Why Fable 5 Refuses Your Cybersecurity Queries (And How the Fallback Works)
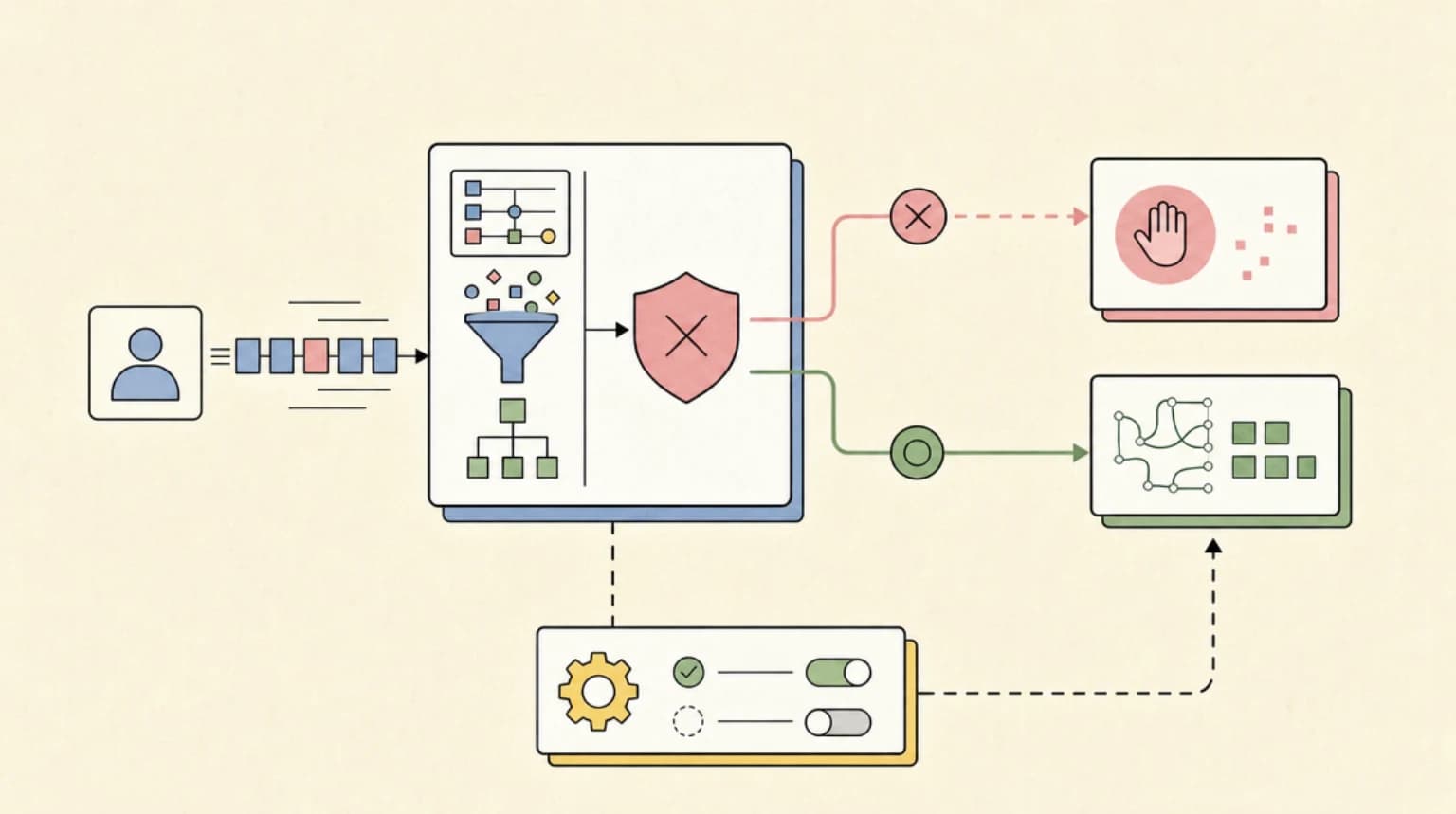
The Fable 5 Moment
31 parts- 1Claude Mythos 5 Explained: What It Is, Who Can Access It, and Why It's Gated
- 2Migrating to Claude Fable 5: The Practical Guide
- 3Fable 5 Leaves Your Claude Plan on June 22. Here's How to Plan for It
- 4Claude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
- 5Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
- 6Claude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
- 7How to Model Fable 5 Costs Before They Blow Up Your Budget
- 8Claude Fable 5 API: Production Integration Patterns, Rate Limits, and Migration Gotchas
- 9Handling Fable 5 Refusals: A Working Guide to the Fallback API
- 10Why Fable 5 Refuses Your Cybersecurity Queries (And How the Fallback Works)Current
- 11Fable 5's Hidden Guardrails: What Developers Need to Know About Silent Degradation
- 12Fable 5 Broke Enterprise ZDR Agreements: What Dev Teams Must Do Now
- 13Claude Managed Agents: Dreaming, Outcomes, and Multi-Agent Orchestration Explained
- 14Claude Managed Agents Public Beta: What's Actually Available vs What's Gated
- 15Dario Amodei Wants FAA-Style AI Regulation: Open Questions for Developers
- 16The Exponential and the Working Developer: Sitting With Amodei's Hardest Questions
- 17The Dario Paradox: Warning About the Exponential While Shipping It
- 18The Pushback on Amodei's Exponential Essay: Too Slow, Too Convenient, or About Right?
- 19Fable 5 Before June 22: The Decision Checklist for Every Plan Tier
- 20Fable 5 on AWS Bedrock: When Your Data Leaves the AWS Boundary
- 21Why Claude Desktop Quietly Installs a 1.8 GB VM on Windows (And What You Can Do About It)
- 22Decoding Anthropic's Model Names: Fable, Mythos, and What the Naming Shift Signals
- 23Managed Agents vs LangGraph vs Rolling Your Own: Who Should Run Your Agent Loop in 2026
- 24How Claude's Usage Limits Actually Work With Fable 5: Windows, Multipliers, and Burn Rates
- 25Fable 5 for Government and Regulated Teams: The GovCloud Question
- 26Fable 5 vs DeepSeek V4: The Cost-Quality Gap Measured in Real Tasks
- 27The Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap Workers
- 28Prompt Caching Economics on Fable 5: When the 5-Minute TTL Pays
- 29Fable 5 with 1M Context: What Actually Works in Practice
- 30Fable 5 Effort Levels Explained: low to xhigh, and What They Cost You
- 31Recursive Self-Improvement: What Fable 5, Dario's Essay, and Anthropic's Own Data Actually Tell Us
TL;DR
Claude Fable 5 routes blocked queries to Opus 4.8 rather than refusing outright - but the fallback is not automatic for API users and requires explicit configuration. Here is the complete developer guide to the refusal architecture.
On June 9, 2026, Anthropic released Claude Fable 5 - the first Mythos-class model made available for general use. The model is, by benchmark, the most capable model Anthropic has ever publicly shipped. It is also the first Anthropic model to launch with a built-in fallback routing system: when its classifiers detect a query on certain sensitive topics, the request is silently handed off to Claude Opus 4.8 and the user is notified.
For most users that will be invisible. For developers building applications in cybersecurity, life sciences, or research tooling - and for any team whose prompts happen to brush against the classifiers - understanding the architecture is not optional. This post unpacks what gets blocked, how the fallback actually works at the API level, and what you need to configure before shipping to production.
Last updated: June 10, 2026
What Gets Blocked: The Three Classifier Categories#
Anthropic's announcement is direct about the scope. Three categories trigger the fallback classifiers:
1. Cybersecurity - The classifiers cover both narrow exploit development and broader offensive cyber tasks: reconnaissance, lateral movement, defense evasion, and agentic hacking scenarios. Anthropic tested Fable 5 on Firefox exploit discovery, OSS-Fuzz vulnerability research, and CyberGym and CyScenarioBench challenges. With classifiers active, Fable 5 makes no progress on these tasks - responses are routed to Opus 4.8 instead.
2. Biology and chemistry - Earlier Claude models only blocked a narrow set of bioweapons-adjacent queries. Fable 5 extends this to most biology and chemistry requests. Anthropic explains the expansion: Mythos-class models can now complete tasks - like predicting adeno-associated virus shell assembly properties - that previously required specialized protein language models. The same capability that accelerates legitimate gene therapy research could, in the wrong hands, inform dangerous viral design. Because the risk is dual-use, the safeguard is broad.
3. Distillation - Requests that the classifiers identify as attempts to systematically extract Claude's capabilities to train competing models are also routed away. Anthropic has previously documented large-scale distillation attacks from adversarial actors and treats Fable 5's weights as too valuable to expose through model extraction.
| Category | Scope | Fallback target |
|---|---|---|
| Cybersecurity | Exploit dev, offensive ops, agentic hacking | Claude Opus 4.8 |
| Biology & chemistry | Broad - most bio/chem queries, not just bioweapons | Claude Opus 4.8 |
| Distillation | Systematic capability extraction attempts | Claude Opus 4.8 |
The Less-Than-5% Claim vs. What Practitioners Are Seeing#
Anthropic states that fewer than 5% of Fable 5 sessions involve any fallback and that the model will "sometimes catch harmless requests." The company is explicit that this is intentional: safeguards were tuned conservatively to prioritize safety over user experience at launch, with a plan to reduce false positives over time.
Early user reports suggest the 5% figure is accurate for general use but understates the problem for practitioners in adjacent fields. Security researchers writing documentation about vulnerability classes, developers building penetration testing tools, and bioinformatics teams using the API for legitimate research are hitting fallbacks at a higher rate than the aggregate statistic implies.
Andrej Karpathy, in his launch-day commentary cited by TrueFoundry's technical breakdown, flagged that the classifiers are "configured to be a little too trigger happy" - consistent with Anthropic's own framing that the current tuning is "stricter than would be ideal."
For developers, the practical implication is: do not assume that a non-malicious prompt will never trigger a fallback. Test your actual workload against the classifiers before shipping.
How the Fallback Works: Fable 5 Routes to Opus 4.8#
When a classifier triggers, the system does not return an error or a refusal message. Instead, the request is answered by Claude Opus 4.8. The user is informed that this has happened. Anthropic frames this as a feature: a response from Opus 4.8 is materially better than an outright refusal.
From a user perspective that is largely true - you still get an answer. From a developer perspective, there are several implications that are not obvious from the consumer-facing experience.
Critical point for API developers: The fallback is not fully automatic at the API level the way it is in Claude.ai. TrueFoundry's API guide confirms that "API customers must configure Anthropic's new Fallback API" - it does not happen transparently unless you wire it up. If you are calling claude-fable-5 directly and a classifier triggers, your application needs to handle the response correctly rather than assuming all responses come from Fable 5.
Additional mechanics worth noting:
- You are not charged Fable 5 pricing for requests that fall back to Opus 4.8
- All Mythos-class traffic is subject to a 30-day data retention policy for safety monitoring - this applies whether or not a fallback occurs
- Retained data is not used for model training, only safety analysis
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Fable 5 vs DeepSeek V4: The Cost-Quality Gap Measured in Real Tasks
Jun 10, 2026 • 7 min read
Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
Jun 10, 2026 • 7 min read
Factory AI and the Model Routing Era: How Coding Agents Are Learning to Spend Your Tokens Wisely
Jun 10, 2026 • 8 min read
Factory Droid: Review and Setup Guide (2026)
Jun 10, 2026 • 8 min read
Configuring the Fallback API: Detection, Logging, and Consistent Routing#
If you are building a production application on Fable 5, the fallback behavior needs to be part of your architecture from day one. Here is the practical setup:
Detecting fallback events. The API response will indicate when a fallback occurred. Build detection into your response handling layer so you can distinguish Fable 5 responses from Opus 4.8 responses. Do not assume response model identity based on the model string you sent in the request.
Logging fallback events. Because fallbacks affect output quality (Opus 4.8 is excellent but meaningfully below Fable 5 on complex long-horizon tasks), you want to track which requests are being rerouted. A request that falls back consistently is a signal that your prompt or use case is landing in a classifier boundary - you may need to restructure the query or route that workload to Mythos 5 through the trusted access program instead.
Consistent routing for users. If your application handles both general queries and security or research queries, consider explicit routing logic rather than relying solely on Fable 5's classifiers to sort traffic. Send security-adjacent queries through a known pathway with appropriate expectations set for the user, rather than having the classifier decide unpredictably.
A gateway approach. As TrueFoundry notes, an AI gateway sitting between your application and the model API lets you log fallback events centrally, apply per-team or per-application rate limits, and manage the 30-day retention requirement alongside your broader data governance policy. At $10/$50 per million tokens for input/output, Fable 5 is expensive enough that routing control has direct cost implications.
Mythos 5 vs. Fable 5: What Project Glasswing Gets#
Fable 5 and Mythos 5 are the same underlying model - Anthropic states this explicitly. The name difference reflects the safeguard configuration, not different weights. (The naming traces to Latin: fabula and the Greek mythos share etymology. The safeguards are what distinguish them.)
Mythos 5 has cybersecurity safeguards lifted. It is currently restricted to partners in Project Glasswing - a program operated in collaboration with the US government for vetted cyberdefenders and critical infrastructure providers. Glasswing partners who had access to Mythos Preview were able to upgrade to Mythos 5 on launch day at significantly lower prices ($10/$50 per million tokens vs. Mythos Preview's previous pricing).
Anthropic plans to expand access through two channels:
- Cybersecurity trusted access - Periodic expansion of Project Glasswing to additional vetted organizations, continuing the existing periodic addition of partners
- Biology trusted access - A separate program that lifts bio/chemistry safeguards while keeping cyber safeguards active, aimed at life science organizations for fundamental and translational research
General API users do not currently have a path to Mythos 5 access. The trusted access programs are by application and consultation with the US government for the cyber track.
Developer Workflow: Graceful Handling of Safeguard Triggers#
A practical checklist for any team building on Fable 5:
-
Test your prompts against the classifiers before launch. Run your production prompt suite through Fable 5 and log which responses indicate a fallback. Tune prompts that are triggering unnecessarily.
-
Set user expectations. If your application touches biology, security, or research domains, tell users upfront that some queries will be answered by Opus 4.8 rather than Fable 5. The notification is generated by the system, but framing it in your UX prevents confusion.
-
Do not benchmark Fable 5 on restricted categories. The published benchmark scores for cybersecurity and bio tasks reflect Mythos 5 performance. TrueFoundry's breakdown explicitly flags this: the starred benchmark rows are Mythos 5 scores, and Fable 5 with safeguards active performs closer to Opus 4.8 on those tasks. Do not quote those numbers as Fable 5 capabilities.
-
Account for the 30-day retention policy in your data governance. If your enterprise has data residency or retention constraints, the Mythos-class retention requirement is non-negotiable for Fable 5 and Mythos 5. US-only inference is available at 1.1x pricing if you need data residency controls.
-
Model your cost with fallback traffic in mind. Fallback requests are charged at Opus 4.8 rates, not Fable 5 rates. If a meaningful percentage of your traffic falls back, your actual cost profile will be a blend of both price points.
The Censorship Debate: Researcher Perspectives vs. Anthropic's Rationale#
The decision to broadly restrict biology and chemistry - not just narrow bioweapons queries - has drawn criticism from researchers who argue that legitimate scientific work is being collateral damage in a policy aimed at a small number of bad actors.
Ars Technica's coverage captures the tension directly: "the same queries that are beneficial in the hands of cybersecurity professionals and biology researchers could be dangerous if available to malicious actors." Anthropic acknowledges this is a hard tradeoff and that the current tuning is "stricter than would be ideal."
Anthropic's rationale for the breadth of the bio/chem classifier is grounded in a specific capability demonstration: Mythos-class models, without domain-specific training, can now match dedicated protein language models on viral assembly prediction tasks. That crosses a threshold the company had not previously hit, and the conservative response was to widen the classifier scope while the trusted access program catches up.
Security professionals face a similar friction. The cybersecurity community depends on offensive research for defensive purposes - writing exploit code, analyzing malware, studying attack techniques. Fable 5's classifiers do not distinguish between a pen tester documenting a vulnerability class and an attacker using the same query for active exploitation.
Anthropic's answer to that problem is Mythos 5 and the trusted access program - but the program is currently limited in scope, collaborative with government, and not available on a self-serve basis. For the majority of legitimate security researchers, the path to full Mythos 5 capability remains narrow.
FAQ#
Does Fable 5 tell you when it falls back to Opus 4.8?#
Yes. Anthropic's announcement states that users are informed whenever the fallback occurs. The notification is generated by the system and visible in the response.
Are fallback requests charged at Fable 5 prices?#
No. Requests that are routed to Opus 4.8 by the classifiers are charged at Opus 4.8 rates, not Fable 5 rates.
Can I get access to Mythos 5 as an API developer?#
Not through a standard API application currently. Mythos 5 access is restricted to Project Glasswing partners for cybersecurity capabilities and a forthcoming biology trusted access program for life science researchers. Both tracks involve vetting and, for the cyber track, consultation with the US government.
What is the 30-day data retention requirement?#
All traffic on Mythos-class models - including Fable 5 - is retained for 30 days for safety monitoring purposes. Anthropic states this data is not used for model training and that human access to retained data is logged. Retention applies on both first- and third-party surfaces.
Will the false positive rate improve over time?#
Anthropic has explicitly committed to reducing false positives. The current conservative tuning was chosen to prioritize safety at launch. The company says it will "narrow these safeguards as soon as possible" and is actively working to improve classifier precision after release.
Is the Fable 5 fallback automatic at the API level?#
Not fully. TrueFoundry's API guide notes that API customers need to configure the Fallback API explicitly - it does not operate transparently at the API layer the way it does in Anthropic's own Claude.ai product. You need to handle fallback responses in your application code.
Official Sources#
Read next
Claude Mythos 5 Explained: What It Is, Who Can Access It, and Why It's Gated
Anthropic shipped two names for one architecture on June 9, 2026. Here is what separates Fable 5 from Mythos 5, who can actually get unrestricted access, and what developers should do right now.
7 min readClaude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
Fable 5 launched June 9 at 2x GPT-5.5's price with a 22-point SWE-Bench Pro gap. Here is the decision framework for choosing between them.
7 min readClaude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
Fable 5 lists at $10/$50 per million tokens - twice Opus 4.8. But list price is the wrong number. Here is the cost-per-outcome math that actually decides whether the upgrade pays.
8 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI CodingDaily Driver
Claude Code
Anthropic's agentic coding CLI. Runs in your terminal, edits files autonomously, spawns sub-agents, and maintains memory...
View ToolAI Models
OpenRouter
Unified API for 200+ models. One API key, one billing dashboard. OpenAI, Anthropic, Google, Meta, Mistral, and more. Aut...
View ToolAI Models
Claude Opus 4.7
Anthropic's flagship reasoning model. Best-in-class for coding, long-context analysis, and agentic workflows. 1M token c...
View ToolAI ModelsNew
Claude Fable 5
Anthropic's first generally available Mythos-class model, released June 9, 2026. 1M context, 128K max output, $10/$50 pe...
View ToolApps from Developers Digest
Developer ToolsPlus $20/mo
Skills Pro
Unlock pro skills and share private collections with your team.
View AppDeveloper ToolsIn Progress
SkillForge CI
Catch broken SKILL.md files in CI before they hit your team.
View AppDeveloper Tools
Agent Hub
Every coding agent in one window. Stop alt-tabbing between Claude, Codex, and Cursor.
View AppRelated Guides
Guide
Routines (Web) - Claude Code
Managed scheduling on Anthropic infrastructure with API and GitHub triggers.
Claude CodeGuide
Getting Started with Claude Code
Install Claude Code, configure your first project, and start shipping code with AI in under 5 minutes.
Getting StartedGuide
Writing Your First Claude Code Skill
A practical walk-through of how to design, write, and ship a Claude Code skill - from choosing when to trigger, through allowed-tools, to the steps the agent will actually follow.
Getting StartedRelated Videos

Anthropic's Cowork: Claude Code for the Rest of Your Work
In this video, we dive into Anthropic's newly launched Cowork, a user-friendly extension of Claude Code designed to streamline work for both developers and non-developers. This discussion includes an
Video·

Anthropic Claude Can Now Control Your Computer
Anthropic's Latest Breakthrough: Automating Computer Operations with Claude 3.5 Links: https://docs.anthropic.com/en/docs/build-with-claude/computer-use In this video, we explore Anthropic's...
Video·

Claude Mythos & Fable 5 Banned
Anthropic Suspends Fable 5 & Mythos 5 After US Export Control Directive (Jailbreak Concerns) Anthropic announced that the US government issued export control directives requiring it to suspend Fable ...
Video·
Related Posts
7 min read
Anthropic
Claude Mythos 5 Explained: What It Is, Who Can Access It, and Why It's Gated
Anthropic shipped two names for one architecture on June 9, 2026. Here is what separates Fable 5 from Mythos 5, who can...

7 min read
Claude
Claude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
Fable 5 launched June 9 at 2x GPT-5.5's price with a 22-point SWE-Bench Pro gap. Here is the decision framework for choo...

8 min read
Claude
Claude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
Fable 5 lists at $10/$50 per million tokens - twice Opus 4.8. But list price is the wrong number. Here is the cost-per-o...
9 min read
Claude
Migrating to Claude Fable 5: The Practical Guide
Fable 5 is mostly a drop-in replacement for Opus 4.8, but 'mostly' is doing real work in that sentence. Here's every bre...
7 min read
AI Safety
Fable 5's Hidden Guardrails: What Developers Need to Know About Silent Degradation
Anthropic's Claude Fable 5 includes undisclosed interventions that silently degrade responses for certain ML development...

7 min read
Claude
Claude Cookbook: Anthropic's Official Playbook for Building with Claude
Anthropic launched the Claude Cookbook - 80+ practical guides from their engineers covering tool use, agent patterns, ev...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever