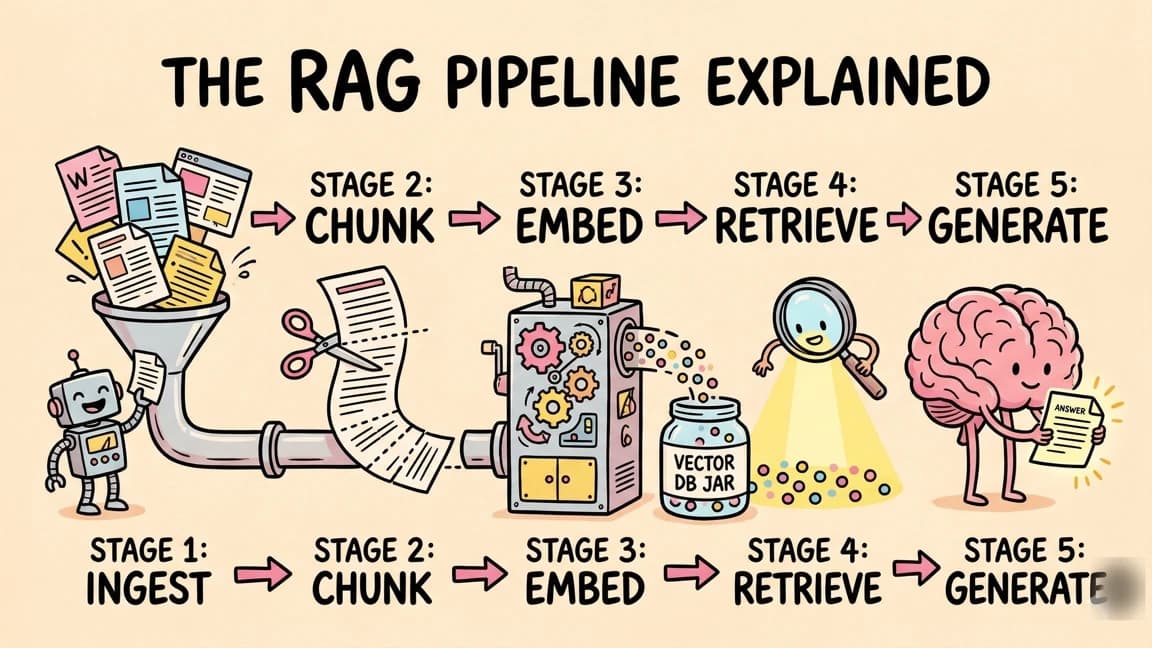
We covered the conceptual basics in what is RAG. This post is the implementation - the parts that don't show up in the marketing diagrams.
Chunking is the single biggest lever#
Every RAG team I have worked with underestimates chunking. Then they spend three weeks tuning their retriever before realizing the problem was upstream.
The naive approach is fixed-size chunks. Split your document every 1000 tokens. This breaks the moment a sentence, a code block, or a table spans a boundary. Your retriever returns half a thought. Claude makes up the other half. You blame the embeddings.
The right approach is semantic chunking with hierarchy. Three rules.
Respect document structure. Markdown headings, HTML sections, code fences, table boundaries. These are pre-existing semantic units. Use them as primary chunk boundaries. Falling back to paragraph breaks before falling back to sentence breaks before falling back to fixed token windows.
Keep parent context. Every chunk should carry metadata about what document it came from, what section, what the surrounding heading hierarchy was. When you retrieve a chunk that says "the limit is 100 requests per minute," the retriever needs to know whether that was about the free tier or the enterprise tier. Stuff the heading path into a context field on each chunk.
Overlap, but small. A 10-15 percent token overlap between adjacent chunks helps with the case where the answer straddles a boundary. More overlap wastes embedding budget. Less overlap loses answers.
TypeScript
interface Chunk {
id: string;
text: string;
documentId: string;
headingPath: string[];
position: number;
metadata: Record<string, string>;
}
function chunkMarkdown(doc: string, docId: string): Chunk[] {
const sections = splitByHeadings(doc);
const chunks: Chunk[] = [];
let position = 0;
for (const section of sections) {
const tokens = estimateTokens(section.body);
if (tokens < 1200) {
chunks.push({
id: `${docId}:${position}`,
text: section.body,
documentId: docId,
headingPath: section.headings,
position: position++,
metadata: { tokenCount: String(tokens) },
});
} else {
const subs = splitByParagraphs(section.body, 1000, 150);
for (const sub of subs) {
chunks.push({
id: `${docId}:${position}`,
text: sub,
documentId: docId,
headingPath: section.headings,
position: position++,
metadata: { tokenCount: String(estimateTokens(sub)) },
});
}
}
}
return chunks;
}
This is not glamorous code. It is the code that determines whether your RAG works.
Retrieval: hybrid wins, almost always#
Pure vector search loses to hybrid search on real workloads. The reason is that embeddings are good at semantic similarity and bad at exact-match recall. A user query for "error code E47" needs to find the chunk that contains the literal string "E47," and the embedding model sees both as roughly equivalent vectors.
Hybrid search runs both: BM25 (or a similar keyword index) and a vector search, then fuses the rankings. Reciprocal Rank Fusion is the simplest fusion algorithm and it works.
TypeScript
interface ScoredChunk {
chunk: Chunk;
score: number;
}
function reciprocalRankFusion(
rankings: ScoredChunk[][],
k = 60
): ScoredChunk[] {
const scores = new Map<string, { chunk: Chunk; score: number }>();
for (const ranking of rankings) {
ranking.forEach((item, rank) => {
const existing = scores.get(item.chunk.id);
const fused = 1 / (k + rank + 1);
if (existing) existing.score += fused;
else scores.set(item.chunk.id, { chunk: item.chunk, score: fused });
});
}
return Array.from(scores.values()).sort((a, b) => b.score - a.score);
}
async function retrieve(query: string, topK = 8): Promise<Chunk[]> {
const [vectorHits, keywordHits] = await Promise.all([
vectorSearch(query, topK * 2),
keywordSearch(query, topK * 2),
]);
const fused = reciprocalRankFusion([vectorHits, keywordHits]);
return fused.slice(0, topK).map((s) => s.chunk);
}
The next lever is reranking. Pull a top-30 from the hybrid retriever, then run a cross-encoder reranker (Cohere Rerank, BGE Reranker, or a small Claude prompt) over those 30 to pick the best 8. Reranking is expensive per query but it eliminates the long tail of retrieval misses where the right answer was at rank 12 and got dropped.
Don't skip the eval. Build a set of 50 question/answer pairs from your real data. Measure recall at 10 and answer correctness on every retrieval change. Most "improvements" don't improve anything when you measure them.
From the archive
SAM 3.1: Realtime Video Segmentation in Apps
Apr 29, 2026 • 10 min read
Self-Hosting AI Agents: 5 Ways to Run Claude Code on Your Own Infra
Apr 29, 2026 • 13 min read
Shipping OpenAI Symphony in Prod: A Real-World Guide
Apr 29, 2026 • 12 min read
Tool Use in the Claude API: Production Patterns for Reliable Agents
Apr 29, 2026 • 12 min read
Generation: the prompt that prevents hallucination#
The retrieval is half the problem. The generation prompt is the other half.
Three things go into a RAG prompt for Claude.
A system message that tells Claude its job: answer the user's question using only the provided sources. If the sources don't contain the answer, say so explicitly. Do not use prior knowledge. Cite sources by ID.
The retrieved chunks, formatted with clear delimiters and an explicit ID per chunk so citations work.
The user's question.
TypeScript
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const SYSTEM_PROMPT = `You answer questions using only the provided sources.
Rules:
- Cite every claim with [source-id].
- If the sources do not contain enough information to answer, respond exactly: "The provided sources do not contain enough information to answer this question."
- Do not use general knowledge.
- Quote directly when precision matters.`;
function formatSources(chunks: Chunk[]): string {
return chunks
.map(
(c) =>
`<source id="${c.id}" path="${c.headingPath.join(" > ")}">\n${c.text}\n</source>`
)
.join("\n\n");
}
async function generate(question: string, chunks: Chunk[]) {
return await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
system: [
{
type: "text",
text: SYSTEM_PROMPT,
cache_control: { type: "ephemeral" },
},
],
messages: [
{
role: "user",
content: `Sources:\n\n${formatSources(chunks)}\n\nQuestion: ${question}`,
},
],
});
}
The XML-style source tags matter. Claude is trained to respect them as structural delimiters, and it cites by attribute when you ask it to. The "respond exactly" instruction is also load-bearing - without it, Claude will reach for prior knowledge when sources are thin and tell you with confidence things that aren't in your corpus.
Citations and trust: the audit trail you actually need#
Citations in the output are necessary but not sufficient. The full audit trail in production looks like this for every query:
The user question. The retrieved chunk IDs and their relevance scores. The chunks the model actually cited in its response (parsed out of the output). The final answer text.
Log all four. When a user reports a wrong answer, you can immediately see whether the failure was retrieval (right chunks not retrieved), grounding (right chunks retrieved but model ignored them), or hallucination (model cited a chunk that doesn't say what it claimed).
TypeScript
function extractCitations(text: string): string[] {
const matches = text.match(/\[([a-z0-9:.-]+)\]/g) ?? [];
return [...new Set(matches.map((m) => m.slice(1, -1)))];
}
async function answerWithAudit(question: string) {
const chunks = await retrieve(question);
const response = await generate(question, chunks);
const text = response.content
.filter((b): b is Anthropic.TextBlock => b.type === "text")
.map((b) => b.text)
.join("");
return {
question,
retrievedIds: chunks.map((c) => c.id),
citedIds: extractCitations(text),
answer: text,
usage: response.usage,
};
}
The diff between retrievedIds and citedIds is your most useful debugging signal. If the model cited zero retrieved chunks but produced an answer, that is hallucination, full stop.
Prompt caching: the trick that makes RAG affordable#
The single biggest cost optimization for production RAG is prompt caching on the system prompt and any stable context (reference docs, glossaries, persona). For a chatbot that answers from a knowledge base, the system prompt and instructions don't change between queries. Cache them.
Cached reads cost 10 percent of normal input. For a 2k-token system prompt that gets called 10,000 times a day, that is the difference between a real bill and a footnote. Note that the retrieved chunks themselves don't cache well because they vary per query, but the scaffolding around them does.
The full pattern: cache system prompt as one block, put dynamic chunks in the user message, keep the structure stable so cache prefix matching works on every call. For RAG specifically the caching savings often dwarf the embedding and vector DB costs.
Scaling: latency, throughput, and the parts that fail under load#
End-to-end RAG latency breaks down roughly: embedding the query (50-200ms), vector search (20-100ms), keyword search (10-50ms), reranking (200-500ms), Claude generation (1-3s for short answers, 3-10s for long). The generation dominates. Optimizing anything else first is premature.
The two highest-leverage latency wins are streaming the response (start showing tokens at 800ms instead of waiting 3s for the full answer) and parallelizing retrieval calls with Promise.all. Both are free wins.
Throughput hits walls in two places. The vector DB starts choking past a certain QPS depending on which one you picked. And Anthropic rate limits cap your generation throughput. Both need monitoring. Both want exponential backoff with jitter on retries, which we wrote up in Claude API reliability.
Cost monitoring is the part teams skip until the bill comes. Track tokens per query (input from chunks, output from generation), retrieval cost, and per-user cost. We watch this on agent-finops for our own RAG endpoints. The p99 cost user is usually 50x the median and is usually a bot. Catch them early.
For replay and debugging the answers that don't look right, tracetrail lets us step through retrieval and generation with the original chunk set so we can see whether the bug was upstream or in the prompt itself.
If you want a deeper walkthrough, the DevDigest YouTube build of a better RAG pipeline goes through the same architecture end to end with live debugging.
A working RAG system is mostly chunking, retrieval tuning, prompt discipline, and operational hygiene. Claude is excellent at the synthesis step. The job is to feed it the right context and verify what comes out. Get those pieces right and the rest is plumbing.
FAQ#
What is RAG and why use it with Claude?#
RAG (Retrieval-Augmented Generation) is a pattern where you retrieve relevant documents from a knowledge base and include them in the prompt context, allowing the model to answer questions grounded in your proprietary data. Claude is well-suited for RAG because it handles long context well, follows citation instructions reliably, and respects system prompt constraints like "do not use general knowledge." RAG beats fine-tuning for most teams because it keeps the base model unchanged, scales to arbitrary document counts, and lets you update knowledge by re-indexing instead of retraining.
How should I chunk documents for RAG?#
Chunk by semantic structure, not fixed token windows. Respect document boundaries like headings, code fences, and tables as primary chunk points. Fall back to paragraph breaks, then sentence breaks, then fixed windows. Keep chunks between 500-1200 tokens. Include 10-15% token overlap between adjacent chunks. Store heading path metadata with each chunk so the model knows the context (e.g., which tier a rate limit applies to).
What is hybrid search and why does it beat pure vector search?#
Hybrid search combines vector (semantic) search with keyword (BM25) search, then fuses the rankings. Pure vector search fails on exact-match queries like error codes, product names, or configuration values because embeddings treat similar terms as equivalent. Hybrid search catches these cases through the keyword index while preserving semantic relevance from embeddings. Use Reciprocal Rank Fusion to merge the rankings.
How do I prevent hallucination in RAG with Claude?#
Use a system prompt that explicitly tells Claude to answer only from provided sources and to say "The provided sources do not contain enough information" when they don't. Format sources with clear XML-style delimiters and unique IDs. Require citations by ID for every claim. Parse citations from the output and compare them against retrieved chunk IDs. If the model cited zero retrieved chunks but produced an answer, that is hallucination.
How does prompt caching reduce RAG costs?#
Prompt caching stores the model's internal state at a prefix, so repeated calls with the same prefix skip re-processing those tokens. Cache reads cost about 10% of normal input. For RAG, cache the system prompt and any stable context (persona, instructions, glossaries) but keep retrieved chunks in the user message where they vary per query. A 2k-token system prompt called 10,000 times daily goes from a real bill to a footnote with caching.
What should I log for RAG debugging?#
Log four things for every query: the user question, the retrieved chunk IDs with relevance scores, the chunk IDs the model actually cited in its response, and the final answer text. When a user reports a wrong answer, compare retrieved vs cited IDs to diagnose whether the failure was retrieval (right chunks not found), grounding (right chunks ignored), or hallucination (cited chunks don't support the claim).
How do I evaluate RAG retrieval quality?#
Build a test set of 50+ question/answer pairs from your real data. Measure recall at K (did the right chunk appear in the top K results) and answer correctness on every retrieval change. Most "improvements" show no gain when measured. Track these metrics in CI so regressions are caught before production. Reranking a top-30 to pick the best 8 often improves recall significantly.
What is the end-to-end latency breakdown for RAG?#
Typical breakdown: query embedding (50-200ms), vector search (20-100ms), keyword search (10-50ms), reranking (200-500ms), Claude generation (1-10s depending on answer length). Generation dominates, so optimize there first. The two free wins are streaming the response (show tokens at 800ms instead of waiting 3s) and parallelizing retrieval calls with Promise.all.
Read next
What is RAG? Retrieval Augmented Generation Explained
How RAG works, why it matters, and how to implement it in TypeScript. The technique that lets AI models use your data without fine-tuning.
8 min readAgent Architecture: Building Multi-Step AI Workflows That Survive Production
A practical architecture for multi-step Claude agents. Loop patterns, state management, error recovery, and the production gotchas that turn a five-step demo into a 20 percent success rate at scale.
11 min readClaude API Reliability: Error Handling Best Practices
The defensive patterns that keep Claude integrations alive in production. Retry shapes, backoff with jitter, circuit breakers, fallback chains, and the observability you need to debug at 3am.
10 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Coding
Augment Code
AI coding platform built for large, complex codebases. Context Engine indexes 500K+ files across repos with 100ms retrie...
View ToolAI CodingFree
Gemini CLI
Google's open-source coding CLI. Free tier with Gemini 2.5 Pro. Supports tool use, file editing, shell commands. 1M toke...
View ToolAI Coding
v0
Vercel's generative UI tool. Describe a component, get production-ready React code with shadcn/ui and Tailwind. Iterate...
View ToolAI Coding
Aider
Open-source AI pair programming in your terminal. Works with any LLM - Claude, GPT, Gemini, local models. Git-aware ed...
View ToolApps from Developers Digest
Developer ToolsIn Progress
Key Vault
Document API key ownership, rotation context, and integration notes without storing secrets.
View AppDeveloper Tools
Hue
Change your lights without leaving the terminal. `hue dim` just works.
View AppDeveloper ToolsPlus $20/mo
Skills Pro
Unlock pro skills and share private collections with your team.
View AppRelated Guides
Guide
Side Questions with /btw - Claude Code
Ask quick side questions without derailing the main task.
Claude CodeGuide
Edit Tool - Claude Code
Targeted edits to specific sections without rewriting entire files.
Claude CodeGuide
Notebook Edit - Claude Code
Modify Jupyter notebook cells directly without touching JSON.
Claude CodeRelated Videos

Nimbalyst: The Open-Source Visual Workspace for Building with Codex and Claude Code
Nimbalyst Demo: A Visual Workspace for Codex + Claude Code with Kanban, Plans, and AI Commits Try it: https://nimbalyst.com/ Star Repo Here: https://github.com/Nimbalyst/nimbalyst This video demos N...
Video·

Streamline Your Git Workflow with GitKraken and Claude Code
Try out GitKraken here: https://gitkraken.cello.so/myw3K67IkCr to get 50% GitKraken Pro. In this video, we explore GitKraken, a robust Git GUI that not only visualizes your Git repository...
Video·

Create Beautiful UI with Claude Code
Creating a Consistent and Beautiful UI for Your AI Application In this video, learn a simple yet effective method to develop a consistent and professional UI design for your AI application....
Video·
Related Posts
8 min read
RAG
What is RAG? Retrieval Augmented Generation Explained
How RAG works, why it matters, and how to implement it in TypeScript. The technique that lets AI models use your data wi...

11 min read
AI Agents
Agent Architecture: Building Multi-Step AI Workflows That Survive Production
A practical architecture for multi-step Claude agents. Loop patterns, state management, error recovery, and the producti...

10 min read
Claude
Claude API Reliability: Error Handling Best Practices
The defensive patterns that keep Claude integrations alive in production. Retry shapes, backoff with jitter, circuit bre...

13 min read
MCP
Model Context Protocol: A Production Guide To Building MCP Servers
Build MCP servers that connect Claude to your databases, APIs, and tools. Architecture, TypeScript SDK code, debugging,...

10 min read
OpenAI
OpenAI Privacy Filter: Production PII Redaction Guide
OpenAI shipped an open-weight PII redactor. Here is how to wire it into a real ingestion pipeline locally, fast, with ze...

10 min read
AI Models
Budget AI Coding Models Compared July 2026: V4 Flash vs Luna vs Gemini 3.5 Flash vs Haiku 4.5
The sub-$1.50 coding tier just got serious: DeepSeek V4 Flash 0731 posts frontier-adjacent agent scores at $0.14/$0.28,...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever