Headroom: Compress Agent Tool Output Before It Reaches the LLM
TL;DR
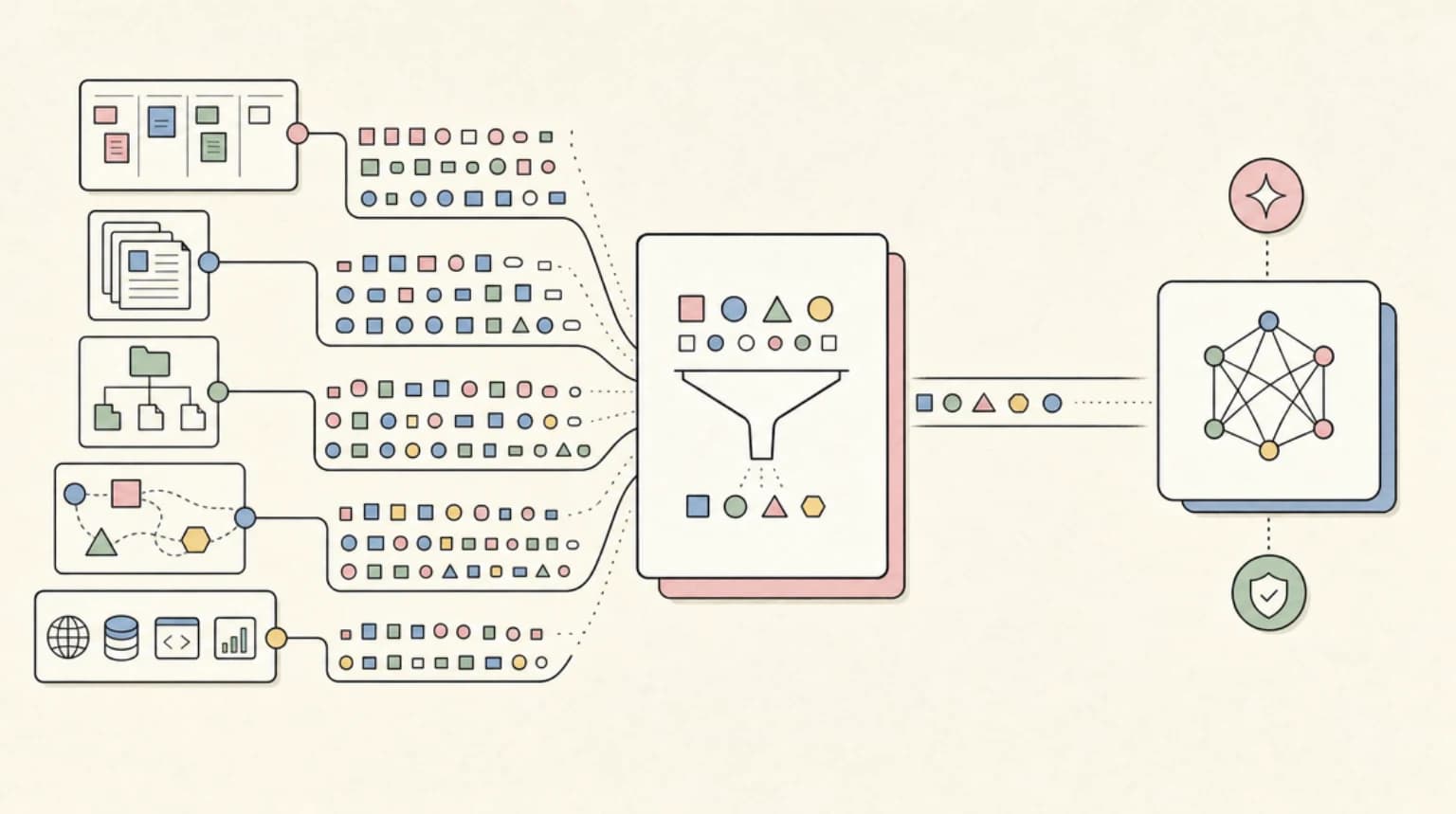
Headroom is a context compression layer that intercepts your AI agent's tool outputs and strips 60-95% of the tokens before they hit the model - with benchmarked accuracy preserved.
Headroom is a context compression layer for AI agents. It sits between tools and the model, compresses tool outputs, logs, files, RAG chunks, and conversation history, then passes a smaller version into the LLM.
Last updated: June 24, 2026
The project moved from chopratejas/headroom to headroomlabs-ai/headroom. The old repository redirects, but the current GitHub API source now reports roughly 49k stars, an Apache-2.0 license, and latest release v0.27.0 from June 22, 2026. PyPI also reports headroom-ai at 0.27.0.
That matters because the original Headroom story was not just "another trending repo." The durable story is that agent context management is becoming infrastructure. We have covered Claude Code token burn, harness engineering, and agent workspace contracts. Headroom fits that same category: it treats tokens as a systems budget, not as a prompt-writing annoyance.
What Headroom Does#
The current README describes Headroom as a local-first context optimization layer with several entry points:
- Library mode for Python or TypeScript apps
- Proxy mode through an OpenAI-compatible local proxy
- Agent wrap mode for tools like Claude Code, Codex, Cursor, Aider, Copilot CLI, and OpenCode
- MCP server mode with
headroom_compress,headroom_retrieve, andheadroom_stats - Cross-agent memory shared across agents
- Reversible compression through CCR, with originals cached locally for retrieval
The architecture is straightforward. Content flows through a router, then into a compression strategy suited to the content type:
- SmartCrusher for JSON-like tool outputs
- CodeCompressor for source code and AST-aware compression
- Kompress-base / Kompress-v2-base for general text
- CacheAligner for stable prompt prefixes and better cache reuse
- CCR for reversible retrieval when the model needs the original
That is a better mental model than "summarize everything." Good compression is selective. A JSON blob, a stack trace, a source file, and a conversation transcript do not need the same treatment.
The Benchmark Claim#
Headroom's README still leads with the claim that it can reduce token usage by 60-95% while preserving answers. The proof table lists real agent workloads:
| Workload | Before | After | Savings |
|---|---|---|---|
| Code search, 100 results | 17,765 | 1,408 | 92% |
| SRE incident debugging | 65,694 | 5,118 | 92% |
| GitHub issue triage | 54,174 | 14,761 | 73% |
| Codebase exploration | 78,502 | 41,254 | 47% |
The README also lists accuracy checks on GSM8K, TruthfulQA, SQuAD v2, and BFCL, with the standard benchmark rows showing no obvious collapse in answer quality.
I would still treat these as project-published benchmark claims, not independent lab results. But they are specific enough to evaluate. The repo gives a reproduce command for the eval suite, and the workload table is concrete. That is much better than a vague "save tokens with AI" landing page.
Newsletter
Get the weekly deep dive
Tutorials on Claude Code, AI agents, and dev tools, delivered free every week.
From the archive
Why This Matters For Coding Agents#
Coding agents waste context in predictable ways:
- Search tools return far more matches than the model needs.
- File reads include boilerplate and unrelated code.
- Logs include repeated prefixes and noisy timestamps.
- GitHub issue and PR payloads include metadata the model ignores.
- Tool call transcripts accumulate even after the useful decision has been made.
This is why context compression keeps showing up across the agent stack. It is not only about fitting into a context window. It is also about keeping attention on the parts of the transcript that matter.
For DevDigest readers, the most interesting Headroom lanes are:
- Claude Code sessions where long tool output causes context resets or expensive model calls
- Codex and OpenCode loops where terminal output can balloon quickly
- MCP-heavy workflows where structured JSON responses are verbose by default
- Internal agents that need cost controls before they can run continuously
- SRE and debugging agents that chew through logs
That lines up with the broader argument in terminal agents as portable runtimes: once agents can run tools, the transcript becomes an execution artifact. Headroom is trying to optimize that artifact before it becomes expensive.
MCP Is The Sharp Edge#
The MCP mode is the part I would test first.
MCP servers are useful because they standardize tool access, but many tool responses are intentionally verbose. That is reasonable for correctness and debugging, but it is wasteful when every response flows into an expensive model context.
Headroom's MCP server gives clients three primitives:
headroom_compressheadroom_retrieveheadroom_stats
That creates a cleaner pattern than asking every MCP server author to hand-optimize output fields. Let servers return complete structured data, then place a compression layer between the server and model when the agent only needs a smaller representation.
This connects directly to the MCP server guide, best MCP servers list, and MCP zero-touch OAuth. As the ecosystem grows, response hygiene becomes a platform problem.
Install And Try It#
The current README and PyPI metadata agree on Python 3.10+.
Terminal
pip install "headroom-ai[all]"
For TypeScript or Node:
Install
npm install headroom-aiTo try it as an agent wrapper:
Terminal
headroom wrap claude
headroom wrap codex
headroom wrap opencode
To try proxy mode:
Terminal
headroom proxy --port 8787
The right test is not only "does it start?" A useful evaluation should measure:
- Token reduction on a real workflow.
- Whether the agent still solves the task.
- Whether
headroom_retrievecan recover originals when needed. - How much local state CCR writes.
- Whether logs are clear enough for review.
If it saves tokens but makes debugging harder, it is not a free win.
What To Watch#
Headroom is powerful, but it changes the shape of your agent pipeline.
The upside is lower context cost, longer useful sessions, and a reusable compression layer across agents. The tradeoff is another local process, another cache/store, and another component that can hide detail if configured poorly.
For individual developers, that tradeoff is probably fine. For teams, the operational questions are sharper:
- Where are originals stored?
- How long does CCR retain them?
- Can sensitive data be compressed, cached, or retrieved safely?
- Does the proxy preserve enough observability?
- Are savings measured or estimated?
- What happens when compression is wrong?
The current README is refreshingly direct about measured versus estimated output-token savings, including confidence bands and optional holdout traffic. That is the right direction. Token savings should be treated like performance metrics, not vibes.
The Takeaway#
Headroom is worth watching because it turns a common agent pain point into an infrastructure layer. The category is real: agents need context budgets, cache discipline, retrieval paths, and transcript hygiene.
The best version of Headroom is not "make prompts shorter." It is "make agent execution cheaper and more reviewable without losing the original evidence."
That is exactly where agent tooling needs to go.
FAQ#
What is Headroom?#
Headroom is a local-first context compression layer for AI agents and LLM applications. It can run as a library, proxy, MCP server, or agent wrapper, compressing tool outputs and other context before they reach the model.
How much can Headroom reduce token usage?#
The current README claims 60-95% fewer tokens and lists workload examples ranging from 47% to 92% savings. Treat those as project-published benchmark claims and test them on your own workflows before relying on the number.
Does Headroom work with Claude Code and Codex?#
The README lists headroom wrap support for Claude Code, Codex, Cursor, Aider, Copilot CLI, OpenCode, and other clients. Any OpenAI-compatible client can also use the proxy mode.
Is Headroom safe for production agents?#
It depends on your data controls. Headroom can improve token cost and context hygiene, but teams should review local storage, CCR retention, credential handling, logs, and retrieval behavior before using it in production workflows.
Sources#
Read next
Goose: The Open Source AI Agent With 70+ MCP Extensions
Goose is a Rust-built AI agent with a CLI, desktop app, and API that runs against 15+ LLM providers and extends through 70+ MCP extensions - here is why developers are installing it.
8 min readDeepSeek-TUI: The Rust Terminal Coding Agent With MCP, Skills, and 1M-Token Context
DeepSeek-TUI is a Rust-built terminal coding agent wrapping the DeepSeek V4 API with full tool use, MCP server support, a composable skills system, and three operational modes for different risk tolerances.
6 min readSWE-Pruner Pro Makes Tool Output Pruning an Agent Runtime Problem
SWE-Pruner Pro points at a practical coding-agent design shift: do not only compress prompts outside the model. Teach the runtime to prune tool outputs before they become the next turn's context.
8 min readShare
Suggest an editSave
Developers Digest
Technical content at the intersection of AI and development. Building with AI agents, Claude Code, and modern dev tools - then showing you exactly how it works.
300+ videos30K+ GitHub stars50+ articles
Related Tools
AI Frameworks
Composio
Gives AI agents access to 250+ external tools (GitHub, Slack, Gmail, databases) with managed OAuth. Handles the auth and...
View ToolAI Frameworks
OpenAI Agents SDK
Lightweight Python framework for multi-agent systems. Agent handoffs, tool use, guardrails, tracing. Successor to the ex...
View ToolAI Frameworks
A
Agency Swarm
Multi-agent orchestration framework built on the OpenAI Agents SDK. Define agent roles, typed tools, and directional com...
View ToolProductivityNew
A
AgentCanvas
A hosted infinite canvas your headless AI agents drive over MCP. Any MCP-speaking agent - Claude Code, Codex, Cursor, or...
View ToolApps from Developers Digest
Developer ToolsPlus $20/mo
Cost Tape Cloud
Know what each agent run cost before the bill arrives. Budgets and alerts included.
View AppDeveloper ToolsIn Progress
MCP Lens
Replay every MCP tool call to find why your agent went sideways.
View AppDeveloper ToolsIn Progress
Browser Flow Design
Plan browser automation flows as inspectable product journeys before agents run them.
View AppRelated Guides
Guide
Building Your First MCP Server
Step-by-step guide to building an MCP server in TypeScript - from project setup to tool definitions, resource handling, testing, and deployment.
AI AgentsGuide
Subagent Frontmatter - Claude Code
Configure model, tools, MCP, skills, memory, and scoping.
Claude CodeGuide
Claude Code Setup Guide
Configure Claude Code for maximum productivity -- CLAUDE.md, sub-agents, MCP servers, and autonomous workflows.
AI AgentsRelated Videos

Agents 101: How to Build and Deploy Anything with AI Agents
Build Anything with Vercel, the Agentic Infrastructure Stack Check out Vercel: https://vercel.plug.dev/cwBLgfW The video shows a behind-the-scenes walkthrough of how the creator rapidly builds and d...
Video·

TRAE: Custom AI Agents That Actually Understand Your Codebase
Check out Trae here! https://tinyurl.com/2f8rw4vm In this video, we dive into @Trae_ai a newly launched AI IDE packed with innovative features. I provide a comprehensive demonstration...
Video·

Introducing Augment Remote Agent: Parallel Autonomous AI Agents
Boost Your Productivity with Augment Code's Remote Agent Feature Sign up: https://www.augment.new/ In this video, learn how to utilize Augment Code's new remote agent feature within your...
Video·
Related Posts
6 min read
Trending
CLI-Anything Turns Any Software Into an Agent-Ready Command Line
HKUDS/CLI-Anything hit 40,000 stars by solving a stubborn gap: most desktop software has no interface AI agents can reli...

8 min read
AI Agents
AI Agent Auth Platforms Compared: Arcade vs Composio vs Nango vs Stytch
A practical comparison of the four authentication platforms developers reach for when connecting AI agents to third-part...

8 min read
AI Agents
DataFlow-Harness Shows Why Agents Need Editable Pipelines
The DataFlow-Harness paper is a useful reminder that coding agents should not just emit scripts. For data work, the dura...

6 min read
AgentCanvas
AgentCanvas is a visual adapter for Claude Code and Codex
Claude Code and Codex both ship great agents and terrible transcripts. AgentCanvas is a visual adapter that puts the art...

5 min read
MCP
MCP tools need a shared board, not another transcript
MCP makes tools callable by agents. That solves invocation. It does not solve visibility. The next agent and the next hu...

9 min read
Agent Skills
Agent Studio: Authoring the Roles, Not Just the Knowledge
Skills gave an agent what to know. The missing half is what role to play. Agent Studio lets you author subagents next to...
Build with the member tools

Get Smarter About AI Dev
New tutorials, open-source projects, and deep dives on coding agents - delivered weekly.
One email per weekReal code, not theoryFree forever