Fable 5 vs DeepSeek V4: The Cost-Quality Gap Measured in Real Tasks
The Fable 5 Moment
31 parts- 1Claude Mythos 5 Explained: What It Is, Who Can Access It, and Why It's Gated
- 2Migrating to Claude Fable 5: The Practical Guide
- 3Fable 5 Leaves Your Claude Plan on June 22. Here's How to Plan for It
- 4Claude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
- 5Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
- 6Claude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
- 7How to Model Fable 5 Costs Before They Blow Up Your Budget
- 8Claude Fable 5 API: Production Integration Patterns, Rate Limits, and Migration Gotchas
- 9Handling Fable 5 Refusals: A Working Guide to the Fallback API
- 10Why Fable 5 Refuses Your Cybersecurity Queries (And How the Fallback Works)
- 11Fable 5's Hidden Guardrails: What Developers Need to Know About Silent Degradation
- 12Fable 5 Broke Enterprise ZDR Agreements: What Dev Teams Must Do Now
- 13Claude Managed Agents: Dreaming, Outcomes, and Multi-Agent Orchestration Explained
- 14Claude Managed Agents Public Beta: What's Actually Available vs What's Gated
- 15Dario Amodei Wants FAA-Style AI Regulation: Open Questions for Developers
- 16The Exponential and the Working Developer: Sitting With Amodei's Hardest Questions
- 17The Dario Paradox: Warning About the Exponential While Shipping It
- 18The Pushback on Amodei's Exponential Essay: Too Slow, Too Convenient, or About Right?
- 19Fable 5 Before June 22: The Decision Checklist for Every Plan Tier
- 20Fable 5 on AWS Bedrock: When Your Data Leaves the AWS Boundary
- 21Why Claude Desktop Quietly Installs a 1.8 GB VM on Windows (And What You Can Do About It)
- 22Decoding Anthropic's Model Names: Fable, Mythos, and What the Naming Shift Signals
- 23Managed Agents vs LangGraph vs Rolling Your Own: Who Should Run Your Agent Loop in 2026
- 24How Claude's Usage Limits Actually Work With Fable 5: Windows, Multipliers, and Burn Rates
- 25Fable 5 for Government and Regulated Teams: The GovCloud Question
- 26Fable 5 vs DeepSeek V4: The Cost-Quality Gap Measured in Real TasksCurrent
- 27The Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap Workers
- 28Prompt Caching Economics on Fable 5: When the 5-Minute TTL Pays
- 29Fable 5 with 1M Context: What Actually Works in Practice
- 30Fable 5 Effort Levels Explained: low to xhigh, and What They Cost You
- 31Recursive Self-Improvement: What Fable 5, Dario's Essay, and Anthropic's Own Data Actually Tell Us
TL;DR
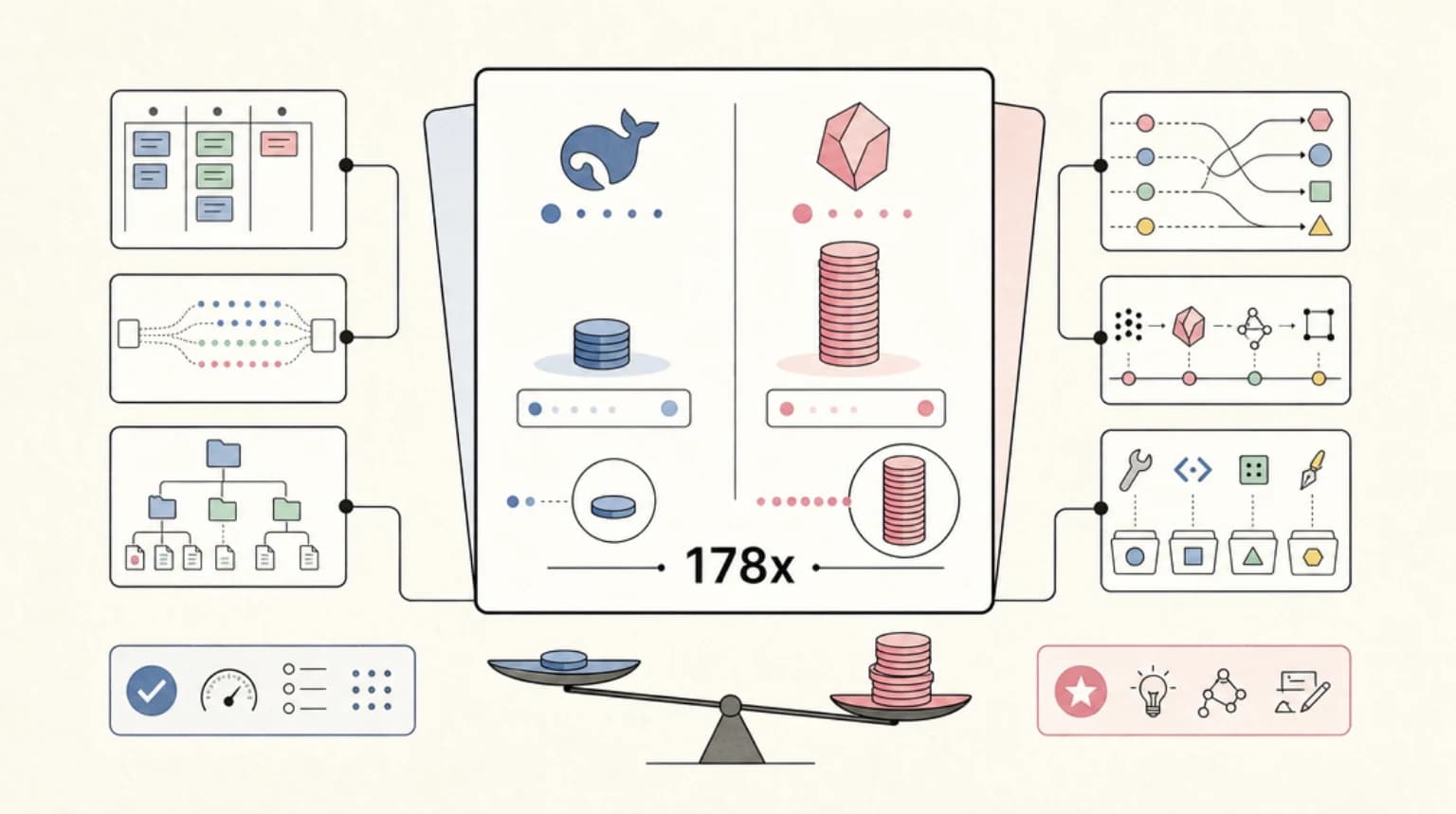
DeepSeek V4-Flash costs $0.28 per million output tokens. Fable 5 costs $50. That 178x gap is real - but so is the quality difference. Here is where it matters and where it does not.
Direct answer
Fable 5 vs DeepSeek V4: The Cost-Quality Gap Measured in Real Tasks
DeepSeek V4-Flash costs $0.28 per million output tokens. Fable 5 costs $50. That 178x gap is real - but so is the quality difference. Here is where it matters and where it does not.
Best for
Developers comparing real tool tradeoffs before choosing a stack.
Covers
Verdict, tradeoffs, pricing signals, workflow fit, and related alternatives.
Official Sources#
| Source | Link |
|---|---|
| DeepSeek API Pricing | api-docs.deepseek.com/quick_start/pricing |
| DeepSeek V4-Pro Technical Details | platform.deepseek.com |
| Anthropic Claude Pricing | claude.com/pricing |
| Anthropic Models Documentation | platform.claude.com/docs/en/docs/about-claude/models |
| DeepSeek V4 Model Card | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
Every engineer running LLMs in production eventually runs the same back-of-envelope: what would this workload cost if I swapped Anthropic for DeepSeek? With Fable 5 at $10/$50 per million input/output tokens and DeepSeek V4-Flash at $0.14/$0.28, the headline ratio is 178x on output. That number is real. So is the quality difference. The question is whether the quality gap falls in the part of your stack that matters.
This post breaks down the pricing, the benchmark evidence, and the practical split that most production teams end up running: DeepSeek for the high-volume commodity work, Fable 5 for the irreplaceable judgment calls.
Last updated: June 18, 2026
The Pricing Numbers, Precisely#
DeepSeek ships two V4 variants. The official API docs (api-docs.deepseek.com) list current rates:
| Model | Input (cache miss) | Input (cache hit) | Output |
|---|---|---|---|
| DeepSeek V4-Flash | $0.14 / MTok | $0.0028 / MTok | $0.28 / MTok |
| DeepSeek V4-Pro | $0.435 / MTok | $0.003625 / MTok | $0.87 / MTok |
| Fable 5 | $10.00 / MTok | - | $50.00 / MTok |
The cache hit discount on DeepSeek is dramatic: 98% off the cache-miss rate for V4-Flash. In practice, agentic applications with stable system prompts and tool definitions - the dominant pattern in production - hit cache rates of 60-70% after warm-up. That pushes effective input cost well below the headline figure.
At full prices, a million output tokens costs $50 with Fable 5, $0.87 with V4-Pro, and $0.28 with V4-Flash. That is a 57x to 178x spread depending on which DeepSeek model you reach for.
Where the Gap Comes From#
DeepSeek V4-Pro is a mixture-of-experts model with 1.6 trillion total parameters and 49 billion active per forward pass. Because compute cost scales with active parameters, not total parameters, inference is cheap. The MoE router activates the relevant experts per token and leaves the rest dormant - roughly 10x fewer FLOPs than a dense model at comparable capability. That architecture-level efficiency is what makes the pricing sustainable rather than promotional.
Fable 5 is a dense frontier model optimized for quality, not cost. The pricing reflects that. You are paying for the last few percentage points of correctness on hard tasks, not for commodity text generation.
What the Benchmarks Actually Show#
DeepSeek V4-Pro scores around 81% on SWE-bench Verified, the standard software engineering agentic benchmark, up from V3's 69%. Fable 5 scores in the high 80s to low 90s on the same benchmark depending on scaffolding. The gap is real but narrower than the price suggests.
On math reasoning (AIME, MATH-500) and code generation (HumanEval, MBPP), V4-Pro sits within about 5-8 percentage points of Fable 5. On tasks requiring nuanced judgment - ambiguous requirements, multi-stakeholder trade-offs, subtle security implications, long document analysis with conflicting information - the gap widens. These are the tasks where training compute and data quality compound.
The practical implication: for structured tasks with clear success criteria, DeepSeek V4-Pro is close enough that the 57x price difference dominates the decision. For tasks where "close enough" is undefined - or where wrong is expensive - Fable 5 earns its price.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Claude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
Jun 10, 2026 • 7 min read
Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
Jun 10, 2026 • 7 min read
Factory AI and the Model Routing Era: How Coding Agents Are Learning to Spend Your Tokens Wisely
Jun 10, 2026 • 8 min read
Factory Droid: Review and Setup Guide (2026)
Jun 10, 2026 • 8 min read
The Task Split That Works in Production#
Most teams running both models converge on a similar split within a few weeks. The pattern is not complicated but it does require being honest about which category each task falls into.
High-volume tasks where DeepSeek V4-Flash is good enough:
Extraction and classification are the clearest wins. Pulling structured data from documents, tagging content, labeling intent, summarizing long articles into consistent formats - these tasks have objective ground truth, and DeepSeek V4-Flash handles them at quality parity in most evaluations. At $0.28/M output tokens with 65% cache hit rates on stable system prompts, the effective cost for a classification pipeline drops to roughly $0.06-0.10 per million tokens all-in. That is 300-500x cheaper than running the same pipeline on Fable 5.
Retrieval-augmented generation for factual Q&A, customer support triage, code explanation for well-understood patterns, and translation fall in the same category. The quality ceiling is constrained by the retrieval quality anyway, and both models hit it.
Tasks where Fable 5's quality gap is worth paying for:
Code generation for complex, context-dependent changes - the kind that require holding hundreds of lines of existing code in mind while reasoning about invariants, security properties, and downstream effects - is where Fable 5 consistently outperforms. The SWE-bench gap is 8-10 percentage points, but in practice the gap widens on harder instances. A botched architectural change costs more than the API delta.
Security review, legal document analysis, multi-step reasoning chains where intermediate errors compound, and any task where the output is consumed without human review are the other canonical cases. When you cannot cheaply verify the output, the cost of an error has to be factored into the per-task price.
Agent orchestration is a middle case. Simple linear pipelines run fine on V4-Pro. Long-horizon agentic tasks with tool use, error recovery, and ambiguous sub-goals tend to break down more often on open-weights models. The failure mode is subtle: the agent completes the task without signaling uncertainty, producing a plausible but wrong result. That is harder to catch than an obvious error.
A Concrete Cost Scenario#
A team processing 50 million output tokens per month - a medium-sized production workload - would pay $2,500/month on DeepSeek V4-Flash or $43,500/month on Fable 5 for that volume alone.
Routing 85% of that volume (commodity extraction, classification, summarization) to V4-Flash and reserving Fable 5 for the remaining 15% (complex code changes, security review, high-stakes generation) lands at roughly $2,275 + $6,525 = $8,800/month. That is a 79% cost reduction from all-Fable-5, with quality unchanged on the tasks where quality was already saturated.
The routing logic itself is worth building carefully. Mis-routing a genuinely hard task to V4-Flash to save $0.44 and then paying a developer two hours to fix the result is not a winning trade.
The Open-Weights Consideration#
DeepSeek V4-Pro weights are public. Teams with on-premise requirements or data residency constraints can self-host, which eliminates the per-token charge entirely and reduces cost to compute. At scale, self-hosting V4-Pro on owned hardware competes favorably even against DeepSeek's already-low API pricing.
Fable 5 has no open-weights release. For teams where the Anthropic API is not viable - regulatory environments, air-gapped infrastructure, cost structures that require owning the compute - V4-Pro is the frontier-quality option available. The self-hosting operational burden is real, but the capability level is close enough to justify it for many use cases.
FAQ#
How much cheaper is DeepSeek V4 than Fable 5?#
DeepSeek V4-Flash costs $0.14/$0.28 per million input/output tokens versus Fable 5's $10/$50. That is a 71x gap on input and a 178x gap on output at list prices. With DeepSeek's cache hit pricing ($0.0028/M on cache hits), repeated-prefix workflows can push effective input cost over 3,500x cheaper than Fable 5 on cached tokens.
Is DeepSeek V4-Pro good enough to replace Fable 5 for coding tasks?#
For greenfield code generation and standard refactoring, V4-Pro handles most tasks at comparable quality. The gap shows on complex, context-dependent changes involving large codebases, security-sensitive logic, or ambiguous requirements. V4-Pro scores around 81% on SWE-bench Verified versus Fable 5 in the high 80s - a meaningful but not catastrophic difference for tasks with human review downstream.
Can I self-host DeepSeek V4 to avoid API costs entirely?#
Yes. DeepSeek releases V4 weights publicly. V4-Pro requires substantial GPU infrastructure (multiple high-memory GPUs or a distributed setup), but at sufficient scale the compute cost undercuts even DeepSeek's low API pricing. V4-Flash is lighter and accessible on smaller hardware configurations. Fable 5 weights are not publicly available.
What is the safest way to start migrating workloads to DeepSeek?#
Start with extraction and classification pipelines that have clear, measurable success criteria. Evaluate on a held-out sample before switching production traffic. Avoid migrating tasks where you cannot cheaply verify output quality - those are the ones where Fable 5's quality premium is most defensible. Routing by task type rather than trying to run a single model for everything is the pattern that holds up under real production conditions.
Sources#
- DeepSeek API official pricing documentation: api-docs.deepseek.com/quick_start/pricing
- TNW: "DeepSeek cuts V4-Pro prices by 75%" (April 27, 2026): thenextweb.com/news/deepseek-v4-pro-price-cut-75-percent
- WaveSpeed AI: "DeepSeek V4 Cost per Million Tokens: Full Calculator" (March 2, 2026): wavespeed.ai/blog/posts/deepseek-v4-cost-per-million-tokens/
- DeepSeek V4-Pro technical announcement and SWE-bench scores: platform.deepseek.com
- Hacker News: "DeepSeek V4 is out - the best open-source on coding. here's the breakdown"
Read next
How to Model Fable 5 Costs Before They Blow Up Your Budget
Claude Fable 5's $10/$50 per million token pricing can catch teams off guard - here is how to build a real cost model before you commit.
9 min readClaude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
Fable 5 lists at $10/$50 per million tokens - twice Opus 4.8. But list price is the wrong number. Here is the cost-per-outcome math that actually decides whether the upgrade pays.
8 min readWhat the 'Notes on DeepSeek' Essay Gets Right About Open-Weights Economics
A first-hand visit to DeepSeek HQ reveals something more interesting than benchmark scores: a 300-person company that treats AI as infrastructure, not eschatology - and what that means for API pricing everywhere.
7 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI ModelsOpen weights
DeepSeek V4
DeepSeek's open-weights frontier family, previewed April 24, 2026. V4-Pro is 1.6T total / 49B active params; V4-Flash is...
View ToolAI CodingOpen source
DeepSeek-TUI
Open-source terminal agent runtime with approval modes, rollback snapshots, MCP servers, LSP diagnostics, and a headless...
View ToolAI Models
DeepSeek
Open-source reasoning models from China. DeepSeek-R1 rivals o1 on math and code benchmarks. V3 for general use. Fully op...
View ToolAI Models
DeepSeek V3.2
DeepSeek's reasoning-first model built for agents. First model to integrate thinking directly into tool use. Ships along...
View ToolRelated Guides
Guide
Interactive Mode - Claude Code
Real-time prompt loop with history, completions, and multiline input.
Claude CodeGuide
Background Tasks - Claude Code
Run Bash commands with Ctrl+B and retrieve output by task ID.
Claude CodeGuide
Default Permission Mode - Claude Code
Approve each action manually - the safest mode for new tasks.
Claude CodeRelated Videos

DeepSeek v4 in 4 Minutes
DeepSeek V4: 1M Context, 10x KV Cache Savings, and Ultra-Low Pricing DeepSeek released V4, highlighting major long-context efficiency gains: at a 1M-token context, V4 Pro uses 27% of FLOPs and 10% of...
Video·

DeepSeek R1 0528 in 6 Minutes
In this video, we delve into the latest release of DeepSeek, version R1 0528. Despite the absence of an official model card or announcement, we cover the key features and benchmarks of this...
Video·

DeepSeek V3 0324 in 6 Minutes: Better than GPT 4.5 & Sonnet 3.7?
In this video, I'll dive into the latest update of DeepSeek's V3 model, recently released on Hugging Face. This model stands out for its impressive performance benchmarks, outclassing even...
Video·
Related Posts

9 min read
Claude
How to Model Fable 5 Costs Before They Blow Up Your Budget
Claude Fable 5's $10/$50 per million token pricing can catch teams off guard - here is how to build a real cost model be...

8 min read
Claude
Claude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
Fable 5 lists at $10/$50 per million tokens - twice Opus 4.8. But list price is the wrong number. Here is the cost-per-o...

7 min read
deepseek
What the 'Notes on DeepSeek' Essay Gets Right About Open-Weights Economics
A first-hand visit to DeepSeek HQ reveals something more interesting than benchmark scores: a 300-person company that tr...

9 min read
deepseek
DeepSeek V4 Economics: The Cost-Quality Frontier for Agentic Coding in 2026
DeepSeek V4 Pro lands a 63.5 on SWE-bench Verified at $0.435/$0.87 per million tokens, and Flash runs agent inner loops...

11 min read
pricing
Self-Hosting Open-Weights Models: The Real Break-Even Math
Open weights are free to download, but inference is not free to run. Here is the honest break-even math on when self-hos...
12 min read
open-weights
GLM-5.2 vs DeepSeek V4 vs Qwen3: The Open-Weights Coding Model Showdown (2026)
A data-rich, source-cited comparison of the three open-weights coding models that matter in 2026: GLM-5.2, DeepSeek V4,...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever