The Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap Workers
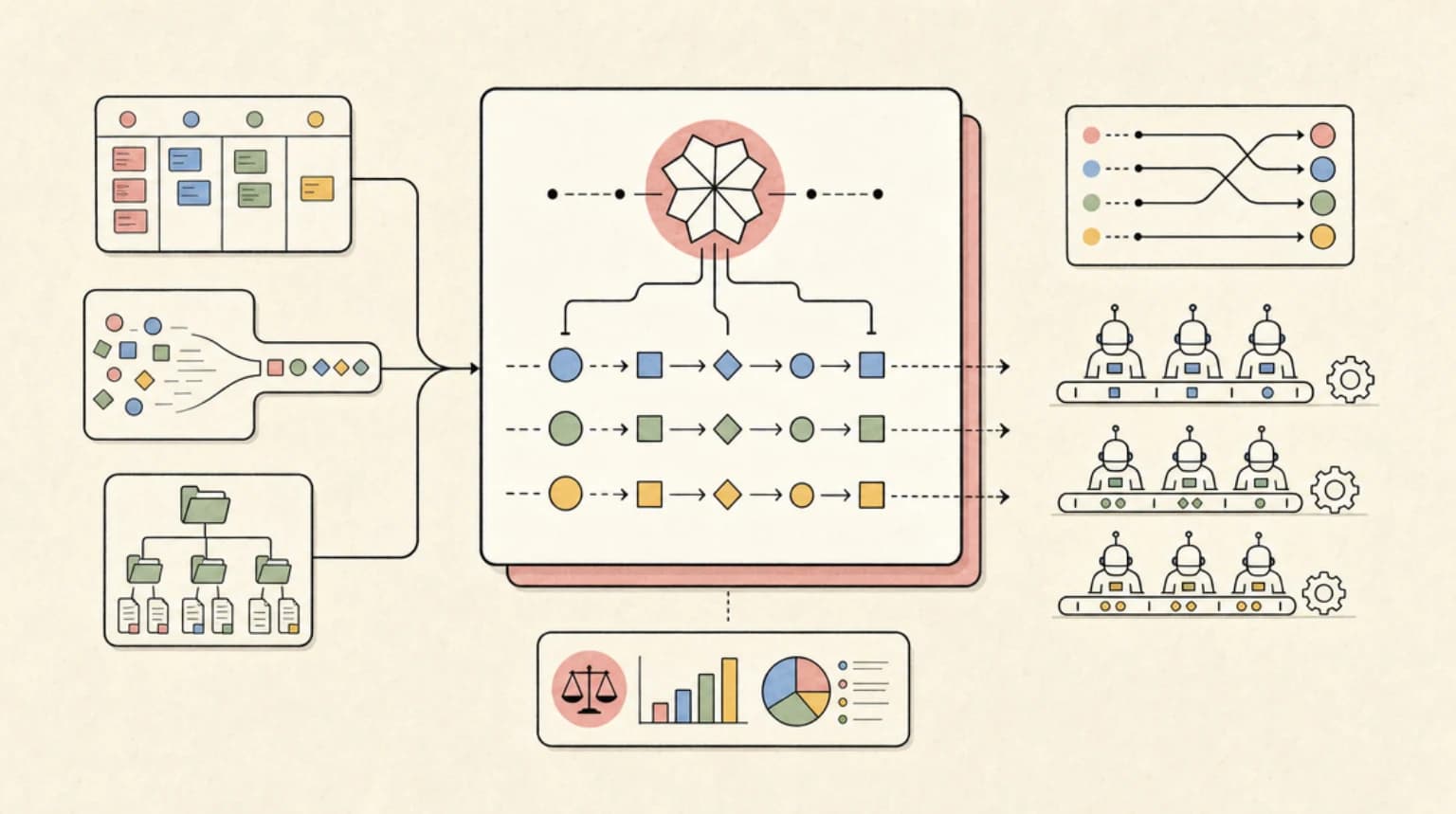
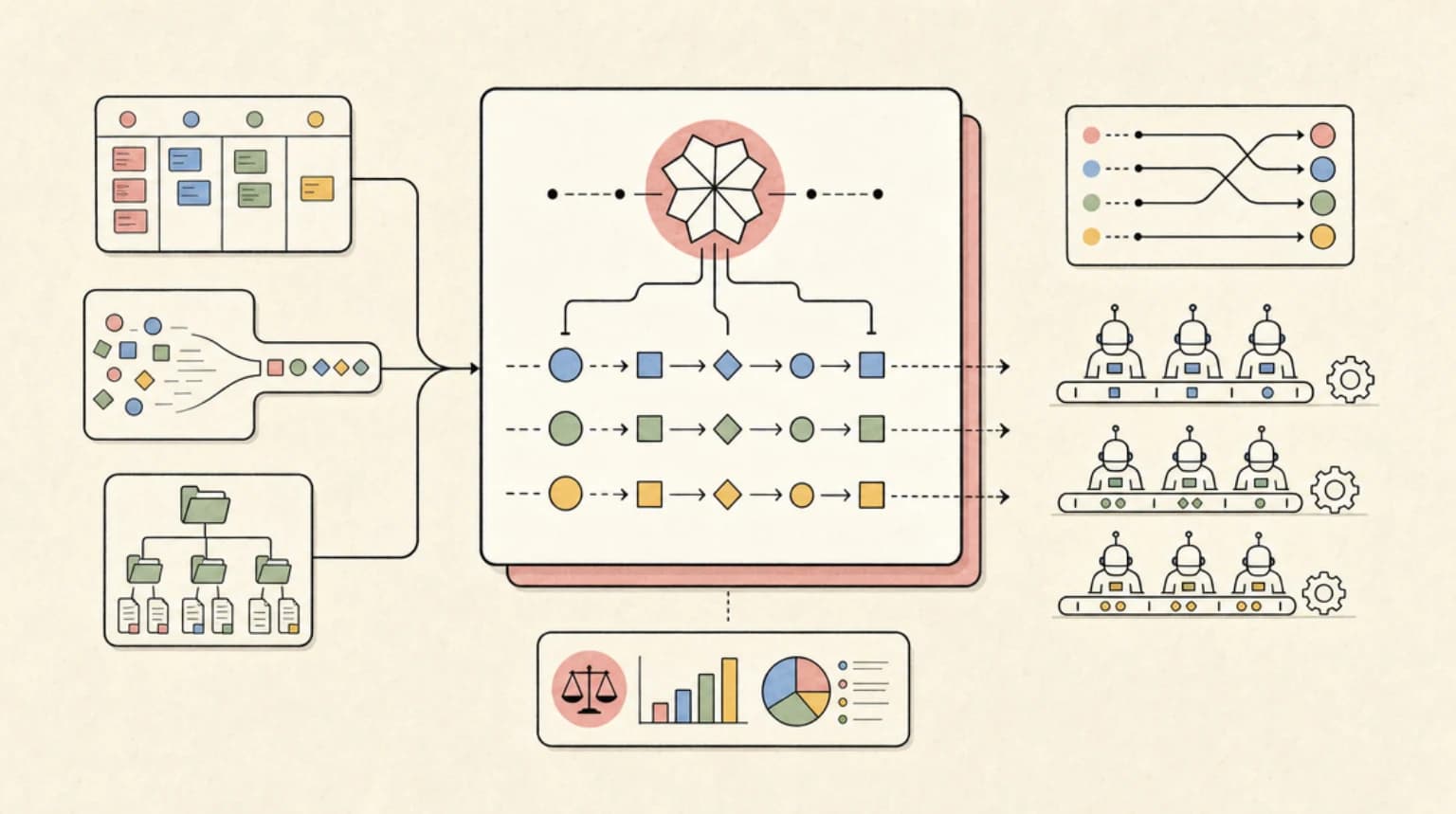
The Fable 5 Moment
31 parts- 1Claude Mythos 5 Explained: What It Is, Who Can Access It, and Why It's Gated
- 2Migrating to Claude Fable 5: The Practical Guide
- 3Fable 5 Leaves Your Claude Plan on June 22. Here's How to Plan for It
- 4Claude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
- 5Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
- 6Claude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
- 7How to Model Fable 5 Costs Before They Blow Up Your Budget
- 8Claude Fable 5 API: Production Integration Patterns, Rate Limits, and Migration Gotchas
- 9Handling Fable 5 Refusals: A Working Guide to the Fallback API
- 10Why Fable 5 Refuses Your Cybersecurity Queries (And How the Fallback Works)
- 11Fable 5's Hidden Guardrails: What Developers Need to Know About Silent Degradation
- 12Fable 5 Broke Enterprise ZDR Agreements: What Dev Teams Must Do Now
- 13Claude Managed Agents: Dreaming, Outcomes, and Multi-Agent Orchestration Explained
- 14Claude Managed Agents Public Beta: What's Actually Available vs What's Gated
- 15Dario Amodei Wants FAA-Style AI Regulation: Open Questions for Developers
- 16The Exponential and the Working Developer: Sitting With Amodei's Hardest Questions
- 17The Dario Paradox: Warning About the Exponential While Shipping It
- 18The Pushback on Amodei's Exponential Essay: Too Slow, Too Convenient, or About Right?
- 19Fable 5 Before June 22: The Decision Checklist for Every Plan Tier
- 20Fable 5 on AWS Bedrock: When Your Data Leaves the AWS Boundary
- 21Why Claude Desktop Quietly Installs a 1.8 GB VM on Windows (And What You Can Do About It)
- 22Decoding Anthropic's Model Names: Fable, Mythos, and What the Naming Shift Signals
- 23Managed Agents vs LangGraph vs Rolling Your Own: Who Should Run Your Agent Loop in 2026
- 24How Claude's Usage Limits Actually Work With Fable 5: Windows, Multipliers, and Burn Rates
- 25Fable 5 for Government and Regulated Teams: The GovCloud Question
- 26Fable 5 vs DeepSeek V4: The Cost-Quality Gap Measured in Real Tasks
- 27The Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap WorkersCurrent
- 28Prompt Caching Economics on Fable 5: When the 5-Minute TTL Pays
- 29Fable 5 with 1M Context: What Actually Works in Practice
- 30Fable 5 Effort Levels Explained: low to xhigh, and What They Cost You
- 31Recursive Self-Improvement: What Fable 5, Dario's Essay, and Anthropic's Own Data Actually Tell Us
TL;DR
A practical playbook for running Claude Fable 5 as the orchestrator over Sonnet and Haiku workers, with verified cost math on when the premium pays off.
Last updated: June 11, 2026
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens - double Opus 4.8 and ten times Haiku 4.5, per Anthropic's pricing page. Pointing it at every task in a multi-agent fleet is the fastest way to turn a useful model into a budget problem. But one seat consistently earns the premium: the orchestrator.
Anthropic's own Fable 5 prompting guide calls out delegation as a headline improvement: Fable 5 is "significantly more dependable at dispatching and sustaining parallel subagents, and reliably manages ongoing communication with long-running subagents and peer agents." That is the orchestrator job description. This playbook covers putting Fable 5 in that seat, routing the actual work to Sonnet and Haiku, and the math on when that beats both an all-frontier fleet and an all-cheap one.
Why One Smart Model at the Top#
In any fan-out architecture, the orchestrator makes the decisions that compound: how to decompose the task, which worker gets which slice, and what to do when results conflict. A planning mistake at the top multiplies across every worker downstream. A worker mistake stays local and is cheap to retry.
That asymmetry is the whole argument. You pay the frontier rate where errors compound and the commodity rate where they do not. Anthropic's own cost optimization guidance says it plainly: "Choose Haiku for simple tasks, Sonnet for most production workloads, and Opus for the most complex reasoning." Fable 5 now sits above Opus in that last bucket, and the launch announcement claims "the longer and more complex the task, the larger Fable 5's lead over our other models." Orchestration runs are exactly that profile. If you have not picked a top-tier model yet, our Fable 5 vs Opus 4.8 decision guide covers the head-to-head.
The Three-Tier Routing Table#
Verified pricing and specs from the models overview and pricing docs, accessed June 11, 2026:
| Tier | Model | Input / Output per MTok | Context | Best for |
|---|---|---|---|---|
| Orchestrator | Fable 5 | $10 / $50 | 1M | Decomposition, dispatch, conflict resolution, final synthesis |
| Escalation | Opus 4.8 | $5 / $25 | 1M | Hard worker tasks, plus anything in Fable's safeguarded domains |
| Workhorse | Sonnet 4.6 | $3 / $15 | 1M | Implementation legs: edits, tests, multi-file changes |
| Scout | Haiku 4.5 | $1 / $5 | 200K | Search, classification, summarization, read-only exploration |
Three constraints worth internalizing before you wire this up:
- Haiku's context is 200K, not 1M. Workers holding a large repo slice belong on Sonnet 4.6, which gets the full 1M window at standard rates now that Anthropic has dropped the long-context premium.
- Fable 5 and Opus 4.8 share a newer tokenizer that can produce up to 35% more tokens for the same text than pre-Opus-4.7 models, per the pricing docs, so the orchestrator's real share of spend runs slightly higher than naive per-MTok math suggests.
- Fable 5 turns run long. The prompting guide warns individual requests "can run for many minutes at higher effort settings." Check on the orchestrator asynchronously rather than blocking on it.
Worked Example: A 12-Worker Codebase Audit#
Assume a quality audit fanned out across 12 workers. The orchestrator reads the task, a repo map, and all worker summaries (150K input) and produces dispatch briefs plus a final report (20K output). Each worker reads a 60K slice and returns an 8K summary. The volumes are illustrative assumptions; the per-token prices are verified.
Orchestrator on Fable 5: 150K x $10/M + 20K x $50/M = $1.50 + $1.00 = $2.50
Worker fleet, per configuration:
| Configuration | Per worker | 12 workers | Run total |
|---|---|---|---|
| All Fable 5 (workers too) | $1.00 | $12.00 | $14.50 |
| Fable 5 + Opus 4.8 workers | $0.50 | $6.00 | $8.50 |
| Fable 5 + Sonnet 4.6 workers | $0.30 | $3.60 | $6.10 |
| Fable 5 + Haiku 4.5 workers | $0.10 | $1.20 | $3.70 |
| All Sonnet 4.6 (orchestrator too) | $0.30 | $3.60 | $4.35 |
Two readings of that table matter:
The leverage is in the worker tier. Downgrading the orchestrator from Fable 5 to Sonnet saves $1.75. Downgrading the workers saves $8.40. The mixed fleet runs 58% cheaper than all-Fable, and Fable-plus-Haiku runs 74% cheaper. The expensive seat worth keeping is the one that decides what everyone else does.
The orchestrator premium is small in absolute terms. Going from all-Sonnet to Fable-at-the-top costs $1.75 extra on this run. If a smarter decomposition saves one botched worker pass and the human time to notice it, it has paid for itself. If your fan-outs are trivially parallel with no judgment calls (lint 500 files, summarize 200 tickets), the premium buys nothing - keep Sonnet or Haiku in charge and batch it.
Prompt caching tightens this further. Cache reads bill at 0.1x base input, with 5-minute writes at 1.25x. If 40K of each worker's 60K input is a shared prefix (conventions doc, repo map), the Sonnet worker fleet's input cost drops from $2.16 to about $1.00, taking the mixed-fleet run from $6.10 to roughly $4.94. The prompting guide also notes long-lived subagents "save time and cost through cache reads" - reuse workers across subtasks instead of cold-starting them. For deeper modeling, see Fable 5 production cost modeling and our cost-per-task analysis.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Prompt Caching Economics on Fable 5: When the 5-Minute TTL Pays
Jun 11, 2026 • 10 min read
Fable 5 Task Budgets: Capping Agent Spend Before It Happens
Jun 11, 2026 • 8 min read
Frontier Model API Pricing, July 2026: Claude vs OpenAI vs Gemini vs DeepSeek
Jun 11, 2026 • 11 min read
The Frontier Model Landscape, June 2026 Edition
Jun 11, 2026 • 10 min read
Wiring It Up in Claude Code#
The routing primitives are first-class in Claude Code. Per the subagents docs, every subagent definition takes a model field accepting sonnet, opus, haiku, fable, a full model ID, or inherit (the default):
Markdown
---
name: code-scout
description: Read-only repo exploration and file discovery
tools: Read, Glob, Grep
model: haiku
---
You search and summarize. Return file paths, signatures, and a short
summary. Never edit.
Run the main session on Fable 5 and it becomes the orchestrator by default; every subagent runs on whatever its definition pins. Claude Code's built-in Explore subagent already follows this pattern - it is pinned to Haiku for fast, read-only codebase search.
For bigger fan-outs, dynamic workflows move the orchestration loop into a script with hard caps of 16 concurrent agents and 1,000 agents per run. The docs are explicit about the routing lever: "Every agent in a workflow uses your session's model unless the script routes a stage to a different one." A scout stage on Haiku, an implementation stage on Sonnet, and a synthesis stage on the session's Fable 5 is the natural shape.
Three operating rules from the official guidance worth adopting:
- Prefer async dispatch. The prompting guide says to "prefer asynchronous communication between orchestrator and subagents over blocking until each subagent returns" - otherwise the run bottlenecks on the slowest worker.
- Verify with fresh contexts. Per the same guide, "separate, fresh-context verifier subagents tend to outperform self-critique." A Sonnet verifier checking a Sonnet implementer is cheap insurance.
- Escalate on failure, not by default. Start each worker on the cheapest plausible tier and re-run failures one tier up. Two Haiku failures re-run on Sonnet cost an extra $0.60 in the example above.
For the broader taxonomy of these structures, see our seven AI agent orchestration patterns breakdown.
The Refusal Wrinkle Nobody Plans For#
Fable 5 ships with safety classifiers covering offensive cybersecurity, biology and life sciences, and reasoning extraction. Per the introduction doc, a declined request returns stop_reason: "refusal" as an HTTP 200, and the launch post reports classifiers trigger, on average, in under 5% of sessions. For an orchestrator this matters twice:
- Route safeguarded worker types around Fable entirely. The prompting guide warns benign cybersecurity and life-sciences work "may also trigger these safeguards." Pin a security-scanning worker to Opus 4.8 from the start rather than eating refusal-and-retry latency.
- Audit scaffolding for reasoning-echo instructions. Prompts telling the model to transcribe its internal reasoning can trip the
reasoning_extractioncategory and elevate fallbacks. Orchestrator templates that ask workers to "show your full reasoning" are a common offender.
The billing is forgiving: pre-output refusals are not billed, and the fallback credit refunds the prompt-cache cost of switching models on retry, with the beta fallbacks parameter handling retries server-side. Full mechanics in Fable 5's safeguards and refusal architecture.
One more operational note: Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans only through June 22, 2026, then moves behind usage credits, per the launch post. If your orchestrator runs on a subscription seat today, the math above becomes your real bill in under two weeks - see our June 22 deadline explainer.
When to Skip the Premium Entirely#
Honest tradeoffs, because the orchestrator pattern is not free lunch:
- Shallow fan-outs do not need Fable. If the plan is obvious and workers are independent, an all-Sonnet fleet at $4.35 beats the mixed fleet at $6.10 with no quality difference where it counts.
- Compliance can be a hard blocker. Fable 5 carries mandatory 30-day data retention and is not available under zero data retention. If your org requires ZDR, Opus 4.8 takes the orchestrator seat and the same playbook applies at half the rate.
- Latency-sensitive pipelines suffer. Fable 5's long deliberation is a feature for overnight audits and a liability for interactive loops.
- Token burn scales with ambition. A workflow that can spawn 1,000 agents will happily spend your whole budget. Pilot on a small slice first - the workflows docs recommend exactly that, and the per-agent token view in
/workflowslets you stop a run before it gets expensive.
FAQ#
What is the Fable 5 orchestrator pattern?#
A tiered multi-agent setup where Claude Fable 5 handles planning, decomposition, dispatch, and synthesis, while cheaper models (Sonnet 4.6 for implementation, Haiku 4.5 for search and classification) execute the work items. You pay the $10/$50 frontier rate only on the decisions that compound.
How much does a Fable 5 orchestrator with Sonnet workers save versus all-Fable?#
In the worked example above, the mixed fleet costs $6.10 versus $14.50 for all-Fable - about 58% less. With Haiku workers it drops to $3.70, about 74% less. Prompt caching on shared worker prefixes cuts the mixed-fleet total further, to roughly $4.94.
How do I pin different Claude Code subagents to different models?#
Set the model field in each subagent's YAML frontmatter to haiku, sonnet, opus, fable, a full model ID, or inherit. The default is inherit, so an unconfigured fleet under a Fable 5 session silently bills everything at Fable rates.
Why not use Opus 4.8 as the orchestrator instead?#
Opus 4.8 at $5/$25 is the right call when zero data retention is required (Fable 5 carries mandatory 30-day retention), when your workload would hit Fable's classifiers, or when run plans are simple enough that Fable's documented delegation improvements do not change outcomes. The premium is small in absolute dollars, but it should still buy something.
Do refused Fable 5 requests cost money?#
Not if the refusal happens before output generation - per Anthropic's docs you are not billed for pre-output refusals, and the fallback credit refunds the prompt-cache cost of retrying on another model. Configure the server-side fallbacks parameter (beta) or SDK middleware so refusals retry on Opus 4.8 automatically.
Sources#
- Anthropic pricing docs - model pricing, caching multipliers, batch, cost optimization (accessed June 11, 2026)
- Claude models overview - specs, context windows, GA dates (accessed June 11, 2026)
- Claude Code subagents - model field, built-in Explore agent, frontmatter (accessed June 11, 2026)
- Claude Code dynamic workflows - agent caps, per-stage model routing, cost controls (accessed June 11, 2026)
- Introducing Claude Fable 5 and Claude Mythos 5 - refusals, fallback, billing, retention (accessed June 11, 2026)
- Prompting Claude Fable 5 - delegation, parallel subagents, effort, safeguard triggers (accessed June 11, 2026)
- Anthropic launch announcement - pricing, fallback rate, June 22 subscription window, Stripe example (accessed June 11, 2026)
Read next
Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
Fable 5 posts an 80.3% SWE-Bench Pro score and costs 2x Opus 4.8 - here is the task-profile scoring guide that tells you when the premium pays off.
7 min readFable 5 with 1M Context: What Actually Works in Practice
Fable 5 1M context workflows that actually work: whole-repo reviews, log archaeology, multi-doc synthesis - plus the honest math on when RAG still wins.
10 min readFable 5 Effort Levels Explained: low to xhigh, and What They Cost You
Fable 5 effort levels explained: what low, medium, high, xhigh, and max actually change, which models support each level, and how effort drives your token bill.
10 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI ModelsNew
Claude Fable 5
Anthropic's first generally available Mythos-class model, released June 9, 2026. 1M context, 128K max output, $10/$50 pe...
View ToolAI ModelsDaily Driver
Claude
Anthropic's AI. Opus 4.6 for hard problems, Sonnet 4.6 for speed, Haiku 4.5 for cost. 200K context window. Best coding m...
View ToolAI Models
OpenRouter
Unified API for 200+ models. One API key, one billing dashboard. OpenAI, Anthropic, Google, Meta, Mistral, and more. Aut...
View ToolAI Models
Claude Haiku 4.5
Anthropic's smallest Claude 4.5 model. Near-frontier coding performance at one-third the cost of Sonnet 4 and up to 4-5x...
View ToolApps from Developers Digest
Related Guides
Guide
Run AI Models Locally with Ollama and LM Studio
Install Ollama and LM Studio, pull your first model, and run AI locally for coding, chat, and automation - with zero cloud dependency.
Getting StartedGuide
Model Aliases - Claude Code
Use opus, sonnet, haiku, and best to switch models easily.
Claude CodeGuide
Model Picker (/model) - Claude Code
Interactive UI to switch models and effort sliders mid-session.
Claude CodeRelated Videos

Anthropic's New Model Context Protocol in 10 Minutes
Learn The Fundamentals Of Becoming An AI Engineer On Scrimba; https://v2.scrimba.com/the-ai-engineer-path-c02v?via=developersdigest Anthropic's New Model Context Protocol (MCP): AI Data Integratio...
Video·

LLAMA 3: Set to Rival Top AI Models
Introducing Meta Llama 3: The most capable openly available LLM to date Meta has released two groundbreaking AI models under the Lama 3 series, an 8 billion parameter model and a 70 billion...
Video·

Together.AI: The Cloud Platform For Building and Running Generative AI Models
In this video, I explore Together AI which is an AI cloud platform that also you to both easily access apis for a ton of open source models such as the llama-2 models, mistral 7b, stable diffusion...
Video·
Related Posts
7 min read
AI Models
Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
Fable 5 posts an 80.3% SWE-Bench Pro score and costs 2x Opus 4.8 - here is the task-profile scoring guide that tells you...
8 min read
Fable 5
Running Fable 5 Agent Fleets in Production: The Operations Guide
Standing up a fleet of Fable 5 agents is the easy part. This is the operations layer - data retention rules, refusal-rat...
8 min read
Fable 5
Fable 5 vs Opus 4.8: Which Should Orchestrate Your Agents?
The orchestrator is the most important model choice in an agent fleet. A fair head-to-head between Fable 5 and Opus 4.8...
8 min read
Anthropic
The Claude Tokenizer Change: What ~30% More Tokens Means for Your Bill
Anthropic's docs say the tokenizer introduced with Opus 4.7 can use up to 35% more tokens for the same text. Here is wha...
10 min read
AI Models
Fable 5 with 1M Context: What Actually Works in Practice
Fable 5 1M context workflows that actually work: whole-repo reviews, log archaeology, multi-doc synthesis - plus the hon...
10 min read
Anthropic
Fable 5 Effort Levels Explained: low to xhigh, and What They Cost You
Fable 5 effort levels explained: what low, medium, high, xhigh, and max actually change, which models support each level...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever