Fable 5 Effort Levels Explained: low to xhigh, and What They Cost You
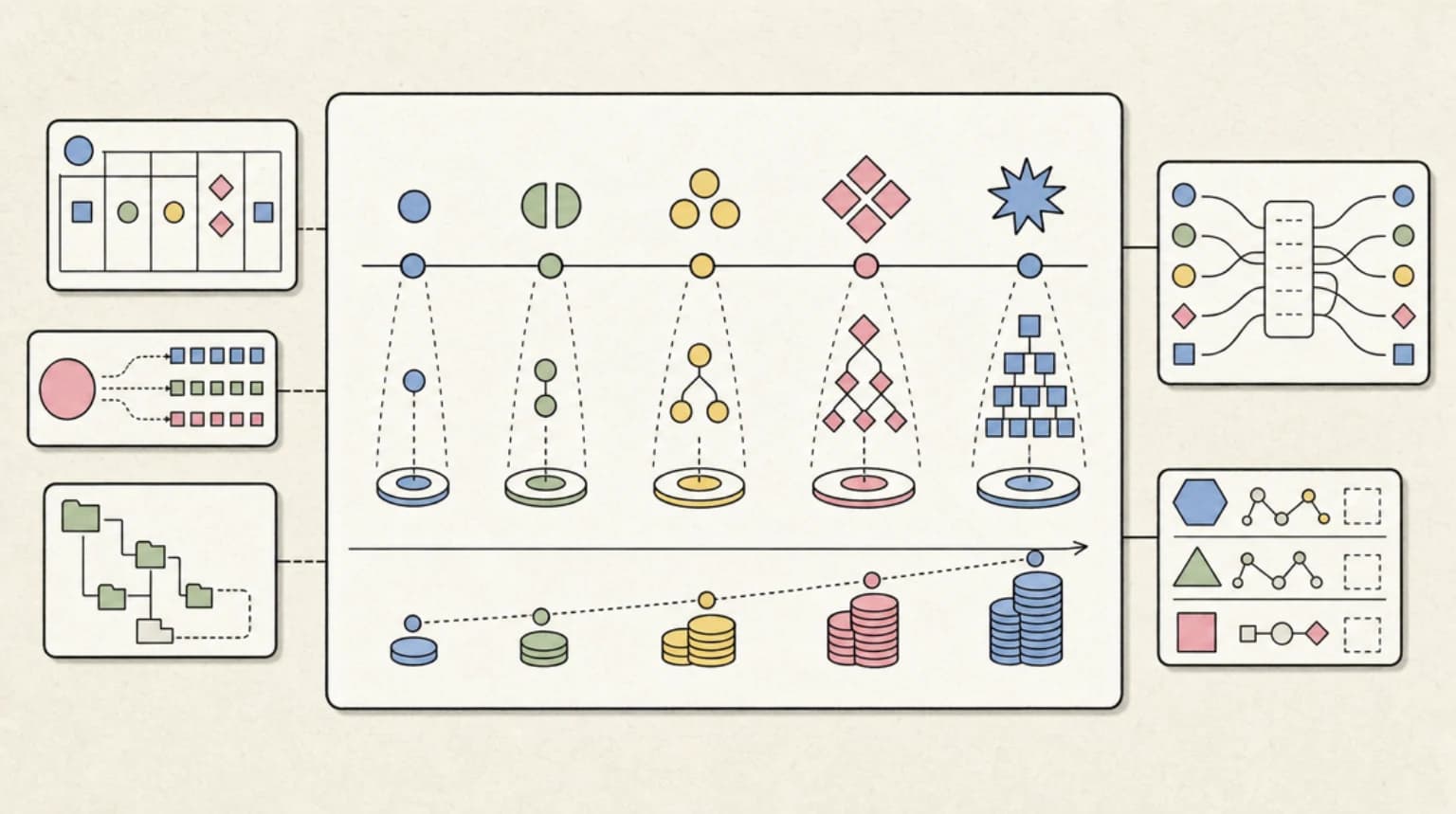
The Fable 5 Moment
31 parts- 1Claude Mythos 5 Explained: What It Is, Who Can Access It, and Why It's Gated
- 2Migrating to Claude Fable 5: The Practical Guide
- 3Fable 5 Leaves Your Claude Plan on June 22. Here's How to Plan for It
- 4Claude Fable 5 vs GPT-5.5: Benchmarks, Pricing, and When Each Wins
- 5Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
- 6Claude Fable 5 Pricing: Real Cost Per Task vs Opus 4.8, GPT-5.5 and Codex
- 7How to Model Fable 5 Costs Before They Blow Up Your Budget
- 8Claude Fable 5 API: Production Integration Patterns, Rate Limits, and Migration Gotchas
- 9Handling Fable 5 Refusals: A Working Guide to the Fallback API
- 10Why Fable 5 Refuses Your Cybersecurity Queries (And How the Fallback Works)
- 11Fable 5's Hidden Guardrails: What Developers Need to Know About Silent Degradation
- 12Fable 5 Broke Enterprise ZDR Agreements: What Dev Teams Must Do Now
- 13Claude Managed Agents: Dreaming, Outcomes, and Multi-Agent Orchestration Explained
- 14Claude Managed Agents Public Beta: What's Actually Available vs What's Gated
- 15Dario Amodei Wants FAA-Style AI Regulation: Open Questions for Developers
- 16The Exponential and the Working Developer: Sitting With Amodei's Hardest Questions
- 17The Dario Paradox: Warning About the Exponential While Shipping It
- 18The Pushback on Amodei's Exponential Essay: Too Slow, Too Convenient, or About Right?
- 19Fable 5 Before June 22: The Decision Checklist for Every Plan Tier
- 20Fable 5 on AWS Bedrock: When Your Data Leaves the AWS Boundary
- 21Why Claude Desktop Quietly Installs a 1.8 GB VM on Windows (And What You Can Do About It)
- 22Decoding Anthropic's Model Names: Fable, Mythos, and What the Naming Shift Signals
- 23Managed Agents vs LangGraph vs Rolling Your Own: Who Should Run Your Agent Loop in 2026
- 24How Claude's Usage Limits Actually Work With Fable 5: Windows, Multipliers, and Burn Rates
- 25Fable 5 for Government and Regulated Teams: The GovCloud Question
- 26Fable 5 vs DeepSeek V4: The Cost-Quality Gap Measured in Real Tasks
- 27The Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap Workers
- 28Prompt Caching Economics on Fable 5: When the 5-Minute TTL Pays
- 29Fable 5 with 1M Context: What Actually Works in Practice
- 30Fable 5 Effort Levels Explained: low to xhigh, and What They Cost YouCurrent
- 31Recursive Self-Improvement: What Fable 5, Dario's Essay, and Anthropic's Own Data Actually Tell Us
TL;DR
Fable 5 effort levels explained: what low, medium, high, xhigh, and max actually change, which models support each level, and how effort drives your token bill.
Last updated: June 11, 2026
Fable 5 took away most of the dials developers used to tune Claude. Thinking is always on, budget_tokens returns a 400, and the sampling parameters are gone entirely. What is left is one control that now does almost all the work: the effort parameter. The same dial drives Opus 4.8 and 4.7, and it surfaces in Claude Code as /effort. This guide covers what each level changes, which models accept which levels, and how to reason about cost - all verified against Anthropic's documentation on June 11, 2026.
What Effort Actually Controls#
Effort is set via output_config: {"effort": "..."} in the Messages API. It is GA on supported models with no beta header. Per Anthropic's effort documentation, the parameter affects all tokens in the response, not just thinking:
- Text responses and explanations
- Tool calls and function arguments
- Extended thinking (when enabled)
That last point is the key difference from the old budget_tokens approach, which only capped thinking. At lower effort, Claude makes fewer tool calls, combines operations into single calls, skips preamble, and confirms tersely. At higher effort, it makes more tool calls, explains its plan before acting, and writes more detailed summaries and code comments.
One important framing from the docs: effort is "a behavioral signal, not a strict token budget." At low, Claude will still think on genuinely hard problems - just less. If you need a hard ceiling, that is what max_tokens is for.
The Five Levels and Where They Run#
The API accepts exactly five values. These are the complete set - the docs state this explicitly, which matters because Claude Code's menu shows a sixth option (more on ultracode below).
| Level | What the docs say | Available on |
|---|---|---|
max | "Absolute maximum capability with no constraints on token spending" | Fable 5, Mythos 5, Opus 4.8, Opus 4.7, Opus 4.6, Sonnet 4.6, Mythos Preview |
xhigh | "Extended capability for long-horizon work" - agentic and coding tasks over 30 minutes "with token budgets in the millions" | Fable 5, Mythos 5, Opus 4.8, Opus 4.7 only |
high | The default. "Equivalent to not setting the parameter" | All effort-capable models |
medium | "Balanced approach with moderate token savings" | All effort-capable models |
low | "Most efficient. Significant token savings with some capability reduction" | All effort-capable models |
Effort is supported on Fable 5, Mythos 5, Opus 4.8, Opus 4.7, Opus 4.6, Sonnet 4.6, Opus 4.5, and Mythos Preview. Models not on that list (Sonnet 4.5, Haiku 4.5) do not support the parameter at all.
Two subtleties worth internalizing:
xhighis the exclusive club. Only Fable 5, Mythos 5, Opus 4.8, and Opus 4.7 have it. On Opus 4.6 and Sonnet 4.6 the ladder jumps fromhighstraight tomax.- The scale is calibrated per model. The Claude Code model configuration docs state that "the same level name does not represent the same underlying value across models." Do not port effort settings between models without re-testing.
Defaults Differ by Model and Surface#
The API default is high everywhere - omitting the parameter and setting "high" behave identically. Claude Code defaults differ per model:
| Model | API default | Claude Code default |
|---|---|---|
| Fable 5 | high | high |
| Opus 4.8 | high | high |
| Opus 4.7 | high | xhigh |
| Opus 4.6 / Sonnet 4.6 | high | high |
Claude Code also has fallback behavior: set a level the active model does not support and it falls back to the highest supported level at or below it. Set xhigh and switch to Opus 4.6, and you silently run at high. And when you first run Fable 5, Opus 4.8, or Opus 4.7, Claude Code applies that model's default effort even if you had set a different level for another model.
One more wrinkle: low through xhigh persist across Claude Code sessions, but max applies to the current session only (unless forced through the CLAUDE_CODE_EFFORT_LEVEL environment variable). Anthropic clearly does not want anyone accidentally living at max.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Handling Long-Running Fable 5 Requests: Timeouts, Streaming, and Background Patterns
Jun 11, 2026 • 8 min read
Setting Up the Memory Tool with Fable 5: Persistent Agents That Learn
Jun 11, 2026 • 8 min read
Prompt Caching Economics on Fable 5: When the 5-Minute TTL Pays
Jun 11, 2026 • 10 min read
Fable 5 Task Budgets: Capping Agent Spend Before It Happens
Jun 11, 2026 • 8 min read
How Effort Interacts with Thinking#
On Fable 5, thinking cannot be turned off - effort is the only depth control. On Opus 4.8 and 4.7, adaptive thinking is the only mode, and it is off unless you send thinking: {"type": "adaptive"}. The adaptive thinking docs describe how each effort level steers it:
max: Claude always thinks, with no constraints on depthxhigh: always thinks deeply, with extended explorationhigh: almost always thinksmedium: moderate thinking; may skip it for very simple querieslow: minimizes thinking; skips it where speed matters most
If you are coming from budget_tokens code, this mapping is your migration path - there is no 1:1 token conversion. The full migration checklist covers the other breaking changes that land alongside it.
What Each Level Costs You: the Math#
Here is the part pricing pages will not spell out for you: effort does not change the per-token rate. Fable 5 bills $10 per million input tokens and $50 per million output at every effort level; Opus 4.8 and 4.7 bill $5/$25, per the pricing page. The only documented price multipliers are caching, batch, fast mode, and data residency - effort is not on the list.
What effort changes is volume, almost entirely on the output side, because thinking tokens bill as output tokens even when you never see them (the default display on Fable 5 and Opus 4.8/4.7 is "omitted", which hides thinking text but bills it identically).
A worked illustration. Suppose an agentic task on Opus 4.8 sends 20,000 input tokens per turn. These output volumes are hypothetical, but the shape matches how the docs describe the levels:
| Scenario | Output tokens | Input cost | Output cost | Turn total |
|---|---|---|---|---|
low - terse, few tool calls | 5,000 | $0.10 | $0.125 | ~$0.23 |
high - thinks, plans, summarizes | 20,000 | $0.10 | $0.50 | ~$0.60 |
xhigh - extended exploration | 60,000 | $0.10 | $1.50 | ~$1.60 |
Same model, same prices, roughly 7x spread per turn purely from behavior. On Fable 5 double every number. Multiply by hundreds of turns in a long agent run and the effort setting is a bigger budget lever than the model choice in many cases - which is why effort deserves a row in any cost-per-task analysis you run.
Three practical cost notes, all from the docs:
- Measure, do not guess.
usage.output_tokens_details.thinking_tokensreports how many billed output tokens went to reasoning. Run the same eval at two effort levels and compare. - Give high effort room. At
xhighormax, Anthropic recommends startingmax_tokensat 64,000 - it is a hard ceiling on thinking plus response text. Seeingstop_reason: "max_tokens"means raise the ceiling or lower the effort. - The tokenizer compounds it. Opus 4.7 and later (including Fable 5) use a new tokenizer that can produce up to 35% more tokens for the same text, so old cost baselines do not transfer.
Counterintuitively, higher effort is sometimes the cheaper total: a run that finishes in one pass at xhigh can undercut three failed retries at medium. The Fable 5 vs Opus 4.8 decision guide works through that completion-rate math for model choice; the same logic applies at the effort dial.
Picking a Level per Task Type#
Synthesizing Anthropic's per-model recommendations:
On Fable 5: start at high (the default) for most work and reserve xhigh for the most capability-sensitive workloads. Anthropic's docs note that lower effort settings on Fable 5 "still perform well and often exceed xhigh performance on prior models" - a vendor claim, but a useful prior: do not assume Fable 5 needs the dial maxed. Step down to medium or low if tasks complete correctly but take longer than necessary.
On Opus 4.8 and 4.7: start with xhigh for coding and agentic work, treat high as the floor for anything intelligence-sensitive, and drop to medium only after evals confirm quality holds. The docs are blunt about max: on most workloads it "adds significant cost for relatively small quality gains" and it "can lead to overthinking" on structured-output tasks. Reserve it for genuinely frontier problems.
Everywhere: low is the documented home for subagents, classification, quick lookups, and high-volume latency-sensitive paths. If you orchestrate subagents, agent teams, or workflows, running workers at low while the orchestrator sits at high or xhigh is the cleanest cost win available.
Setting It: Claude Code and the API#
In Claude Code, the CLAUDE_CODE_EFFORT_LEVEL environment variable beats everything, then your configured level, then the model default. The mechanisms:
/effortopens an interactive slider;/effort xhighsets directly;/effort autoresets to the model default- Arrow keys adjust effort inside the
/modelpicker --effort <level>at launch, for a single sessioneffortLevelin settings (acceptslowthroughxhigh;maxandultracodeare session-only)effortin skill or subagent frontmatter, overriding the session level while that skill or subagent runs
About ultracode: it appears in the /effort menu but is not an API effort level. It sends xhigh to the model and additionally grants Claude Code standing permission to orchestrate dynamic workflows. Session-only, and deliberately excluded from the effortLevel setting and --effort flag. Related but different: typing ultrathink in a prompt requests deeper reasoning for that one turn via an in-context instruction - the effort level sent to the API is unchanged.
On the API, the syntax is one field:
Python
response = client.messages.create(
model="claude-fable-5",
max_tokens=64000,
output_config={"effort": "xhigh"},
messages=[{"role": "user", "content": "..."}],
)
On Opus 4.8 or 4.7, add thinking={"type": "adaptive"} if you want thinking; on Fable 5, omit the thinking parameter entirely (it is always on, and an explicit disabled returns a 400). If raw speed is the constraint rather than depth, see whether fast mode is worth it - fast mode changes price-per-token, effort changes token volume.
FAQ#
Is xhigh available on every Claude model?#
No. xhigh exists only on Fable 5, Mythos 5, Opus 4.8, and Opus 4.7. Opus 4.6 and Sonnet 4.6 support low, medium, high, and max but skip xhigh. In Claude Code, setting xhigh on an unsupported model silently falls back to high.
Does higher effort cost more per token?#
No. Per-token rates are fixed per model ($10/$50 for Fable 5, $5/$25 for Opus 4.8 and 4.7) and effort is not a pricing multiplier. Higher effort costs more because the model generates more tokens - more thinking (billed as output even when hidden), more tool calls, longer explanations. Check usage.output_tokens_details.thinking_tokens to see where the spend goes.
What is ultracode, and is it an API effort level?#
It is a Claude Code setting, not an API level. The API accepts exactly low, medium, high, xhigh, and max. Ultracode sends xhigh to the model and adds standing permission for Claude Code to launch multi-agent dynamic workflows. It applies to the current session only.
Should I run Fable 5 at xhigh by default?#
Anthropic says no - start at high, the default. Fable 5's lower effort levels are documented as often exceeding the xhigh performance of prior models, and blanket xhigh gets expensive fast. Move up only when a capability-sensitive task measurably benefits.
Sources#
- Effort parameter - Anthropic docs - levels, availability, defaults, tool-use behavior (accessed June 11, 2026)
- Adaptive thinking - Anthropic docs - effort-to-thinking mapping, billing of thinking tokens,
thinking_tokensusage field (accessed June 11, 2026) - Model configuration - Claude Code docs -
/effortcommand, per-model level tables, defaults, ultracode, ultrathink, fallback behavior (accessed June 11, 2026) - Pricing - Anthropic docs - per-model token rates, tokenizer note, pricing multipliers (accessed June 11, 2026)
- Claude Code What's New, Week 22 - Opus 4.8 default rollout and
/effort xhighguidance (accessed June 11, 2026)
Read next
Fable 5 with 1M Context: What Actually Works in Practice
Fable 5 1M context workflows that actually work: whole-repo reviews, log archaeology, multi-doc synthesis - plus the honest math on when RAG still wins.
10 min readThe Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap Workers
A practical playbook for running Claude Fable 5 as the orchestrator over Sonnet and Haiku workers, with verified cost math on when the premium pays off.
10 min readFable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
Fable 5 posts an 80.3% SWE-Bench Pro score and costs 2x Opus 4.8 - here is the task-profile scoring guide that tells you when the premium pays off.
7 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI ModelsDaily Driver
Claude
Anthropic's AI. Opus 4.6 for hard problems, Sonnet 4.6 for speed, Haiku 4.5 for cost. 200K context window. Best coding m...
View ToolAI Models
Claude Haiku 4.5
Anthropic's smallest Claude 4.5 model. Near-frontier coding performance at one-third the cost of Sonnet 4 and up to 4-5x...
View ToolAI Models
Claude Opus 4.7
Anthropic's flagship reasoning model. Best-in-class for coding, long-context analysis, and agentic workflows. 1M token c...
View ToolAI ModelsNew
Claude Fable 5
Anthropic's first generally available Mythos-class model, released June 9, 2026. 1M context, 128K max output, $10/$50 pe...
View ToolApps from Developers Digest
Related Guides
Guide
Effort Levels - Claude Code
Low, medium, high, xhigh, and max for adaptive reasoning control.
Claude CodeGuide
MCP Servers Explained
What MCP servers are, how they work, and how to build your own in 5 minutes.
AI AgentsGuide
Claude Code Complete Course
A complete, citation-backed Claude Code course with setup, prompting systems, MCP, CI, security, cost controls, and capstone workflows.
ai-developmentRelated Videos

Anthropic's Cowork: Claude Code for the Rest of Your Work
In this video, we dive into Anthropic's newly launched Cowork, a user-friendly extension of Claude Code designed to streamline work for both developers and non-developers. This discussion includes an
Video·

Anthropic Sonnet 4.5 in Claude Code in 10 Minutes
To learn for free on Brilliant, go to https://brilliant.org/DevelopersDigest/ . You’ll also get 20% off an annual premium subscription TOOLS I USE → Wispr Flow (voice-to-text): https://dub.sh/...
Video·

Anthropic Claude Code with Sonnet 3.7 in 15 Minutes
In this video, I demonstrate Claude Code, a tool by Anthropic currently in limited research preview. This enables developers to delegate tasks directly from the terminal. I walk through installatio...
Video·
Related Posts
8 min read
Anthropic
The Claude Tokenizer Change: What ~30% More Tokens Means for Your Bill
Anthropic's docs say the tokenizer introduced with Opus 4.7 can use up to 35% more tokens for the same text. Here is wha...
10 min read
AI Models
Fable 5 with 1M Context: What Actually Works in Practice
Fable 5 1M context workflows that actually work: whole-repo reviews, log archaeology, multi-doc synthesis - plus the hon...
10 min read
AI Agents
The Fable 5 Orchestrator Playbook: One Smart Model Managing Cheap Workers
A practical playbook for running Claude Fable 5 as the orchestrator over Sonnet and Haiku workers, with verified cost ma...
8 min read
AI Models
Is Claude Fable 5 Slow? Latency in Practice, and When It Matters
Claude Fable 5 latency measured: 109 seconds to first token at max effort vs 1.4s for Sonnet 4.6. When slow is fine, whe...
7 min read
AI Models
Fable 5 vs Opus 4.8: A Data-Driven Decision Guide for Engineering Teams
Fable 5 posts an 80.3% SWE-Bench Pro score and costs 2x Opus 4.8 - here is the task-profile scoring guide that tells you...
12 min read
Claude
Claude Opus 5: Near-Fable Intelligence at Half the Cost
Anthropic released Opus 5 on July 24, 2026 - same price as Opus 4.8, within 0.5% of Fable 5 on CursorBench, and the new...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever